







神经网络代价函数
K:最终分类类的类别个数
L:神经网络层数
si:第i层中的单位数量(不包括偏差单位)
我们已知逻辑回归代价函数的一般形式,神经网络最后一层的分类算法也可以是逻辑回归。最后一层是K个分类目标函数,约束条件的参数在L层中每个映射均有对应的约束参数,对目标函数累加值求均值,以及对参数的正则项约束条件,可得神经网络的代价函数。
双重总和只是将输出层中每个单元计算的逻辑回归成本相加
三重和只是将整个网络中所有单个Θ的平方相加。
我在三重总和中并没有提到训练例子i

J(θ)训练过程,对θ求偏导,进行迭代回归,使J(θ)与y输出的方差最小,证明过程可参考:
https://blog.csdn.net/starzhou/article/details/52687609
证明过程如下
梯度下降过程如下:

反向传播算法如下:

证明过程如下

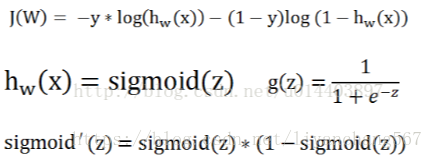

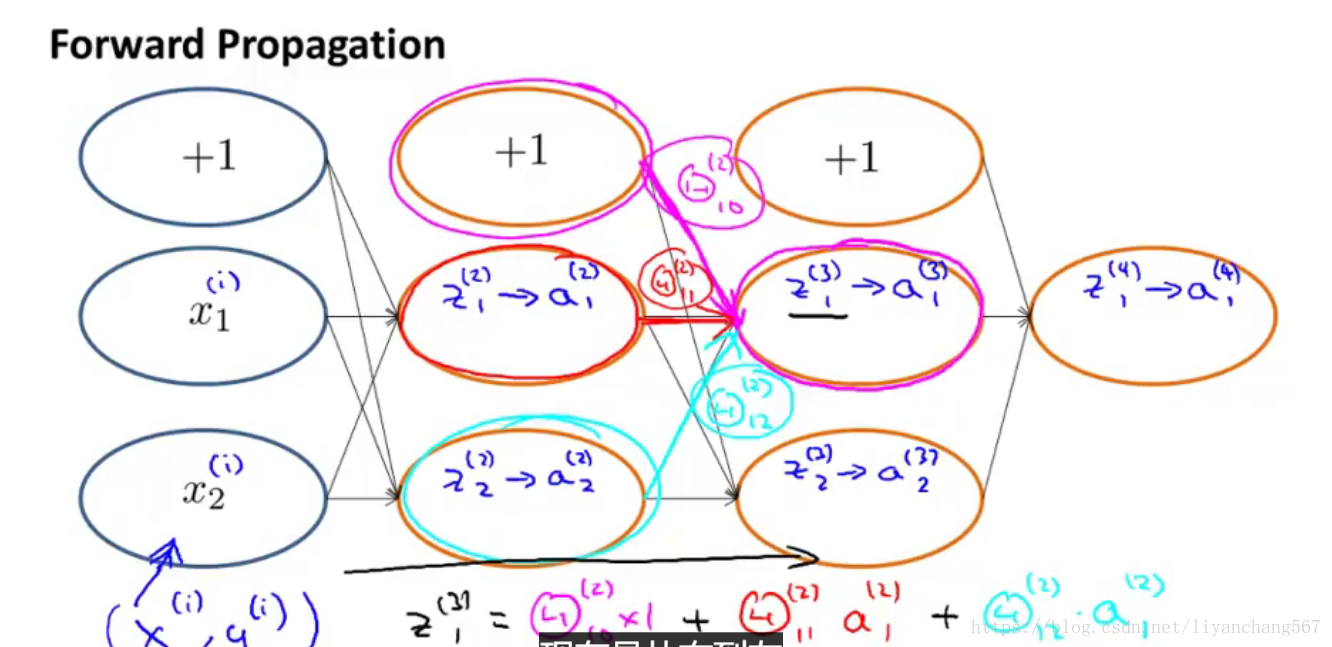
前向传播算法过程:
代价函数

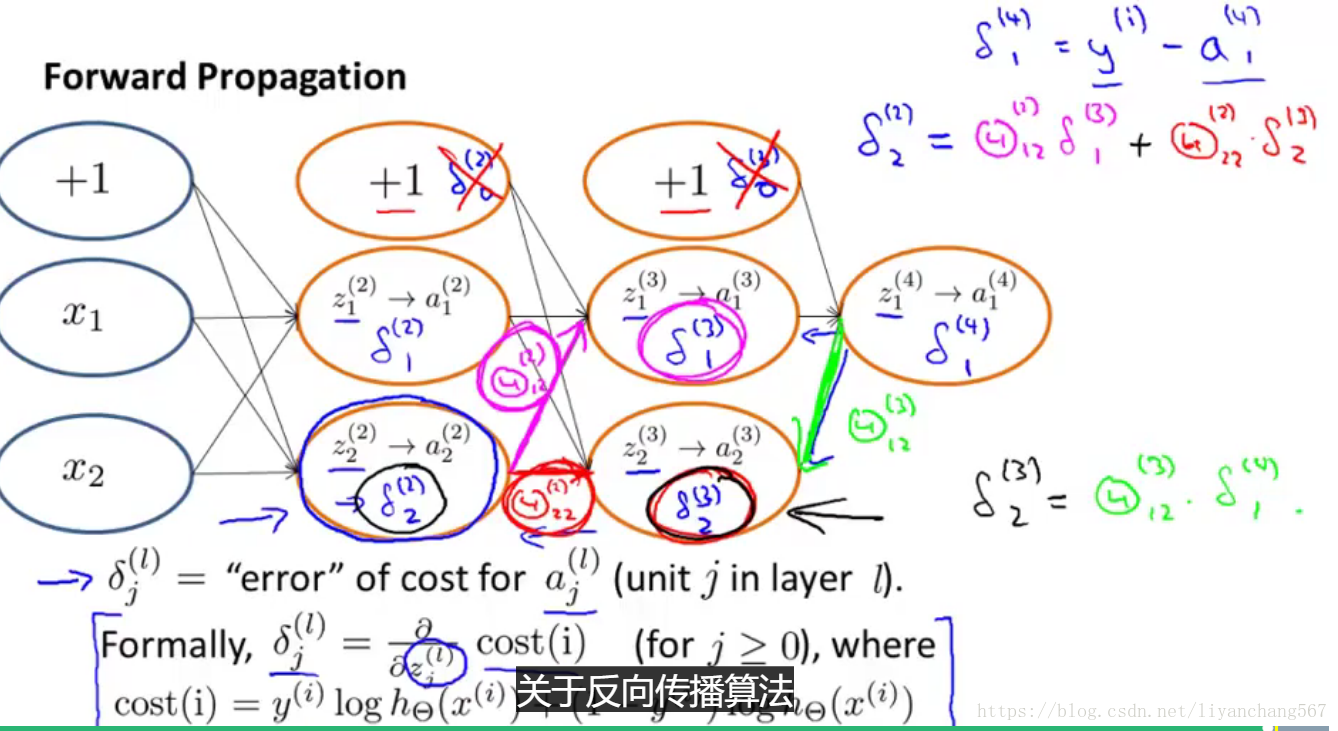
反向传播算法过程如下:
向量和矩阵方式的高级优化算法

使用矩阵表达的好处: 当你的参数以矩阵的形式储存时 你在进行正向传播 和反向传播时 你会觉得更加方便 当你将参数储存为矩阵时 一大好处是 充分利用了向量化的实现过程
向量表达式的优点:如果你有像thetaVec或者DVec这样的矩阵 当你使用一些高级的优化算法时 这些算法通常要求 你所有的参数 都要展开成一个长向量的形式
展开矩阵成为长向量和重新构建向量举例


梯度下降检验法
对代价函数进行双边求导

octave程序实现过程

反向传播是个非常高效的算法,得到的DVEC是个近似值
梯度下降法gradApprox是个迭代的精确值,但是迭代速度和计算量是很大的
在验证了DVEC计算正确之后就可以调整关闭梯度下降法,使用反向传播的算法计算
梯度下降要注意初始值,在逻辑回归可以领theta初始值为0,在神经网络中要避免矩阵对称导致的权重值相等

举例如下
If the dimensions of Theta1 is 10x11, Theta2 is 10x11 and Theta3 is 1x11.
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
神经网络的流程
随机初始化权重
对任何x实施正向传播以得到
实施成本函数
实施反向传播以计算偏导数
使用梯度检查来确认您的反向传播工作。 然后禁用梯度检查。
使用梯度下降或内置优化功能,以theta中的权重最小化成本函数。














 1509
1509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









