







目录
参考:
概括
1、基于多级内存管理策略
2、内存分配器
3、span和元素
4、内存预分配与切分
5、内存回收与复用
6、主旨
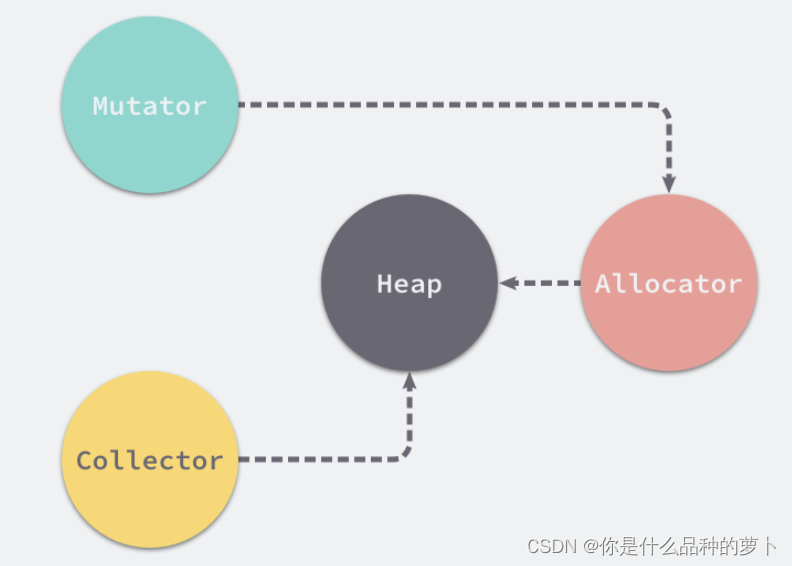
内存的几个部分
-
Mutator: 用户程序
-
Allocator: 内存分配器
-
Collector: 垃圾回收器
-
Heap: 堆
1、栈区(stack sagment)
-
存放函数的参数,返回值,局部变量值
-
在编译期确定
-
由高向低扩展,内存连续(栈顶地址和最大容量是预先规定好的,windows中栈的大小是2M)
-
申请时若栈的剩余空间不足,会提示overflow
-
能从栈获得的空间较小
-
goroutine的初始栈大小2KB
2、堆区(heap sagment)
-
存放被动态分配的内存
-
在运行时分配,C++由工程师主动申请和释放内存,Go是由内存分配器分配并由垃圾收集器回收
-
由低向高扩展,不连续的内存(链表存储,链表是由低向高的)
-
堆获得的空间比较灵活,也比较大,受限于计算机的虚拟内存
3、全局区(静态区)(data sagment)
-
全局变量和静态变量的存储在一起
-
程序结束后由系统释放
-
大小由系统限定,一般很大
4、文字常量区
-
存放常量字符串
-
程序结束后由系统释放
5、程序代码区
-
存放函数体的二进制代码
内存的分配方法
1、线性分配器
在内存中维护一个指向内存位置的指针,申请内存时,分配器只需要检查剩余的空闲内存,返回分配的内存区域并移动指针。复杂度低,执行效率高。
但内存被回收后无法重用,要配合垃圾回收机制使用。
2、空闲链表分配器
用链表维护内存空间。
可以方便的进行内存回收重用。
由于分配内存时需要遍历链表,所以时间复杂度是 𝑂(𝑛)。内存块的选择方式可以使用不同的策略。
go的分级内存分配
go的内存分配方式是基于线程缓存分配(Thread-Caching Malloc,TCMalloc),比 glibc 中的 malloc 还要快很多。主要是使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略。
0、为什么分配速度快
-
分级分配和缓存策略
-
内存对齐机制
-
逃逸分析
-
栈上分配的优势
1、对象大小
-
tiny 微对象 <16B
-
小对象 <32KB
-
大对象 >32KB
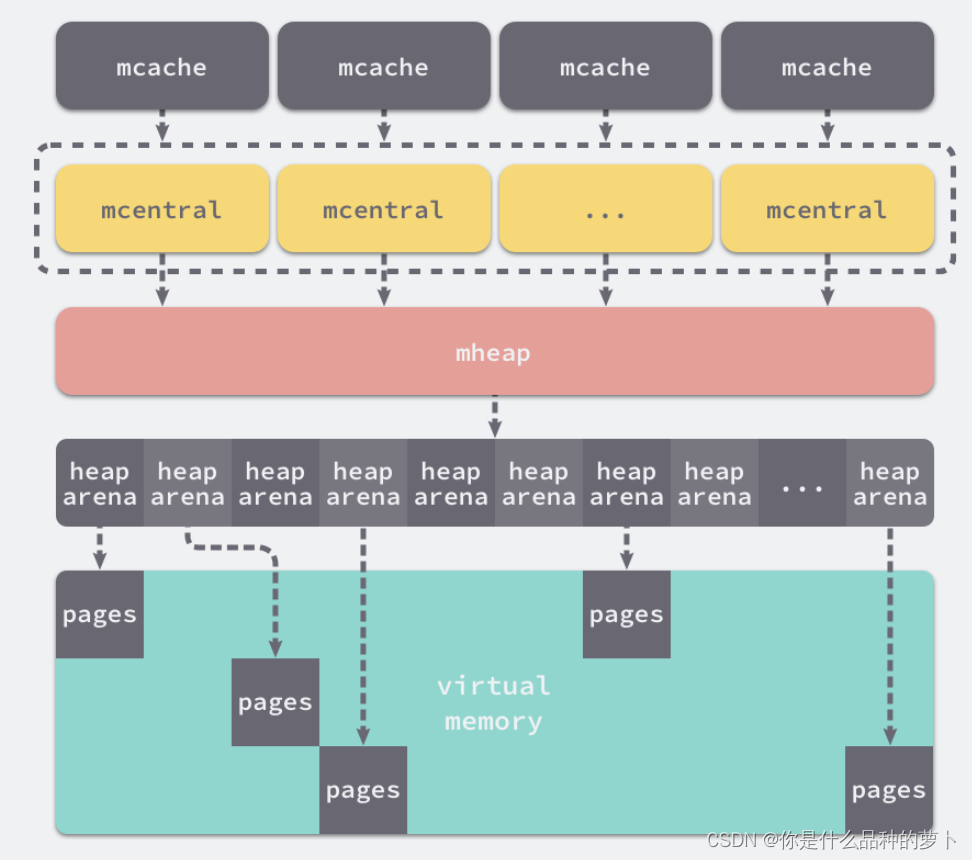
2、多级缓存
-
线程缓存 mcache
-
中心缓存 mcentral
-
页堆 mheap
mcache属于每个独立的线程,所以不需要锁,减少了锁竞争带来的性能损耗。
tiny对象和小对象都由mcache分配,不够时会向mcentral拿一块新的。
大对象直接从mheap分配。
3、地址空间的4种状态
-
none:初始状态
-
reserved:地址已经被runtime拥有,但并未真正分配,访问会异常
-
prepared:地址已经是reserved,但并未真正分配,内存被保留,一般没有对应的物理内存访问该片内存的行为是未定义的可以快速转换到ready状态
-
ready:地址空间已被分配, 可以被安全访问
4、主要结构
(1)mspan
go内存的基本单元,管理一串地址连续的空间。
双向链表存储结构。
(2)mcache
每个P都有一个mcache,每一个mcache持有 68*2 个mspan。
mcache在刚被初始化时是不包含mspan的,只有当用户申请内存时才会从上一级组件获取新的mspan。
(3)mcentral
全局的,访问需要锁。
存储包含空闲对象和不包含空闲对象的内存管理单元。
(4)mheap
全局的,用于管理golang的整个堆。
真实拥有虚拟地址,当mcentral不够时候,会向mheap申请
mheap包含一个长度为 136 的mcentral数组,其中 68 个是scan的mcentral,另外的 68 个是noscan的mcentral
(5)heapArena
Go的所有内存空间都由二维矩阵heapArena管理。
一个heapArena下有多个mspan。
5、整体结构
所有的go程序都会在启动时初始化如下内存布局,每一个线程P都会分配一个mcache用于处理tiny对象和小对象的分配,它们会持有内存管理单元mspan。
每个类型的mspan都会管理特定大小的对象,当mspan中不存在空闲对象时,它们会从mheap持有的134个中心缓存mcentral中获取新的内存单元,mcentral属于全局的堆结构体mheap,它会从操作系统中申请内存。
在amd64的linux操作系统上,mheap会持有4194304个heapArena,每个heapArena都会管理 64MB 的内存,单个go程序的内存上限也就是256TB。
内存逃逸
1、含义
2、危害
-
函数结束后不需要的变量会留在堆里
-
堆的分配和回收开销比栈大得多
-
会造成gc压力,增加内存碎片
3、逃逸原则
-
编译期不确定变量的具体类型
-
变量生命周期不确定
-
变量占用内存较大(>32KB)
-
变量大小不确定
4、导致内存逃逸的操作
(1)向 channel 发送指针
编译时不知道channel中的数据会被哪个goroutine接收,所以编译器不知道变量什么时候才会被释放,只能放入堆中。
(2)局部变量在函数结束后还被使用
如:函数返回局部变量指针、闭包中引用包外的值。因为变量的生命周期可能会超过函数周期,所以会放入堆中。
(3)slice 或 map 中存储指针
比如 []*string,后面的数组可能是在栈上分配的,但其引用的值还是在堆上。
(4)切片扩容
扩容后长度太大,导致栈空间不足,逃逸到堆上。
(5)在 interface 类型上调用方法
会把interface变量使用堆分配, 因为方法的真正实现只能在运行时知道。
5、如何避免
-
对小数据,使用传值而不是传指针
-
避免使用长度不固定的slice
-
interface调用方法会发生内存逃逸,谨慎使用
栈空间
1、栈扩容
(1)原因
golang使用连续栈,goroutine初始时只给栈分配很小的空间(2KB),随着函数的调用层级加深,Go 的初始栈空间就可能不够用,就会触发栈空间的扩容
(2)时机
编译器的运行时检查runtime.morestack,在几乎所有函数调用之前
(3)操作
调用runtime.newstack 创建新的栈,调用runtime.copystack进行栈拷贝,并调整原来指针的指向新栈空间翻倍,最大限制1G。
2、栈缩容
(1)原因
在函数返回后,对应的栈空间会回收,如果调用栈比较深,随着函数一个一个返回,回收的栈空间会越来越多。假设在调用栈最深的时候,整体的栈空间扩容到了 100M,那么随着函数的返回,到某一个函数的时候,100M 的栈空间只有 1M 是实际占用的,内存利用率只有 1%。
(2)时机
在垃圾回收时,检查栈空间的内存利用率,当低于1/4 时,开始缩容
(3)操作
调用扩容时使用的 runtime.copystack 开辟新的栈空间,并调整原来指针的指向
栈空间减少一半,最低限制 2KB
3、疑问
- 栈扩容是什么时候做的?会不会出现函数执行到一半扩容?
- 扩容和缩容会改变已有变量的地址吗?















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









