







 推荐系统在信息过载的环境中,通过分析用户历史行为建模,提供个性化推荐。广泛应用在电子商务、电影网站、音乐电台、社交网络等多个场景。评估推荐系统不仅关注预测准确度,还涉及用户满意度、多样性、新颖性等多方面。离线实验、用户调查和在线实验是常见的评测方法。
推荐系统在信息过载的环境中,通过分析用户历史行为建模,提供个性化推荐。广泛应用在电子商务、电影网站、音乐电台、社交网络等多个场景。评估推荐系统不仅关注预测准确度,还涉及用户满意度、多样性、新颖性等多方面。离线实验、用户调查和在线实验是常见的评测方法。
什么是推荐系统
信息过载:information overload
-
推荐系统任务
-
联系用户和信息,一方面帮助用户发现对自己有价值的信息
另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢
推荐系统不需要用户提供明确的需求,通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息
搜索引擎满足了用户有明确目的主动查找需求,而推荐系统能够在用户没有明确目的的时候帮助他们发现感兴趣的新内容
-
社会化推荐(social recommendation)
-
让好友给自己推荐物品
基于内容的推荐 (content-based filtering)
-
分析用户曾经看过的电影找到用户喜欢的演员和导演,然后给用户推荐这些演员或者导演的其他电影
基于协同过滤(collaborative filtering)的推荐
-
找到和自己历史兴趣相似的一群用户,看看他们最近在看什么电影,那么结果可能比宽泛的热门排行榜更能符合自己的兴趣
个性化推荐系统的应用
电子商务
亚马逊:
-
个性化推荐列表
-
基于物品的推荐算法(item-based method)/Facebook的好友关系
相关推荐列表(打包销售(cross selling))
-
买了这个商品的用户也经常购买的其他商品
浏览过这个商品的用户经常购买的其他商品
电影和视频网站
Netflix/YouTube/Hulu:基于物品的推荐算法
个性化音乐网络电台
-
Pandora
- 基于内容(音乐基因工程) Last.fm
- 利用用户行为计算歌曲的相似度
个性化推荐的成功应用需要两个条件:
- 信息过载
- 用户大部分时候没有特别明确的需求
音乐推荐的特点:
- 物品空间大
- 消费每首歌的代价很小
- 物品种类丰富
- 听一首歌耗时很少
- 物品重用率很高
- 用户充满激情
- 上下文相关
- 次序很重要
- 很多播放列表资源
- 不需要用户全神贯注
- 高度社会化
音乐是一种非常适合用来推荐的物品
很多推荐系统都是作为一个应用存在于网站中(亚马逊的商品推荐和Netflix的电影推荐)
音乐推荐可以支持独立的个性化推荐网站(Pandora、Last.fm和豆瓣网络电台)
社交网络
-
社交网络中的个性化推荐技术主要应用
-
1.利用用户的社交网络信息对用户进行个性化的物品推荐;
2.信息流的会话推荐;
3.给用户推荐好友。
个性化阅读
-
Google Reader
- 用户关注自己感兴趣的人,然后看到所关注用户分享的文章 Zite
- 收集用户对文章的偏好信息 Digg
- 根据用户的Digg历史计算用户之间的兴趣相似度,然后给用户推荐和他兴趣相似的用户喜欢的文章
基于位置的服务
位置是一种很重要的上下文信息,基于位置给用户推荐离他近的且他感兴趣的服务,用户就更有可能去消费
个性化邮件
-
Tapestry
- 通过分析用户阅读邮件的历史行为和习惯对新邮件进行重新排序,从而提高用户的工作效率
个性化广告
-
计算广告学
| 个性化广告投放 | 狭义个性化推荐 |
|---|---|
| 以用户为核心 | 以广告为核心 |
个性化广告投放技术
- 上下文广告
- 搜索广告
- 个性化展示广告
推荐系统评测
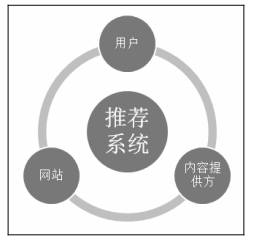
好的推荐系统,三方共赢
预测准确度是推荐系统领域的重要指标,准确的预测并不代表好的推荐。对于用户来说,他会觉得这个推荐结果很不新颖。
好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣。
推荐系统的试验方法
-
获得推荐系统指标的方法
-
离线实验(offline experiment)
用户调查(user study)
在线实验(online experiment)
离线实验
- 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
- 将数据集按照一定的规则分成训练集和测试集;
- 在训练集上训练用户兴趣模型,在测试集上进行预测;
- 通过事先定义的离线指标评测算法在测试集上的预测结果。
| 优点 | 缺点 |
|---|---|
| 不需要有对实际系统的控制权 | 无法计算商业上关心的指标 |
| 不需要用户参与实验 | 离线实验的指标和商业指标存在差距 |
| 速度快,可以测试大量算法 |
用户调查
- 用户调查需要有一些真实用户,让他们在需要测试的推荐系统上完成一些任务;
- 在他们完成任务时,我们需要观察和记录他们的行为,并让他们回答一些问题;
- 我们需要通过分析他们的行为和答案了解测试系统的性能。
| 优点 | 缺点 |
|---|---|
| 获得很多体现用户主观感受的指标 | 招募测试用户代价较大 |
| 相对在线实验风险很低,出现错误后很容易弥补 | 设计双盲实验非常困难 |
在线实验
-
AB测试是一种很常用的在线评测算法的实验方法 AB测试
-
它通过一定的规则将用户随机分成几组并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法
| 优点 | 缺点 |
|---|---|
| 公平获得不同算法实际在线时的性能指标 | 周期比较长 |
| 大型网站的AB测试系统的设计也是一项复杂的工程 |
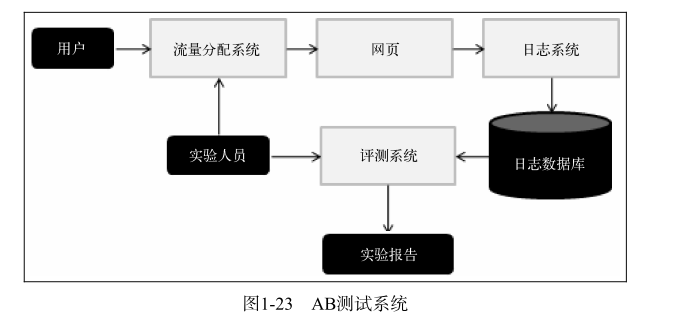
-
一个新的推荐算法最终上线,需要完成上面所说的3个实验
-
- 通过离线实验证明它在很多离线指标上优于现有的算法。
- 通过用户调查确定它的用户满意度不低于现有的算法。
- 通过在线的AB测试确定它在我们关心的指标上优于现有的算法。
评测指标
用户满意度
用户满意度没有办法离线计算,只能通过用户调查或者在线实验获得。
-
用户调查
- 用户调查获得用户满意度主要是通过 调查问卷的形式 在线实验
- 用户满意度主要通过一些对 用户行为的统计得到
预测准确度
-
预测准确度
- 度量一个推荐系统或者推荐算法预测用户行为的能力。
这个指标是最重要的推荐系统离线评测指标
-
不同的研究方向介绍它们的预测准确度指标 1.评分预测
-
评分预测的预测准确度一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算。对于
测试集中的一个用户 u 和物品i ,令 rui 是用户 u 对物品i 的实际评分,而 r^ui 是推荐算法给出的预测评分,那么RMSE的定义为:
RMSE=∑u,i∈T(rui−r^ui
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









