







 本文详细介绍了Pandas库中的DataFrame数据结构,包括其概念、创建方式(列表、字典和numpy数组),以及关键属性如shape、columns和index的使用。此外,还涵盖了索引元素访问、数据清理、排序、随机抽样和数据合并等实用功能。
本文详细介绍了Pandas库中的DataFrame数据结构,包括其概念、创建方式(列表、字典和numpy数组),以及关键属性如shape、columns和index的使用。此外,还涵盖了索引元素访问、数据清理、排序、随机抽样和数据合并等实用功能。
DataFrame是pandas中常用的数据结构,并且在数据分析中使用非常方便、简洁,总结如下。
1、介绍DataFrame
DataFrame是pandas中的表格型数据结构,可以理解为xlsx中的表格;它含N个有序的列,每一列可以是不同的值类型(数值、字符串、布尔型值),也可以理解为由Series组成的字典(Series是padas中一种基础数据结构,理解为表格中的一列);此外DataFrame是一个二维的数据结构,也可以看成是二维的数据,结构如图所示(图片来源菜鸟教程):
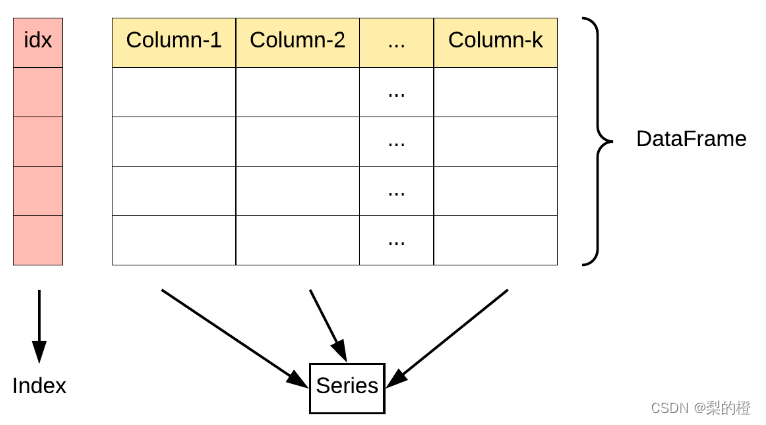
其中
Index:表示索引值,就是行标签,默认值为0,1,2....;
Column-i;表示列标签,默认值为0,1,2...
2、如何创建DataFrame
首先需要了解pd.DataFrame( data, index, columns, dtype, copy)构造方法
-
data:一组数据(list, dict, ndarray, series等类型)。
-
index:用于指定行标签。
-
columns:用于指定列标签 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
1)通过列表创建
指定行标签
import pandas as pd
def main():
data = [[1, 2, 3], ['Google', 'Meta', 'Apple']]
index = ['idx', 'name']
df = pd.DataFrame(data, index=index)
print(df)指定列标签
import pandas as pd
def main():
data = [['Google', 1], ['Meta', 2], ['Apple', 3]]
col = ['name', 'id']
df = pd.DataFrame(data, columns=col)
print(df)2)通过字典创建
字典的key对应表格的列名,value对应每个列中存在的值。
import pandas as pd
def main():
data = {'name': ['Google', 'Meta'], 'idx': [1, 2]}
df = pd.DataFrame(data)
print(df)3)使用numpy中数组来创建
numpy中数组就是类似的二维数组,可以使用行标签指定,也可以使用列标签指定
import pandas as pd
import numpy as np
def main():
ndarray_data = np.array([
['Google', 1],
['Meta', 2],
['Apple', 3]
])
idx = [0, 1, 2]
df = pd.DataFrame(ndarray_data, index=idx)
print(df)3、DataFrame的属性
1) df.shape
用于返回 DataFrame对象 的维度信息(形状),即行数和列数。返回包含行数和列数的元组。
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
# 使用 df.shape 获取 DataFrame 的维度信息
shape = df.shape
# 打印结果
print("DataFrame 的维度信息:", shape) # (3,3)
2)df.columns 用于获取列名 3)df.index 用于获取索引 4、DataFrame索引元素方式 Pandas 使用 loc 属性返回指定行和列的数据,从0开始计数 1)指定行号和列号访问元素
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
# 选择第二行第三列的元素
element = df.iloc[1, 2]
# 打印结果
print(element)2)使用切片,选择连续的多行或多列数据
import pandas as pd
def main():
data = {'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
target = df.iloc[:2, :2]
print(target)3)使用列表,选择多行或多列数据
import pandas as pd
def main():
data = {'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
target = df.iloc[[0, 2], [1, 2]]
print(target)
main()4)使用列索引名称来,获取数据
import pandas as pd
def main():
data = {'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
target = df.iloc[0]['A']
print(target)5、常用的一些函数 1)df.dropna() 用于删除表格中包含缺失值的行 df.dropna(axis=1) 用于删除表格中指定列中包含缺失值的行 2)df.fillna(value=0, inplace=True) 对于DataFrame中缺失的值,还可以根据值进行填充 3)df.sort_values(by='column_name', ascending=True) 根据指定的列名排序表格,默认为升序排序
import pandas as pd
def main():
data = {'A': [1, 2, 3],
'B': [7, 3, 1],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
target = df.sort_values(by='B')
print(target)
main()4)df.sample() 用于从DataFrame中随机抽取样本。默认情况,可以返回指定数量的随机样本的DataFrame。
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': ['a', 'b', 'c', 'd', 'e']}
df = pd.DataFrame(data)
# 从 DataFrame 中随机抽取两个样本
sample = df.sample(n=2)
# 打印结果
print(sample)
df.sample() 方法还支持其他参数,例如 frac(指定要抽取的样本占原始数据的比例)、replace(是否允许重复抽样)。
5)pd.concat()
Pandas中用于合并数据的函数,可以沿着指定的轴将多个DataFrame或者Series对象连接起来。
沿着行进行数据合并,因此合并的两个对象在Series上一致。
import pandas as pd
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [7, 8, 9],
'B': [10, 11, 12]})
# 使用 pd.concat() 连接两个 DataFrame,并为每个 DataFrame 添加一个层次化索引
result = pd.concat([df1, df2], keys=['df1', 'df2'])
# 打印结果
print(result)
沿着列进行合并,因此合并的两个对象在行数上一致。
import pandas as pd
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9],
'D': [10, 11, 12]})
# 使用 pd.concat() 沿列轴连接两个 DataFrame
result = pd.concat([df1, df2], axis=1)
# 打印结果
print(result)
6)df.Series_name.value_counts()
计算DataFrame中某个Series中每个唯一值的出现次数
import pandas as pd
import numpy as np
def main():
data = {'A': [1, 2, 3],
'B': [7, 3, 1],
'C': [7, 8, 9]}
df = pd.DataFrame(data)
target = df.B.value_counts()
print(target)实际应用中,DataFrame中还有很多方法没有介绍,根据需要边用边查。















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









