







shell中的通配符

shell里的? 通配一个任意字符
[root@lier 701]# mkdir zhaosiyuan{1..20}
[root@lier 701]# ls
mail.txt zhaosiyuan12 zhaosiyuan18 zhaosiyuan5
name.txt zhaosiyuan13 zhaosiyuan19 zhaosiyuan6
sc.html zhaosiyuan14 zhaosiyuan2 zhaosiyuan7
zhaosiyuan1 zhaosiyuan15 zhaosiyuan20 zhaosiyuan8
zhaosiyuan10 zhaosiyuan16 zhaosiyuan3 zhaosiyuan9
zhaosiyuan11 zhaosiyuan17 zhaosiyuan4
# 删除zhaosiyuan后面有一个字符的文件,即删除了zhaosiyuan{1..9}
[root@lier 701]# rm -rf zhaosiyuan?
[root@lier 701]# ls
mail.txt zhaosiyuan12 zhaosiyuan17
name.txt zhaosiyuan13 zhaosiyuan18
sc.html zhaosiyuan14 zhaosiyuan19
zhaosiyuan10 zhaosiyuan15 zhaosiyuan20
zhaosiyuan11 zhaosiyuan16
# 删除zhaosiyuan后面有两个字符的文件,即删除了zhaosiyuan{10..20}
[root@lier 701]# rm -rf zhaosiyuan??
[root@lier 701]# ls
mail.txt name.txt sc.html
*代表任意个任意字符
[root@lier 701]# mkdir zhaosiyuan{1..20}
[root@lier 701]# ls
mail.txt zhaosiyuan12 zhaosiyuan18 zhaosiyuan5
name.txt zhaosiyuan13 zhaosiyuan19 zhaosiyuan6
sc.html zhaosiyuan14 zhaosiyuan2 zhaosiyuan7
zhaosiyuan1 zhaosiyuan15 zhaosiyuan20 zhaosiyuan8
zhaosiyuan10 zhaosiyuan16 zhaosiyuan3 zhaosiyuan9
zhaosiyuan11 zhaosiyuan17 zhaosiyuan4
# 删除zhaosiyuan后面有任意个字符的文件,即删除了zhaosiyuan{1..20}
[root@lier 701]# rm -rf zhaosiyuan*
[root@lier 701]# ls
mail.txt name.txt sc.html
正则表达式
egrep 、sed、awk和正则有什么联系呢?
正则表达式 regular expression
regular 常规,规则的
expression 表达式 、公式 --》一套方法,里面有特殊字符,字母,数字组合—》表达某个意思
方法–》一个轮子grep–》查找 --》采用这套方法
import re
sed --》替换
awk --》截取
正则是一套方法,而egrep、sed、awk都是可以使用这套方法的命令
示例:
查找出网页中的所有图片
curl 是linux里字符界面的浏览器(http,https,ftp等)
重定向到文件–》保存屏幕上输出的内容到文件里
追加输出重定向,不覆盖原来文件里的内容
图片: .jpg .png .gif 等
总结图片的共性问题–》图片以.jpg .png .gif 结尾
“.jpg|.png|.gif”
使用公式表达出图片的共性特点
从海量的文本里查找我们需要的图片
[root@localhost lianxi]# curl https://www.sanchuangedu.cn >sc.html
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1017 100 1017 0 0 3649 0 --:--:-- --:--:-- --:--:-- 3658
[root@localhost lianxi]# cat sc.html |egrep ".jpg|.png|.gif"
<img src=wgyc.png width="400" >
<img src=luogan.png width="400" >
<img src=xiayuzhen.jpg width="400" >
写正则表达式就是找规律和共性问题
什么是正则?
一些特殊符号+字符+数字组合成一个表达式,用来表示某个意思、特定含义
使用一些特殊符号+字母和数字按照某个规则组合成一个公式用来表示某个意思这就叫正则表达式junjie*
junjie?
^junjie+
^junjie{2,4}
wang$按照某种正常的规则表达出某个含义(意思)的公式
正则表达式里规定很多特殊符号有特殊的含义和作用
正则表达式是一种方法,
很多命令可以采用这种方法,例如vim、grep、sed、awk等命令都支持正则表达式。

元字符:有特殊作用的字符,能描述其他字符的字符
^ 表示以什么开头
$ 表示以什么结尾
? 表示前面的字符串出现0或者1次+表示前面的字符串出现1次以上
*表示前面的字符串出现0次或者任意次
| 或者
正则用在哪里?
查找的场景特别适合使用正则
vim 、grep、sed、awk等命令
为什么需要使用它?
查找的场景特别适合使用正则,大海捞针,海选
* 表示前面的字符出现0次或者任意次
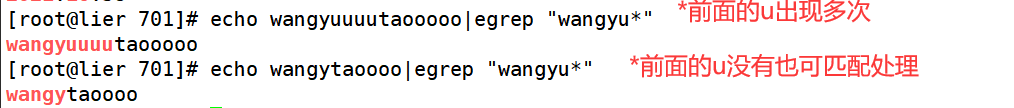
grep


grep选项
-i 不区分大小写 -i, --ignore-case
-o 只是显示匹配的内容 only-match
-n 显示行号 line-number
-v invert-match 取反
-A after 在什么之后
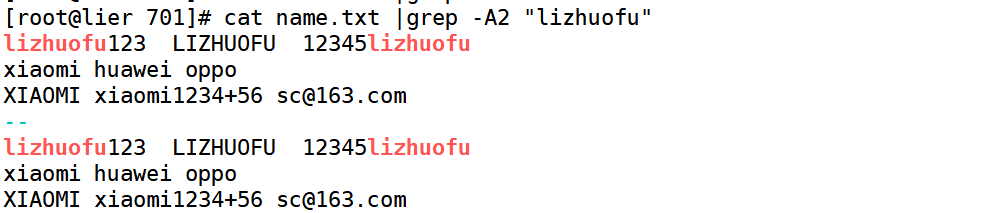
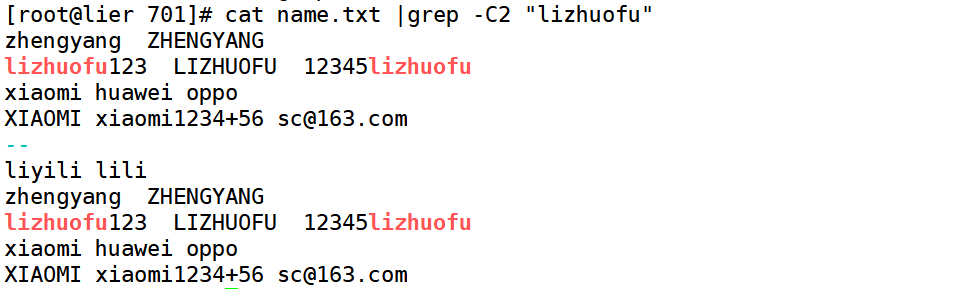
-B before 在什么以前matching lines. -C center(中心) context上下文
示例
[root@lier 701]# cat name.txt
zhengyang ZHENGYANG
lizhuofu123 LIZHUOFU 12345lizhuofu
xiaomi huawei oppo
XIAOMI xiaomi1234+56 sc@163.com
wenke wenkeke
wanglianfang fangfang
liyili lili
zhengyang ZHENGYANG
lizhuofu123 LIZHUOFU 12345lizhuofu
xiaomi huawei oppo
XIAOMI xiaomi1234+56 sc@163.com
wenke wenkeke
wanglianfang fangfang
liyili lili
zhaojunjie
shenjiemi
shenjiemi lijunlin
1
2
3
4
shenjiedami shenxiaomi
-o
只显示匹配内容

-B
打印匹配到的字符的前NUM行
-B NUM, --before-context=NUM
Print NUM lines of leading context before

-A
打印匹配到的字符的后NUM行
-A NUM, --after-context=NUM
Print NUM lines of trailing context after matching
lines.
-C
打印匹配到的字符的前后NUM行
-r
递归查找

-v
取不包括指定匹配的行
打印出除空行外的内容
[root@lier 701]# cat name.txt | egrep "^$" -n -v
egrep
egrep = grep -E
grep命令支持扩展正则
1.基本正则
元字符: * . ^ $
2.扩展正则
元字符: | + ? {}
grep和egrep的区别
扩展正则支持更加多的元字符,能够表示更加复杂的意思,功能更加强大
-E, --extended-regexp
Interpret PATTERN as an extended regular expression (ERE, see below).




^$ 匹配出空行
-n 显示行号
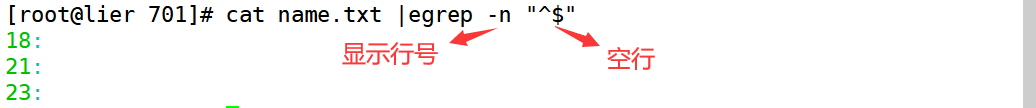

.代表单个任意字符

.* 表示任意个任意字符,即任意字符
表示shen字符串后面出现任意个任意字符


{n} 表示n个前面的字符

表示shen字符串后面出现4到6个任意字符
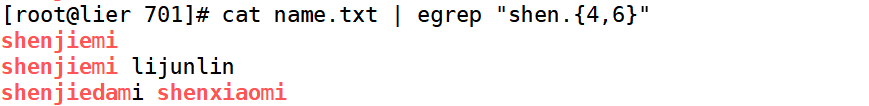

[abc] 取中括号里的一个字符,可以是a也可以是b,也可以是c
“a|b|c”
\s 空白、空格、tab、回车符



打印出/etc/ssh/sshd_config文件中的有效行,即不包括注释行和空行
[root@localhost lianxi]# cat /etc/ssh/sshd_config |egrep -v "^#|^$"
查找不是以数字开头的行
[root@localhost lianxi]# cat name.txt |egrep "^[^0-9]"
[^0-9] 非数字
[0-9] 不是以数字开头的行
里面的^表示取反
外面的^表示以什么开头
单词的定界符号
< 和 \b 表示单词以什么开头
<san 单词以san开头
sanchuang sanyi sanhuan sansiwu<sanchuang> 等同于 \bsanchuang\b
<sanchuang 等同于\bsanchuang
sanchuang> 等同于 sanchuang\b
查找文本里单词的长度是13个字符的字符串
grep “\b[a-Z]{13}”
hekunhonghong
查找文本里单词的长度是12~16个字符的字符串
[root@localhost lianxi]# echo sanchuang sanyi sanhuan sansiwu abcd|egrep "\<sanchuang\>"
[root@localhost lianxi]# echo sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd|egrep "\<sanchuang\>"
sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd
[root@localhost lianxi]# echo sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd|egrep "sanchuang"
sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd
[root@localhost lianxi]#
[root@localhost lianxi]# echo sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd|egrep "sanchuang"
sanchuang sanchuangtongle sanyi sanhuan sansiwu abcd
[root@localhost lianxi]#


转义元字符
[root@localhost lianxi]# echo 'abce$#!'|egrep "\\$"
练习:从文本里过滤出所有邮箱地址
邮箱: 特点: 共性问题
格式:字符串1@字符串2.字符串3
695811769@qq.com
fengdeyong123@163.com
fengdeyong_123@164.cn字符串1: a-Z _ 0-9
字符串2: a-Z 0-9
字符串3: a-Z[0-z_]+@[0-z]+.[a-z]+
[root@lier 701]# cat mail.txt
wang sheng hu 8898989@qq.com alfdaf
fengdeyong@sina.com fjdkfjd
zhao zhao@163.com
yishiying_1213@163.com afdaskdlas
15、写一个表示邮箱的正则
feng@qq.com
1234feng@163.com
meng.xianhui@yahoo.cn
liudehua@sina.com
10001@qq.com
123_ui@12306.cn
qilu@qilu.edu
qilu@qilu.edu/fjdkfjk/fjdk

对过滤出的文本进行排序去重
[root@lier 701]# cat mail.txt |egrep -o "[0-z_.]+@[0-z]+\.[a-z]+"|sort|uniq
10001@qq.com
1234feng@163.com
123_ui@12306.cn
8898989@qq.com
fengdeyong@sina.com
feng@qq.com
liudehua@sina.com
meng.xianhui@yahoo.cn
qilu@qilu.edu
yishiying_1213@163.com
zhao@163.com
sort
sort 排序:默认情况下根据一行里的第1个字母的ASCII码值进行比较,升序排列
如果第1个字符一样,再比较第2个,以此类推
-n 进行数值的比较,默认升序
-k 指定列排序
-r 排序是降序
sort的分隔符是空白(空格和tab),多个空白都算一个分隔符
-n, --numeric-sort
compare according to string numerical value
-r, --reverse
reverse the result of comparisons
-t, --field-separator=SEP 指定分隔符
field 字段,列
use SEP instead of non-blank to blank transition
-k, --key=KEYDEF
sort via a key; KEYDEF gives location and type
[root@lier 701]# cat grade.txt
id name chinese english math
1 cali 82 80 80
2 tom 96 90 70
3 jarry 72 100 90
11 cali 85 80 80
12 tom 93 90 70
13 jarry 71 100 90
[root@localhost lianxi]# cat grade.txt |sort -k 4 -n -r|head -3
3 jarry 70 100 90
13 jarry 70 100 90
2 tom 90 90 70
uniq
uniq 去重,去除重复的行 unique 唯一
默认情况下,只能去除连续的重复行,所以sort和uniq一般同时出现
-c 统计重复的次数 count
[root@localhost lianxi]# cat test.txt |sort|uniq -c|sort -nr|head -3
20 yibangyou
6 wuyangming
5 liqiang
使用正则查找出IP地址
IP地址是干什么使用的?作用?
标识: 每台机器的一个id,通信地址,方便其他的电脑找到你的
公网 ip :全球范围内唯一
私网 ip: 192.168.. ,在局域网里唯一云服务器: 私网 公网
A类地址范围:1.0.0.1~126.225.255.254。
B类地址范围:128.0.0.1~191.255.255.254。
C类地址范围:192.0.0.1~223.255.255.254。
D类地址范围:224.0.0.0~239.255.255.255。
E类地址范围:240.0.0.0~247.255.255.255。
127.0.0.0到127.255.255.255是保留地址,用做循环测试用的 。比如在本地做web开发时会用到。
A类的10.0.0.0~10.255.255.255、B类的172.16.0.0~172.31.255.255、C类的192.168.0.0~192.168.255.255为私网IP。除此之外,A、B、C三类的所有其余IP都是公网IP。私网IP只会出现在私网内,公网IP只会出现在公网内。
为什么需要写ip地址的正则?对日志做分析
IPV4: 32位二进制表示
ip version 4 2^32 42亿
10进制数192.168.0.1
4段 0~255
8位二进制数 2^8
IPV6: ip version 6 128位: 机房: ipv4 ipv6
ipv4 IP地址类型:
A:1~126
B:128~191
C:192~223
公网上使用的是ABC D:组播地址
E:保留A类ip地址的格式:
第1段:1~126
第24段:0255
查找出A类的IP地址
思路:
第一个字段:
1位数字:1-9
2位数字:10-99
3位数字:100~119 120~126
[1-9]|[1-9][0-9]|1[01][0-9]|12[0-6]第二、三、四字段:
0~255
1位数字:0-9
2位数字:10~99
3位数字:100~199 200~249 250~255
[0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5]组合:
([1-9]|[1-9][0-9]|1[01][0-9]|12[0-6])(\.([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])){3}
root@aliyun-sz:/usr/local/sclilin99/logs# head -1000 access.log |egrep "\b([1-9]|[1-9][0-9]|1[01][0-9]|12[0-6])(\.([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])){3}\b"
编写一个B类ip地址的正则
B:128~191
分析:
128~129 130~189 190~191
[root@lier 704]# egrep "(12[89]|1[3-8][0-9]|19[01])(\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}" ip.txt
153.121.32.1
189.56.32.13
简单的ip地址正则
分析:4段:0~255
[root@lier 704]# egrep "\b([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}\b" ip.txt
192.168.2.1
102.234.12.134
234.123.56.23
212.34.124.6
153.121.32.1
189.56.32.13
[root@localhost ~]# netstat -anplut
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 27561/nginx: master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 13612/sshd
tcp 0 0 192.168.141.143:40440 39.155.141.16:80 TIME_WAIT -
tcp 0 0 192.168.141.143:47456 202.141.160.110:80 TIME_WAIT -
tcp 0 0 192.168.141.143:49498 3.125.197.172:80 TIME_WAIT -
tcp 0 0 192.168.141.143:49492 3.125.197.172:80 TIME_WAIT -
tcp 0 36 192.168.141.143:22 192.168.141.1:49750 ESTABLISHED 29742/sshd: root@pt
tcp 0 0 192.168.141.143:47454 202.141.160.110:80 TIME_WAIT -
tcp6 0 0 :::22 :::* LISTEN 13612/sshd
udp 0 0 0.0.0.0:68 0.0.0.0:* 13501/dhclient
[root@localhost ~]#
[root@localhost ~]# netstat -anplut|egrep "\b([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])(\.([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])){3}\b" -o|sort|uniq
0.0.0.0
192.168.141.1
192.168.141.143
如何得到一个变量的字符串的长度?
[root@localhost ~]# sg="luoyaweichidao"
[root@localhost ~]# echo ${#sg}
14
[root@localhost ~]# echo $sg|wc -L
14
[root@localhost ~]#
使用正则判断密码复杂度
[root@localhost ~]# sg="luoyaweichidao"
# 判断是否包含大写字母
[root@localhost ~]# echo $sg|egrep "[A-Z]"
# 判断是否包含小写字母
[root@localhost ~]# echo $sg|egrep "[a-z]"
luoyaweichidao
[root@localhost ~]# echo $?
0
# 判断是否包含特殊字符
[root@localhost ~]# echo $sg|egrep "[^0-Z]"
[root@localhost ~]# echo $?
1
[root@localhost ~]# sg="liuchangCHIDAO123#^"
# 判断变量中是否包含大小写字母和特殊字符
[root@localhost ~]# echo $sg|egrep "[a-z]"|egrep "[A-Z]"|egrep "[^0-Z]"
liuchangCHIDAO123#^
编写一个脚本判断用户输入的密码是否满足密码复杂性要求
1.长度 >10位
2.大小写
3.特殊字符
4.数字
位置变量
egrep
变量的长度
if
[root@lier 704]# cat passwd.sh
#########################################################################
# File Name: passwd.sh
# Description: passwd.sh
# Author: lwq
# Created Time: 2022-07-04 15:10:09
#########################################################################
#!/bin/bash
# 判断密码(传入的位置变量$1)长度
if (( ${#1} >= 10 ));then
echo "密码长度符合要求"
else
echo "密码长度小于10位,请重新输入符合要求的密码!"
# 退出脚本,不再执行下面的命令
exit
fi
# 判断密码是否包含数字、大小写字母、特殊符号
if echo $1|egrep "[a-z]"|egrep "[A-Z]"|egrep "[^0-Z]";then
echo "密码满足复杂性要求"
else
echo "密码没有满足复杂性要求,请重新输入符合要求的密码!"
fi
测试脚本
[root@localhost 74]# bash passwd.sh yaolifan123
密码长度符合要求
密码没有满足复杂性要求,请重新输入密码
[root@localhost 74]# bash passwd.sh yaolifanA123
密码长度符合要求
密码没有满足复杂性要求,请重新输入密码
[root@localhost 74]# bash passwd.sh yaolifanA123^
密码长度符合要求
yaolifanA123^
密码满足复杂性要求
[root@localhost 74]#















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









