






 本文介绍如何利用开源工具Tesseract和OpenCV从图像中识别文字,涵盖安装指南、基本使用方法及常见错误处理,并通过多个实例展示其在不同场景下的应用效果。
本文介绍如何利用开源工具Tesseract和OpenCV从图像中识别文字,涵盖安装指南、基本使用方法及常见错误处理,并通过多个实例展示其在不同场景下的应用效果。
In today’s post, we will learn how to recognize text in images using an open source tool called Tesseract and OpenCV. The method of extracting text from images is also called Optical Character Recognition (OCR) or sometimes simply text recognition.
Tesseract was developed as a proprietary software by Hewlett Packard Labs. In 2005, it was open sourced by HP in collaboration with the University of Nevada, Las Vegas. Since 2006 it has been actively developed by Google and many open source contributors.
Tesseract acquired maturity with version 3.x when it started supporting many image formats and gradually added a large number of scripts (languages). Tesseract 3.x is based on traditional computer vision algorithms. In the past few years, Deep Learning based methods have surpassed traditional machine learning techniques by a huge margin in terms of accuracy in many areas of Computer Vision. Handwriting recognition is one of the prominent examples. So, it was just a matter of time before Tesseract too had a Deep Learning based recognition engine.
In version 4, Tesseract has implemented a Long Short Term Memory (LSTM) based recognition engine. LSTM is a kind of Recurrent Neural Network (RNN).
Note for beginners: To recognize an image containing a single character, we typically use a Convolutional Neural Network (CNN). Text of arbitrary length is a sequence of characters, and such problems are solved using RNNs and LSTM is a popular form of RNN. Read this post to learn more about LSTM.
Version 4 of Tesseract also has the legacy OCR engine of Tesseract 3, but the LSTM engine is the default and we use it exclusively in this post.
Tesseract library is shipped with a handy command line tool called tesseract. We can use this tool to perform OCR on images and the output is stored in a text file. If we want to integrate Tesseract in our C++ or Python code, we will use Tesseract’s API. The usage is covered in Section 2, but let us first start with installation instructions.
1. How to install Tesseract on Ubuntu and macOS
We will install:
- Tesseract library (libtesseract)
- Command line Tesseract tool (tesseract-ocr)
- Python wrapper for tesseract (pytesseract)
Later in the tutorial, we will discuss how to install language and script files for languages other than English.
1.1. Install Tesseract 4.0 on Ubuntu 18.04
Tesseract 4 is included with Ubuntu 18.04, so we will install it directly using Ubuntu package manager.
| 1 2 3 |
|
1.2. Install Tesseract 4.0 on Ubuntu 14.04, 16.04, 17.04, 17.10
Due to certain dependencies, only Tesseract 3 is available from official release channels for Ubuntu versions older than 18.04.
Luckily Ubuntu PPA – alex-p/tesseract-ocr maintains Tesseract 4 for Ubuntu versions 14.04, 16.04, 17.04, 17.10. We add this PPA to our Ubuntu machine and install Tesseract. If you have an Ubuntu version other than these, you will have to compile Tesseract from source.
| 1 2 3 4 5 |
|
1.3. Install Tesseract 4.0 on macOS
We will use Homebrew to install Tesseract on Homebrew. By default, Homebrew installs Tesseract 3, but we can nudge it to install the latest version from the Tesseract git repo using the following command.
| 1 2 3 4 |
|
1.4. Checking Tesseract version
To check if everything went right in the previous steps, try the following on the command line
| 1 |
|
And you will see the output similar to
tesseract 4.0.0-beta.1-306-g45b11
leptonica-1.76.0
libjpeg 9c : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.8
Found AVX2
Found AVX
Found SSE
2. Tesseract Basic Usage
As mentioned earlier, we can use the command line utility or use the Tesseract API to integrate it in our C++ and Python application. In the very basic usage, we specify the following
- Input filename: We use image.jpg in the examples below.
- OCR language: The language in our basic examples is set to English (eng). On the command line and pytesseract, it is specified using the -l option.
- OCR Engine Mode (oem): Tesseract 4 has two OCR engines — 1) Legacy Tesseract engine 2) LSTM engine. There are four modes of operation chosen using the
--oemoption.0 Legacy engine only. 1 Neural nets LSTM engine only. 2 Legacy + LSTM engines. 3 Default, based on what is available.
- Page Segmentation Mode (psm): PSM can be very useful when you have additional information about the structure of the text. We will cover some of these modes in a followup tutorial. In this tutorial we will stick to psm = 3 (i.e. PSM_AUTO).
Note: When the PSM is not specified, it defaults to 3 in the command line and python versions, but to 6 in the C++ API. If you are not getting the same results using the command line version and the C++ API, explicitly set the PSM.
2.1. Command Line Usage
The examples below show how to perform OCR using tesseract command line tool. The language is chosen to be English and the OCR engine mode is set to 1 ( i.e. LSTM only ).
| 1 2 3 4 |
|
2.2. Using pytesseract
In Python, we use the pytesseract module. It is simply a wrapper around the command line tool with the command line options specified using the config argument. The basic usage requires us to first read the image using OpenCV and pass the image to image_to_string method of the pytesseract class along with the language (eng).
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
2.3. Using the C++ API
In the C++ version, we first need to include tesseract/baseapi.h and leptonica/allheaders.h. We then create a pointer to an instance of the TessBaseAPI class. We initialize the language to English (eng) and the OCR engine to tesseract::OEM_LSTM_ONLY ( this is equivalent to the command line option --oem 1) . Finally, we use OpenCV to read in the image, and pass this image to the OCR engine using its SetImagemethod. The output text is read out using GetUTF8Text().
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
You can compile the C++ code by running following command on terminal,
| 1 |
|
Now you can use it by passing the path of an image
| 1 |
|
2.4. Language Pack Error
You may encounter an error that says
Error opening data file tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.
It just means the language pack (tessdata/eng.traineddata) is not in the right path. You can solve this in two ways.
- Option 1 : Make sure the file is in the expected path ( e.g. on linux the path is /usr/share/tesseract-ocr/4.00/tessdata/eng.traineddata).
- Option 2 : Create a directory tessdata, download the eng.traineddata and save the file to tessdata/eng.traineddata. Then you can direct Tesseract to look for the language pack in this directory using
1
tesseract image.jpg stdout --tessdata-dirtessdata -l eng --oem 1 --psm 3Similarly, you will need to change line 20 of the python code to
20
config=('--tessdata-dir "tessdata" -l eng --oem 1 --psm 3')and Line 18 of the C++ code to
18
ocr->Init("tessdata","eng", tesseract::OEM_LSTM_ONLY);
3. Use Cases
Tesseract is a general purpose OCR engine, but it works best when we have clean black text on solid white background in a common font. It also works well when the text is approximately horizontal and the text height is at least 20 pixels. If the text has a surrounding border, it may be detected as some random text.
For example, if you scanned a book with a high-quality scanner, the results would be great. But if you took a passport with complex guilloche pattern in the background, the text recognition may not work as well. In such cases, there are several tricks that we need to employ to make reading such text possible. We will discuss those advance tricks in our next post.
Let’s look at these relatively easy examples.
Download Code
To easily follow along this tutorial, please download code by clicking on the button below. It’s FREE!
3.1 Documents (book pages, letters)
Let’s take an example of a photo of book page.
Photograph of a book page.
When we process this image using tesseract, it produces following output:
Output
1.1 What is computer vision? As humans, we perceive the three-dimensional structure of the world around us with apparent
ease. Think of how vivid the three-dimensional percept is when you look at a vase of flowers
sitting on the table next to you. You can tell the shape and translucency of each petal through
the subtle patterns of light and Shading that play across its surface and effortlessly segment
each flower from the background of the scene (Figure 1.1). Looking at a framed group por-
trait, you can easily count (and name) all of the people in the picture and even guess at their
emotions from their facial appearance. Perceptual psychologists have spent decades trying to
understand how the visual system works and, even though they can devise optical illusions!
to tease apart some of its principles (Figure 1.3), a complete solution to this puzzle remains
elusive (Marr 1982; Palmer 1999; Livingstone 2008).
Even though there is a slight slant in the text, Tesseract does a reasonable job with very few mistakes.
3.2 Receipts
The text structure in book pages is very well defined i.e. words and sentences are equally spaced and very less variation in font sizes which is not the case in bill receipts. A slightly difficult example is a Receipt which has non-uniform text layout and multiple fonts. Let’s see how well does tesseract perform on scanned receipts.
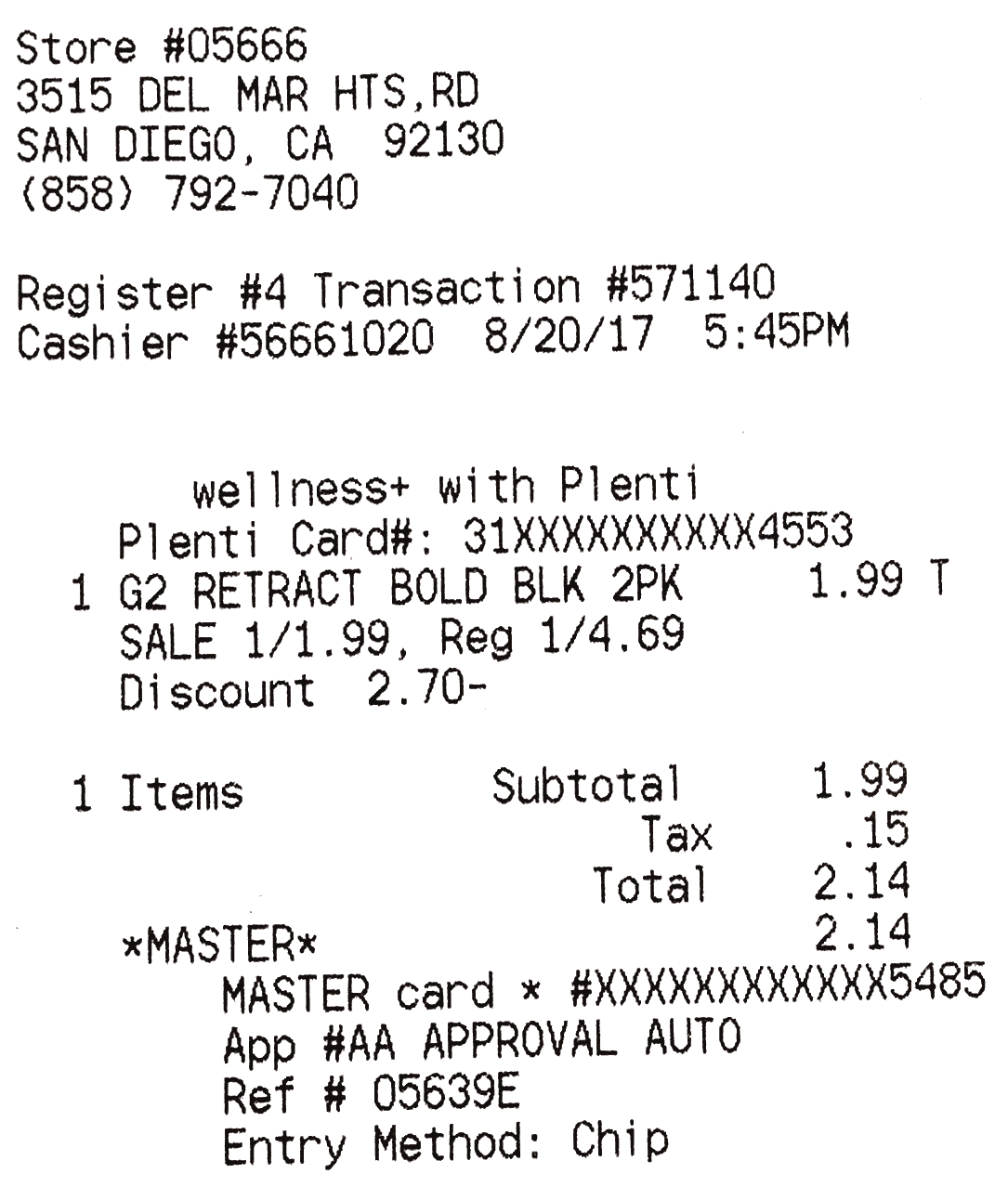
OCR Receipt Example
Output
Store #056663515
DEL MAR HTS,RD
SAN DIEGO, CA 92130
(858) 792-7040Register #4 Transaction #571140
Cashier #56661020 8/20/17 5:45PMwellnesst+ with Plenti
Plenti Card#: 31XXXXXXXXXX4553
1 G2 RETRACT BOLD BLK 2PK 1.99 T
SALE 1/1.99, Reg 1/4.69
Discount 2.70-
1 Items Subtotal 1.99
Tax .15
Total 2.14
*xMASTER* 2.14
MASTER card * #XXXXXXXXXXXX548S
Apo #AA APPROVAL AUTO
Ref # 05639E
Entry Method: Chip
3.3 Street Signs
If you get lucky, you can also get this simple code to read simple street signs.

Traffic sign board
Output
SKATEBOARDING
BICYCLE RIDING
ROLLER BLADING
SCOOTER RIDING
®
Note, it mistakes the screw for a symbol.
Let’s look at a slightly more difficult example. You can see there is some background clutter and the text is surrounded by a rectangle.

Property Sign Board
Tesseract does not do a very good job with dark boundaries and often assumes it to be text.
Output
| THIS PROPERTY
} ISPROTECTEDBY ||
| VIDEO SURVEILLANCE
However, if we help Tesseract a bit by cropping out the text region, it gives perfect output.

Cropped Notice Board
Output
THIS PROPERTY
IS PROTECTED BY
VIDEO SURVEILLANCE
The above example illustrates why we need text detection before we do text recognition. A text detection algorithm outputs a bounding box around text areas which can then be fed into a text recognition engine like Tesseract for high-quality output. We will cover this in a future post.
Subscribe & Download Code
If you liked this article and would like to download code (C++ and Python) and example images used in this post, please subscribe to our newsletter. You will also receive a free Computer Vision ResourceGuide. In our newsletter, we share OpenCV tutorials and examples written in C++/Python, and Computer Vision and Machine Learning algorithms and news.

















 2785
2785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









