







还是以前面文章提到的爬取智联招聘数据为例,首先分析一下网页特征,要爬取的数据职位名称、公司名称、职位月薪这些数据是直接渲染在网页中的,所谓的深度爬取则是在只抓取一个url的情况下获取该页面上其他页面的链接,然后将这些url加入到urljoin()中进行一一爬取。
以下是简单的scrapy框架的底层图解:

1.首先,让我们先创建一个scrapy项目:
python2 -m scrapy startproject myspider
项目结构如下:
--myspider
--myspider
--spiders
--__init__.py
--__init__.py
--items.py # 数据类型模块
--middlewares.py
--settings.py # 设置模块
--pipelines.py # 管道模块,用于数据的保存
--scrapy.cfg
在这里,我们再来回忆一下在scrapy框内部是如何运行的
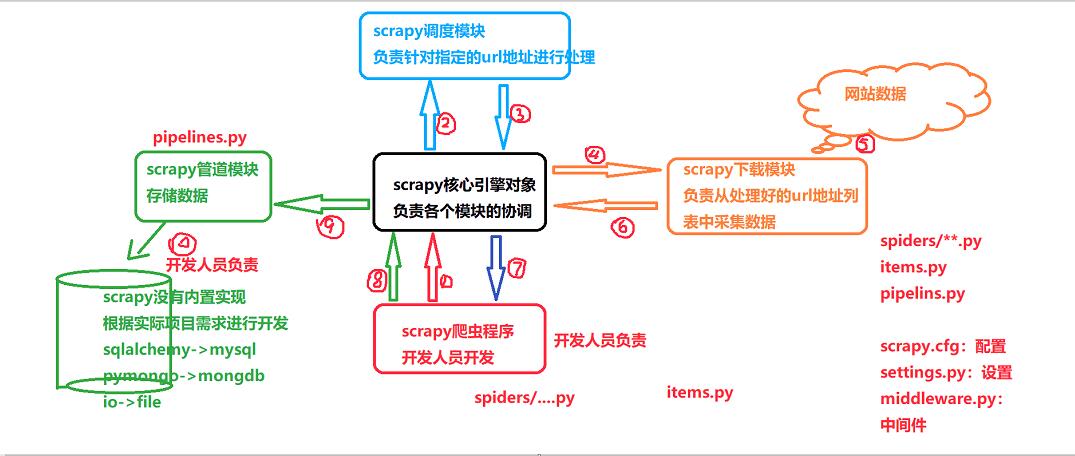
2.分析采集数据的字段,将其封装在items.py文件中
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MyspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class ZhilianItem(scrapy.Item): ''' 在item文件中定义获取数据的字段,该类型继承自srapy.item, ''' job_name=scrapy.Field() company=scrapy.Field() salary=scrapy.Field()
3.编写爬虫程序myspider/myspider/spiders/zhilian_spider.py
# -*-coding:utf-8 -*- ''' 为了可以直接使用scrapy内置的爬虫操作,让scrapy自动采集数据,我们需要定义一个爬虫处理类 在spiders/zhilianspider.py模块中定义ZhilianSpider类型,继承自scrapy.Spider 类型中的属性:name属性~爬虫名称,用于在命令行启动爬虫时调用 类型中的属性:start_urls属性~采集数据的初始url地址[列表、元组]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









