







python:正则表达式
一、什么是正则表达式
正则表达式也叫做匹配模式(Pattern),它由一组具有特定含义的字符串组成,通常用于匹配和替换文本。
正则表达式,是一个独立的技术,很多编程语言支持正则表达式处理。
Wiki:正则表达式(英语:Regular Expression、regex或regexp,缩写为RE),也译为正规表示法、常规表示法,在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
通常情况下,如果一个文本中出现了多个匹配,正则表达式返回第一个匹配,如果将 global 设置为 true,则会返回全部匹配;匹配模式是大小写敏感的,如果设置了 ignore case 为 true,则将忽略大小写区别。
有时侯正则表达式也简称为表达式、匹配模式或者模式,它们可以互换。 这里默认 global 和 ignore case 均为 true。
为什么要使用正则表达式
在软件开发过程中,经常会涉及到大量的关键字等各种字符串的操作,使用正则表达式能很大程度的简化开发的复杂度和开发的效率,所以在Python中正则表达式在字符串的查询匹配操作中占据很重要的地位
二、Python中的re模块
1.Python为了方便大家对于正则的使用,专门为大家提供了re模块供我们使用。
| import re # 导入re模块 dir(re) # 查看re模块的方法和属性 ['A', 'ASCII', 'DEBUG', 'DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'RegexFlag', ' S', 'Scanner', 'T', 'TEMPLATE', 'U', 'UNICODE', 'VERBOSE', 'X', '_MAXCACHE', '__all__', '__builtins_ _', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__ver sion__', '_alphanum_bytes', '_alphanum_str', '_cache', '_compile', '_compile_repl', '_expand', '_loc ale', '_pattern_type', '_pickle', '_subx', 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall ', 'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search', 'split', 'sre_compile', 'sre_pa rse', 'sub', 'subn', 'template'] |
查看字符串是否是以“lili”开头
| import re # 导入re模块 str = "lili" # 定义一个字符串等于lili # 查看"lili is a good girl"是否以lili开头,结果保存到res中 res = re.match(str,"mayun is very good shangren") # 使用res.group()提取匹配结果,如果是,则返回匹配对象(Match Object),否则返回None, res.group() # 将匹配的结果显示 结果如下: ‘lili' |
请看在命令行运行的例子:
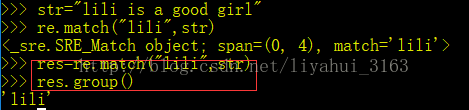
注意:re.match( )方法匹配的是以xxx开头的字符串,若不是开头的,尽管属于str内,则无法匹配。
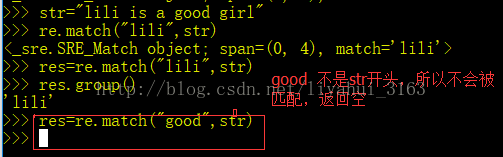
2.元字符
我们发现,虽然Python为外面提供了re模块供我们使用,但是功能太弱,远远无法满足我们的使用,所以我们需要继续学习正则的其他知识。
首先我们来看看正则的单个字符的匹配是如何完成的。
| 表1.常用的元字符 | |
| 代码 | 说明 |
| . | 匹配除换行符(\n)以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字0-9、a-z、A-Z、_(下划线)、汉字和其他国家的语言符号 |
| \W | 匹配非字母或数字或下划线或汉字,跟\w正好相反 |
| \s | 匹配任意的空白符 |
| \S | 匹配任意非空白符 |
| \d | 匹配数字 |
| \D | 匹配非数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| [] | 匹配[]中列举的字符 |
实例如下:
| re.match(".","A") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='A'> re.match(".","8") 运行结果: <_sre.SRE_Match object; span=(0, 1), match='8'> re.match(".","_") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='_'> re.match(".","liushuaige") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='l'> re.match(".","10086") #注意,只匹配第一个字符 运行结果:<_sre.SRE_Match object; span=(0, 1), match='1'> re.match(".*","10086”) # *表示匹配0到多个字符 运行结果:<_sre.SRE_Match object; span=(0, 5), match='10086'> re.match(".","\n10086") # 注意,在正则中\n(换行键是无法匹配的) 运行结果:无 re.match(".","\t10086") #注意,\t为制表符,相当于一个字符 运行结果:<_sre.SRE_Match object; span=(0, 1), match='\t'> re.match(".....","10086") 运行结果:<_sre.SRE_Match object; span=(0, 5), match='10086'> re.match(".*\\bgood\\b.*","today is a good day") 运行结果:<_sre.SRE_Match object; span=(0, 19), match='today is a good day'> re.match(".*(\\bgood\\b).*","today is a good day").group(1) 运行结果:'good'
# 匹配数字 re.match("[123456789]"," 6这个真是一个悲伤的故事 ") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='6'> re.match("[0-9]"," 6这个真是一个悲伤的故事 ") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='6'> re.match("[a-z]","this is good day") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='t'> re.match("[a-z0-9A-Z]"," this is good day") 运行结果: <_sre.SRE_Match object; span=(0, 1), match='t'> re.match("[a-z0-9A-Z王小明]","小this is good day") 运行结果: <_sre.SRE_Match object; span=(0, 1), match='小'> # 匹配所有中文 re.match("[\u4e00-\u9fa5]","大幅的发生") #汉字 运行结果: <_sre.SRE_Match object; span=(0, 1), match='大'> re.match("我今年5岁了","我今年5岁了") 运行结果:<_sre.SRE_Match object; span=(0, 6), match='我今年5岁了'> re.match("我今年\d岁了","我今年55岁了") # error 因为\d只会匹配一个数字 运行结果:无 re.match("我今年\d岁了","我今年55岁了") 运行结果:无 re.match("\D","我今年55岁了") #数字 运行结果:<_sre.SRE_Match object; span=(0, 1), match='我'> re.match("\D*","我今年55岁了") # 非数字 运行结果:<_sre.SRE_Match object; span=(0, 3), match='我今年'> re.match("\s"," 我今年55岁了") # 空白符 运行结果:<_sre.SRE_Match object; span=(0, 1), match=' '> re.match("\s","\t我今年55岁了") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='\t'> re.match("\s","\n我今年55岁了") #注意*不能匹配\n(换行符) 运行结果:<_sre.SRE_Match object; span=(0, 1), match='\n'> re.match("\s","\r我今年55岁了") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='\r'> |
3.字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没法指定它们,因为它们会被解释成其它的意思。这时你就必须使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用\\.
如:c:\\d\\e\\f.txt
| re.match("c:\\","c:\\a\\b") # error 报错,因为\\转义后就变成了\了 re.match("c:\\\\","c:\\a\\b") #正确 re.match(r"c:\\","c:\\a\\b") # 正确,在前面加“r”表示匹配的字符不进行转义,以后匹配符不要再写出上面的的转义了。 |
4.重复
在字符串的匹配中,不可避免的会出现重复字符,我们如何进行很友好的匹配呢?
| 表2.常用的限定符 | |
| 代码/语法 | 说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
下面是一些使用重复的例子:
Windows\d+匹配Windows后面跟1个或更多数字
1[238]\d{9}匹配以13后面跟9个数字(中国的手机号)
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
| +和*的差别 re.match("a[0-9]+h$","ah") 运行结果:无 re.match("a[0-9]*h$","ah") 运行结果:<_sre.SRE_Match object; span=(0, 2), match='ah'>
re.match("[A-Z][a-z]*","Liujianhong ") 运行结果:<_sre.SRE_Match object; span=(0, 11), match='Liujianhong'> re.match("[A-Za-z]*","LiuJianhong ") 运行结果:<_sre.SRE_Match object; span=(0, 11), match='LiuJianhong'> re.match("[A-Z][a-z]*","LiuJianhong ") 运行结果:<_sre.SRE_Match object; span=(0, 3), match='Liu'>(因为J是大写的) re.match("[a-zA-Z_]+[\w_]*","LiuJianhong3 ") 运行结果:<_sre.SRE_Match object; span=(0, 12), match='LiuJianhong3'> re.match("[0-9]?[\d]","1") 运行结果:<_sre.SRE_Match object; span=(0, 1), match='1'> re.match("[0-9]?[\d]","111") 运行结果:<_sre.SRE_Match object; span=(0, 2), match='11'> re.match("a[0-9]?h$","a12456h") 运行结果:无 re.match("a[0-9]?h$","ah") 运行结果:<_sre.SRE_Match object; span=(0, 2), match='ah'> re.match("a[0-9]?h$","a3h") 运行结果:<_sre.SRE_Match object; span=(0, 3), match='a3h'> re.match("\w{5}","1sadfasdf11") 运行结果:<_sre.SRE_Match object; span=(0, 5), match='1sadf'> re.match("\w{5,}","1sadfasdf11") 运行结果:<_sre.SRE_Match object; span=(0, 11), match='1sadfasdf11'> re.match("\w{5,9}","1sadfasdf11") 运行结果:<_sre.SRE_Match object; span=(0, 9), match='1sadfasdf'> re.match(".*\\bliu\\b","i is liu fas fsa5 662 2a") # 注意为什么使用点 运行结果:<_sre.SRE_Match object; span=(0, 8), match='i is liu'> re.match(r".*\bliu\b","i is liu fas fsa5 662 2a") #结果同上 运行结果:<_sre.SRE_Match object; span=(0, 8), match='i is liu'> |
练习:匹配出qikux的邮箱地址,且@之前有4到20为字符,如59127_ljh@qikux.com
\w{4,20}@qikux\.com
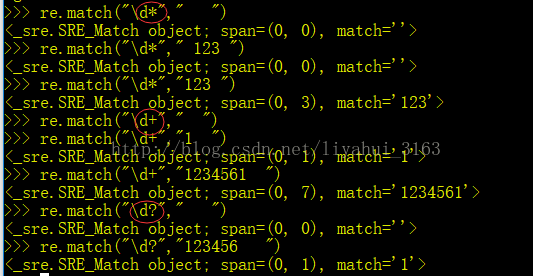
以上是对“*”,“+”,“?”的举例,将这三种符号添加至某要求后,说明可重复0到多次,或者1到多次,或者0或者1次。重复的字符为在“*”,“+”,“?”之前的如“\d”
5.反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
| 表3.常用的反义代码 | |
| 代码/语法 | 说明 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
案例如下:
| re.match("[^abcd]","a") #表示除a、b、c、d外的任何字符都匹配 re.match("[^abcd]","b") re.match("[^abcd]","e") |
6.分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作。
案例如下:
| re.match("100|[1-9][0-9]|[0-9]","2") # 匹配100以内的数 re.match("0|100|[1-9]?\d$","2") re.match("\d+(183|192|168)\s","452183 ") re.match("\d+(183|192|168)\s","452183 ").group() re.match("\d+(183|192|168)\s","452183 ").group(1) #注意当输入1的结果 re.match("\d+(183|192|168)\.(li|wang|liu)","452168.wang").group(2) re.match("(.*)-(\d+)","0931-5912872 ").group(2) #小括号的使用场景,特别方便 re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>","<a>liujianhong</a>") #看似正确,其实Error re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>","<a>liujianhong</html>") #这个就是漏洞 re.match(r"<([a-zA-Z] *)>\w*</ \1>","<a>liujianhong</html>") #此时\1表示第一个括号中的值 re.match("<([a-zA-Z] *)>\w*</ \\1>","<a>liujianhong</html>") #这样也 |
分组:即用圆括号将要提取的数据包住,通过 .group()获取,一般和“|”结合使用,可以用以下实例来讲述分组的应用场景:

7.后向引用(了解)
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。最好还是拿例子来说明吧:
| re.match(r"<(\w*)><(\w*)>.*</\2></\1>","<a><span>liujianhong</span></a>") re.match(r"<(?P<n1>\w*)><(?P<n2>\w*)>.*</(?P=n2)></(?P=n1)>","<a><span>liujiang</span></a>") |
注意:?P<name> 和?P=name中的P必须大写。















 4223
4223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









