







目录
1. boltdb 核心思想
boltdb 是 go 语言实现的一种单机 kv 数据磁盘存储系统:
-
单机运行: 无需考虑分布式共识相关内容(简单)
-
磁盘存储: kv 数据存储于磁盘(可靠)
-
本地读写: 读写时直接与本地文件交互,没有客户端与服务端的通信环节(简单、粗暴、高效)
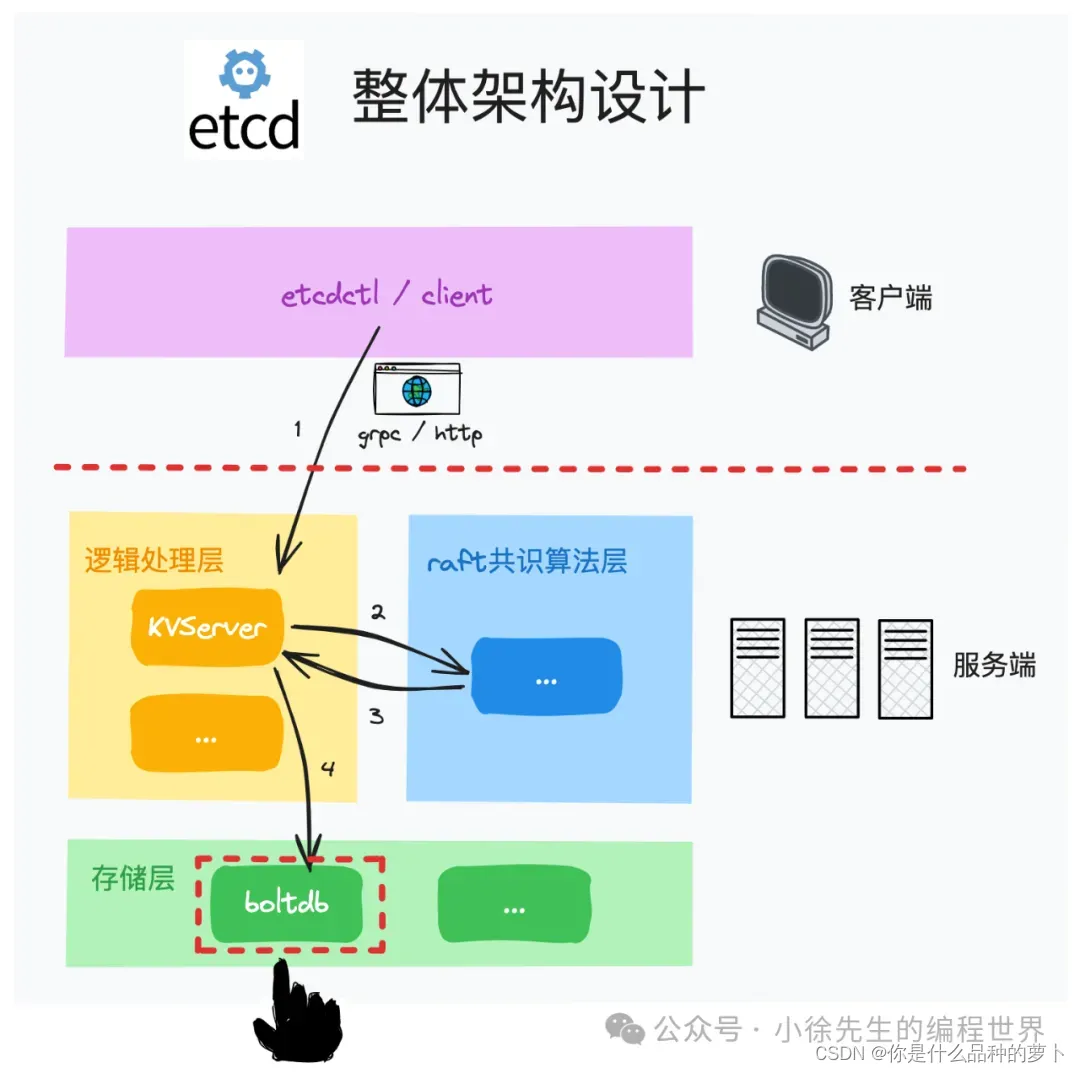
boltdb 在 etcd 整体架构中的层次定位:
核心思想:
-
数据以一个文件的形式存在磁盘上,建立磁盘与内存的映射,在程序中直接操作内存
-
磁盘与内存以页(page)为单位交换数据
-
底层数据结构使用 B+ 树实现,bucket(表)和数据都使用 B+ 树维护
-
基于 mmap 实现读
-
基于 page buffer 实现写
-
使用事务机制,读读并行,读写串行
2. 概念
(1) mmap
memory-mapping,是内核的一个概念,它隐藏了与磁盘交互的细节,使用方能够像访问内存中的字节数组一样读取磁盘文件中的内容。
(2) page
内存与磁盘间数据的交换以页 page 为单位,page 大小一般是操作系统的页大小,分为 4 类 page:
-
meta page:存储 boltdb 的元数据,如版本号、校验和、全局递增的事务 id
-
freelist page:存储空闲 page 信息,哪些 page 空闲可用,哪些 page 将被事务释放(全局维度,相当于 go 语言中的 heap,以空间换时间,缓存并管理空闲 page 以供复用,减少与操作系统的交互频率)
-
branch element page:存储索引的节点, 对应为 b+ 树中的分支节点
-
leaf element page:存储数据的节点, 对应为 b+树中的叶子节点
(3) B+树
boltdb 的实现对 B+ 树进行了改造:
-
引入游标工具: 底层叶子节点未通过链表串联,范围检索会借助一个压栈记录了移动路径的游标指针来完成
-
降低调整频率: 为兼顾操作效率与b+树的平衡性,boltdb 仅在数据溢写落盘前,才一次性完成 b+树的平衡性调整
(4) bucket
boltdb 中的 bucket 即为数据库表,是嵌套式的拓扑关系,使用 B+ 树实现。每个 db 会有个默认的 root bucket,以此为起点可以衍生出一个 bucket B+ 树,每个 bucket 下的数据又是一颗 B+树。
(5) 只读事务和读写事务
boltdb 中的事务分为只读事务 read-only tx 和读写事务 read-write tx 两类:
-
读写事务:同一时刻只能有一个读写事务执行,但可以和多个只读事务并行执行
-
只读事务:多个只读事务可以并行执行
3. 核心方法
3.1 boltDB 的初始化
DB 数据结构定义为:
type DB struct {
// ...
// 数据库文件路径
path string
// 打开文件方法
openFile func(string, int, os.FileMode) (*os.File, error)
// 数据库文件,所有数据存储于此
file *os.File
// 基于 mmap 映射的数据库文件内容,maxMapSize默认256TB
data *[maxMapSize]byte
// ...
// 两个轮换使用的 meta page, 记录数据库元信息
meta0 *meta
meta1 *meta
// 数据库单个 page 的大小,单位 byte, 默认是操作系统页面大小,一般是4KB
pageSize int
// 数据库是否已启动
opened bool
// 全局唯一的读写事务
rwtx *Tx
// 一系列可并行的只读事务
txs []*Tx
// freelist,管理空闲的 page
freelist *freelist
freelistLoad sync.Once
// 对象池,复用 page 字节数组
pagePool sync.Pool
// ...
// 互斥锁,保证读写事务全局唯一
rwlock sync.Mutex
// 保护 meta page 的互斥锁
metalock sync.Mutex
// 保护 mmap 的读写锁
mmaplock sync.RWMutex
// 数据落盘持久化时使用的操作方法,对应为 pwrite 操作
ops struct {
writeAt func(b []byte, off int64) (n int, err error)
}
// 是否已只读模式启动数据库
readOnly bool
}DB 结构在 Open() 时被初始化,其主要流程为:
-
构造 db 实例,并读取各项 option 完成配置
-
通过传入的 path,打开对应的数据库文件(文件不存在则创建)
-
倘若在创建新的数据库文件,会初始化 4 个 page:2 个 meta page、1 个 freelist page、1 个 leaf element page
-
构造 pagePool 对象池,后续可复用 page 的字节数组
-
执行 mmap 操作,完成数据库文件和内存空间的映射
-
返回构造好的 db 实例
3.2 mmap 磁盘内存映射
mmap
创建了磁盘和内存映射,
方法:
func (db *DB) mmap(minsz int) (err error)其流程为:
-
加锁保证 mmap 操作并发安全
-
设置合适的 mmap 空间大小
-
若此前已经有读写事务在运行,此时因为要执行 mmap 操作,则需要对 bucket 内容进行重塑
-
解除之前建立的 mmap 映射
-
建立新的 mmap 映射
mmap 底层是通过调用系统内核实现的,不同的操作系统(windows、unix 等)会有不同的实现细节,unix的调用:
unix.Mmap(int(db.file.Fd()), 0, sz, syscall.PROT_READ, syscall.MAP_SHARED|db.MmapFlags)
映射后的内容放入了 DB 结构的
data 数组
中,后续的读操作就是直接读这个数组。
3.3 bucket的创建和查询
bucket 的创建方法:
func (b *Bucket) CreateBucket(key []byte) (*Bucket, error)其步骤为:
-
借助游标,找到 bucket key 所应当从属的父 bucket b+ 树的位置
-
创建子 bucket实例,并取得序列化后的结果
-
将 bucket 名称作为 key,bucket 序列化结果作为 value,以一组 kv 对的形式插入到父 bucket b+ 树中
bucket 的查询方法:
func (b *Bucket) Bucket(name []byte) *Bucket其步骤为:
-
查看父 bucket 的缓存 map,如果子 bucket 已反序列化过,则直接复用
-
通过游标 cursor 检索父 bucket 的 b+ 树,找到对应子 bucket 的 kv 对数据
-
根据 kv 数据反序列化生成子 bucket 实例
-
将子 bucket 添加到父 bucket 的缓存 map 中
-
返回检索得到的子 bucket
3.4 数据的CRUD
数据的增、改都是 Put 方法:
func (b *Bucket) Put(key []byte, value []byte) error-
借助游标检索到 k-v 对所在的位置
-
在对应位置中插入 k-v 对内容
数据的删除方法:
func (b *Bucket) Delete(key []byte) error- 借助游标移动到 key 对应位置
- 若 key 不存在,直接返回
- 在 b+ 树节点中删除对应的 key
数据的查询方法:
func (b *Bucket) Get(key []byte) []byte- 借助游标检索到 kv 对所在位置
- 若 key 不存在,直接返回
- 返回对应的 value
3.5 事务提交
事务提交方法:
func (tx *Tx) Commit() error在 boltdb 提交读写事务时,会一次性将更新的脏数据溢写落盘:
-
通过 rebalance 和 spill 操作,保证 b+ 树的平衡性满足要求
-
执行 pwrite+fdatasync 操作,完成脏数据的 page 的一些落盘
-
通过 pagePool 回收用于指向这部分 page 对应的字节数组
-
由于更新了事务进度,meta page 也需要溢写落盘
-
关闭读写事务
贴上源码:
func (tx *Tx) Commit() error {
// ...
// 数据溢写磁盘前,需要调整一轮 b+ 树,保证其平衡性
// rebalance 是为了避免因为 delete 操作,导致某些节点 kv 对数量太少,不满足 b+ 树平衡性要求
tx.root.rebalance()
// ...
// spill 是为了避免因为 put 操作,导致某些节点 kv 对数量太多,不满足 b+ 树平衡性要求
if err := tx.root.spill(); err != nil {
tx.rollback()
return err
}
// 事务更新到的脏数据溢写落盘
if err := tx.write(); err != nil {
tx.rollback()
return err
}
// ...
// meta page 溢写落盘
if err := tx.writeMeta(); err != nil {
tx.rollback()
return err
}
// ...
// 关闭事务
tx.close()
// ...
return nil
}
// 事务脏页溢写落盘
func (tx *Tx) write() error {
// 事务缓存的脏页
pages := make(pages, 0, len(tx.pages))
for _, p := range tx.pages {
pages = append(pages, p)
}
// 清空缓存
tx.pages = make(map[pgid]*page)
// 对脏页进行排序
sort.Sort(pages)
// 按照顺序,将脏页溢写落盘
for _, p := range pages {
// page 总大小,包含 overflow 不分
rem := (uint64(p.overflow) + 1) * uint64(tx.db.pageSize)
// page 的 offset,可以根据 page id 推算得到
offset := int64(p.id) * int64(tx.db.pageSize)
var written uintptr
// Write out page in "max allocation" sized chunks.
for {
sz := rem
if sz > maxAllocSize-1 {
sz = maxAllocSize - 1
}
buf := unsafeByteSlice(unsafe.Pointer(p), written, 0, int(sz))
// 将 page 溢写到文件对应 offset 的位置
if _, err := tx.db.ops.writeAt(buf, offset); err != nil {
return err
}
rem -= sz
// 一次性写完了
if rem == 0 {
break
}
// 如果没有一次性写完,下一轮接着写
offset += int64(sz)
written += uintptr(sz)
}
}
// fdatasync 操作,确保数据溢写落盘完成
if !tx.db.NoSync || IgnoreNoSync {
if err := fdatasync(tx.db); err != nil {
return err
}
}
// 释放这部分已落盘 page,倘若其不存在 overflow,说明是标准规格的字节数组,则清空内容,然后添加到对象池中进行复用
for _, p := range pages {
// Ignore page sizes over 1 page.
// These are allocated using make() instead of the page pool.
if int(p.overflow) != 0 {
continue
}
buf := unsafeByteSlice(unsafe.Pointer(p), 0, 0, tx.db.pageSize)
// See https://go.googlesource.com/go/+/f03c9202c43e0abb130669852082117ca50aa9b1
for i := range buf {
buf[i] = 0
}
tx.db.pagePool.Put(buf) //nolint:staticcheck
}
return nil
}实际使用时,通常会调用 Update 方法,启动隐式读写事务,方法结束时,boltdb 会处理事务的 commit 与 rollback,不需要手动调用了:
func (db *DB) Update(fn func(*Tx) error) error














 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









