







目录
1.Workload工作负载
又称为控制器,是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试进行重启,当根据重启策略无效,则会重新新建pod的资源。
k8s提供几种资源作为工作负载:
- 无状态的:Deployment, Replicaset
- 有状态的:Statefulset
- 守护进程:Daemonset
- 批处理:Job, Cronjob
2.Pod的生命周期
生命周期
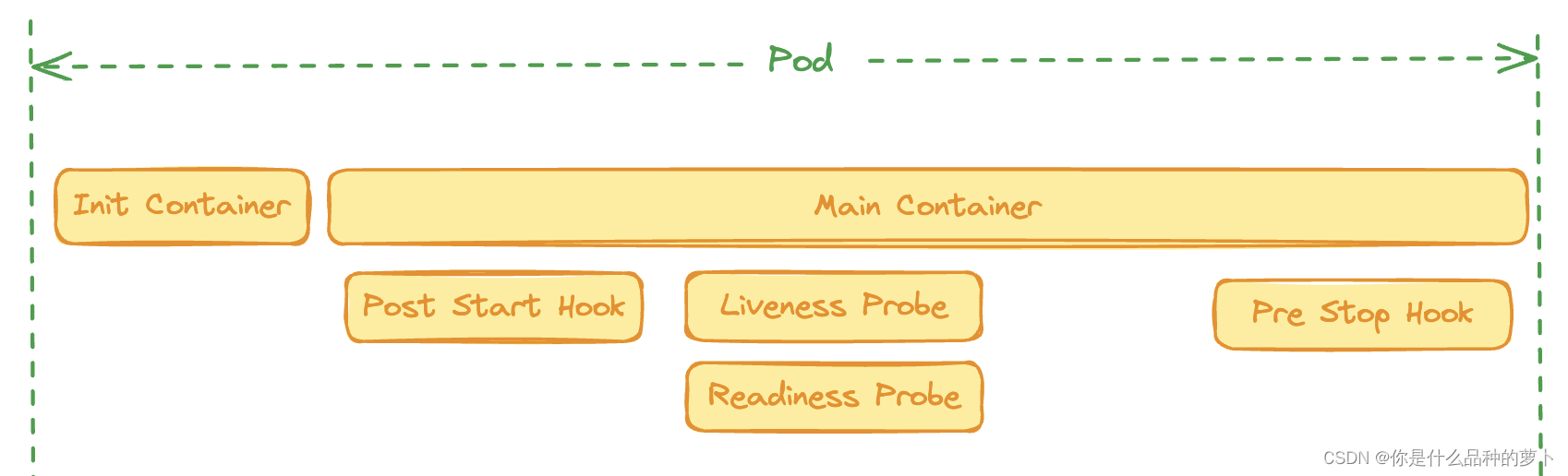
-
Init Container: 初始化
-
Main Container: 主容器运行时
-
Post Start Hook: 启动主容器后的hook
-
Pre Stop Hook: 主容器退出前的hook
Pod的几个阶段
(PodStatus.Phase参数)
-
Pending:等待pod被调度,拉取镜像
-
Running:至少一个容器在运行
-
Succeed:全部容器成功终止
-
Failed:全部容器终止,且至少一个容器失败终止
-
Unknown:一般是无法与主机通信
当一个 Pod 被删除时,执行一些 kubectl 命令会展示这个 Pod 的状态为 Terminating(终止),但这个 Terminating 状态并不是 Pod 阶段之一。
容器的几个状态
-
Waiting:拉取镜像等
-
Running:此时postStart已经被执行完成
-
Terminated:preStop会在容器进入Terminated之前执行
3.健康检查
存活探针LivenessProbe
用于判断容器是否存活,即Pod是否为running状态,如果LivenessProbe探针探测到容器不健康,kubelet将kill掉容器,并根据容器的重启策略(restartPolicy)重启。
就绪探针ReadinessProbe
用于判断容器是否正常提供服务,即容器的Ready是否为True,是否可以接收请求,如果ReadinessProbe探测失败,则容器的Ready将为False, Endpoint Controller 控制器将此Pod的Endpoint从对应的service的Endpoint列表中移除,不再将任何请求调度此Pod上,直到下次探测成功。
三种检查类型
-
exec:执行一条命令,退出码为0表示健康
-
httpGet:发送http请求,返回200-399状态码表示健康
-
tcpSocket:检查IP和Port,能建立TCP连接表示健康
参数:
-
initialDelaySeconds:容器启动后需要等待多少秒进行第一次探测
-
periodSeconds:执行探测的频率。默认10s
-
timeoutSeconds:探测超时时间。默认1s
-
successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认1
-
failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认3
containers:
- name: whomai
image: containous/whoami
livenessProbe:
httpGet:
path: /ping
port: 8080
scheme: HTTP
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间4.Pod的滚动更新策略
maxSurge:最大激增数
更新过程中,最多可以比replicas预先设定值多出的pod数量,可以为固定值或百分比,默认为desired Pods数的25%。计算时向上取整,更新过程中最多会有replicas + maxSurge个pod
maxUnavailable:最大不可用数
更新过程中,最多有几个pod处于无法服务状态,可以为固定值或百分比,默认为desired Pods数的25%。计算时向下取整。
pod的滚动更新过程
2个实例,maxSurge 25%,maxUnavailable 25%情况下,pod的滚动更新过程:
- maxSurge 25%,2个实例,向上取整则maxSurge为1,意味着最多可以有3个Pod,那么此时会新创建1个ReplicaSet RS-new,把副本数置为1,副本控制器创建这个新的Pod
- 同时,maxUnavailable是25%,副本数2*25%,向下取整则为0,意味着滚动更新的过程中,不能有少于2个可用的Pod,因此,旧的Replica(RS-old)会先保持不动,等RS-new管理的Pod状态Ready后,此时已经有3个Ready状态的Pod了,那么由于只要保证有2个可用的Pod即可,因此,RS-old的副本数会有2个变成1个,此时,会删掉一个旧的Pod
- 删掉旧的Pod的时候,由于总的Pod数量又变成2个了,因此,距离最大的3个还有1个Pod可以创建,所以,RS-new把管理的副本数由1改成2,此时又会创建1个新的Pod,等RS-new管理了2个Pod都ready后,就可以把RS-old的副本数由1置为0了,这样就完成了滚动更新
查看滚动更新事件:
$ kubectl describe deploy myblog
Normal ScalingReplicaSet 2m53s deployment-controller Scaled up replica set myblog-7fb9874dd9 to 1
Normal ScalingReplicaSet 68s deployment-controller Scaled down replica set myblog-5bbf67444 to 2
Normal ScalingReplicaSet 68s deployment-controller Scaled up replica set myblog-7fb9874dd9 to 2
Normal ScalingReplicaSet 44s deployment-controller Scaled down replica set myblog-5bbf67444 to 1
Normal ScalingReplicaSet 44s deployment-controller Scaled up replica set myblog-7fb9874dd9 to 3
Normal ScalingReplicaSet 20s deployment-controller Scaled down replica set myblog-5bbf67444 to 05.Pod的重启与崩溃
容器的重启策略
restartPolicy 参数(当容器由于错误或其他原因退出时,k8s该做出什么反应),有三种重启策略:
-
Always:容器终止就重启
-
OnFailure:只有在容器错误退出时才重启
-
Never:不会自动重启
重启时间间隔:以指数级回退延迟机制(10s, 20s, 40s...)重启,最大300s
重置回退延时计时器:容器正常运行了 10 分钟就重置
pod的崩溃
过程:
-
最初的崩溃:根据 restartPolicy 立即重启
-
反复的崩溃:采用指数级回退延迟机制重启
-
CrashLoopBackOff 状态:这一状态表明容器正在处于“回退延迟机制”中
-
回退重置:容器成功运行了一定时间(10 分钟), k8s会重置回退延迟机制为初始值。
可能导致 CrashLoopBackOff 的原因:
-
应用程序错误
-
配置错误:环境变量/配置文件错误
-
资源限制
-
应用程序没有在预期时间内启动服务
-
存活探针或就绪探针返回失败
CrashLoopBackOff 如何排查:
-
检查容器日志: kubectl logs <podName>
-
检查事件:kubectl describe pod <podName> 查看 Pod 事件
-
检查配置:环境变量、挂载卷
-
检查资源限制: CPU、内存
-
调试应用程序















 3642
3642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









