







 本文详细介绍了神经网络中的成本函数和反向传播算法。在成本函数部分,讨论了二分类和多分类问题的成本函数。接着,解释了反向传播(BackPropagation)的基本原理,包括神经网络的结构、残差的定义以及如何计算每个层的误差δ。通过伪代码展示了BP算法的实现过程,并在实践中给出了简化神经网络成本函数的情况、误差计算以及初始化参数的重要性。最后,提到了训练神经网络时的梯度检查和随机初始化参数的必要性。
本文详细介绍了神经网络中的成本函数和反向传播算法。在成本函数部分,讨论了二分类和多分类问题的成本函数。接着,解释了反向传播(BackPropagation)的基本原理,包括神经网络的结构、残差的定义以及如何计算每个层的误差δ。通过伪代码展示了BP算法的实现过程,并在实践中给出了简化神经网络成本函数的情况、误差计算以及初始化参数的重要性。最后,提到了训练神经网络时的梯度检查和随机初始化参数的必要性。
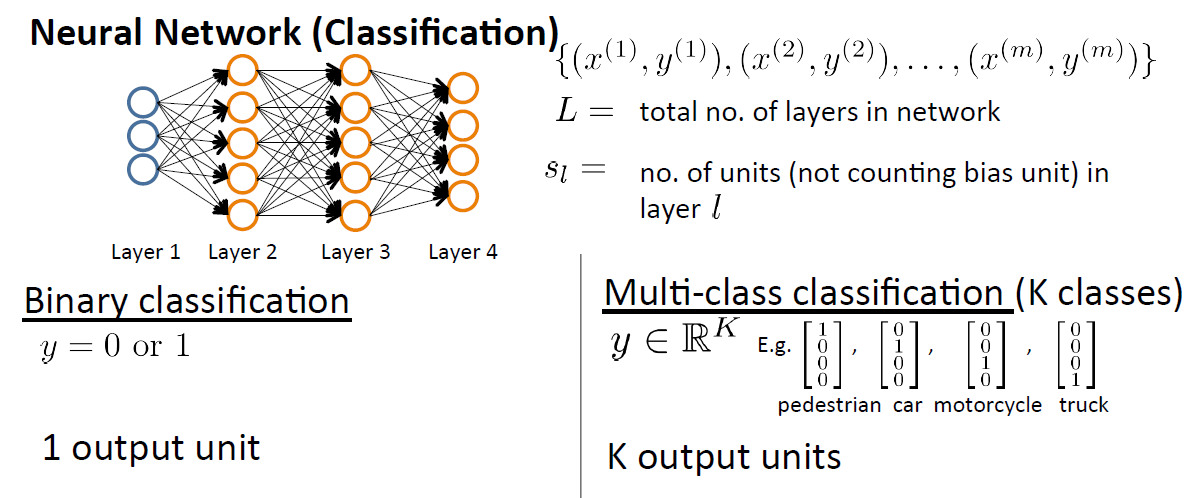
Cost Function and Backpropagation
假设有样本m个。 x(m) 表示第m个样本输入, y(m) 表示第m个样本输出, L 表示网络的层数,
当遇到二分问题时,
SL=1,y=0or1
,
遇到K分类问题时,
SL=K,yi=1
例如遇到5分类问题时,输出并不是 y=1,y=2,...y=5 这类,而是标记成向量形式 [10000]T,[01000]T.....[00001]T
我们先看Logistic Regression Cost Function:
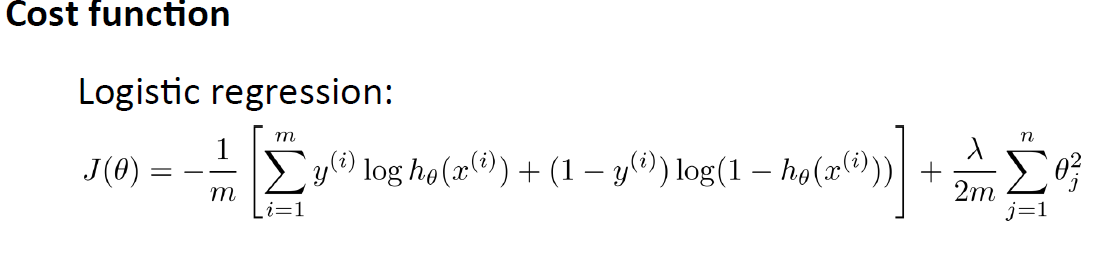
m表示样本个数,前半部分表示假设与样本之间的误差之和,后半部分是正则项(不包括bias terms)
logistic regression一般用于二分类,所以cost function写成上式,那么神经网络的Cost Function如何写呢?它可是K分类( K≥2 ),由上述 J(θ) 推广,我们可以得到如下:
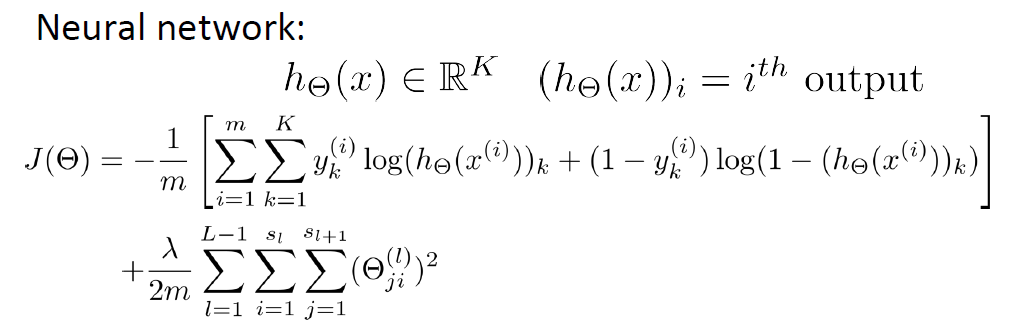
其实,就是在上述的基础之上,对每个类的输出进行加和,后半部分是对bias项所有参数的平方和(不包括bias terms)
从第四周的课程当中,我们已经了解到了向前传播(Forward Propagation),向后传播(BackPropagation)无非是方向相反罢了。
先简述一下BP神经网络,下图是神经网络的示意图:
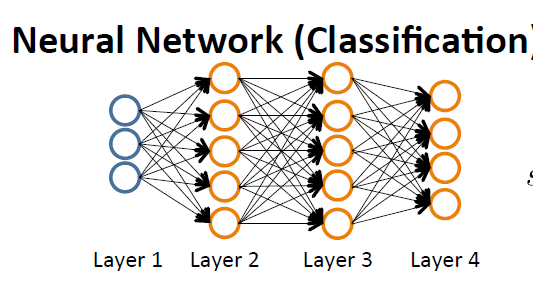
Layer1,相当于外界的刺激,是刺激的来源并且将刺激传递给神经元,因此把Layer1命名为输入层(Input Layer)。Layer2-Layer3,表示神经元相互之间传递刺激相当于人脑里面,因此命名为隐藏层(Hidden layers)。Layer4,表示神经元经过多层次相互传递后对外界的反应,因此Layer4命名为输出层(Output Layer)。
简单的描述就是,输入层将刺激传递给隐藏层,隐藏层通过神经元之间联系的强度(权重)和传递规则(激活函数)将刺激传到输出层,输出层整理隐藏层处理的后的刺激产生最终结果。若有正确的结果,那么将正确的结果和产生的结果进行比较,得到误差,再逆推对神经网中的链接权重进行反馈修正,从而来完成学习的过程。这就是BP神经网的反馈机制,也正是BP(Back Propagation)名字的来源:运用向后反馈的学习机制,来修正神经网中的权重,最终达到输出正确结果的目的!
那么,算法是如何实现的呢?如何向后传播呢?
在BackPropagation中,定义了一个:

表示l层节点j的残差,残差是指实际观察值与估计值(拟合值)之间的差。
那么
δ(l)j
是如何得到的呢?
由上面提到的定义:残差是指实际观察值与估计值(拟合值)之间的差,那么对于Layer4而言 δ(4)j=a(4)j−yj ,其中 a(4)j 表示拟合值, yj 表示实际观察值,要得到 a(4)j ,我们需要通过
Forward Propagation:
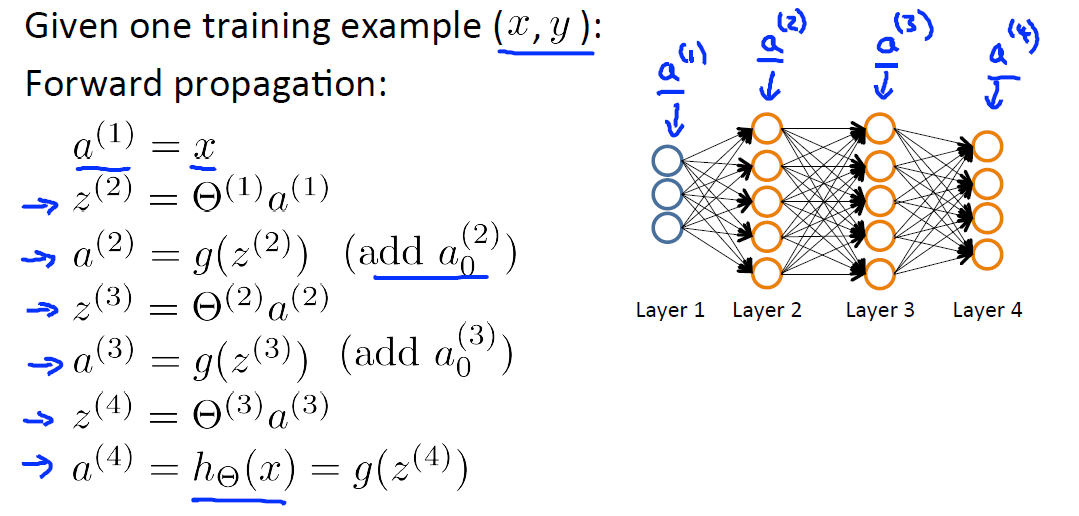
对于
δ(3)j,δ(2)j
:
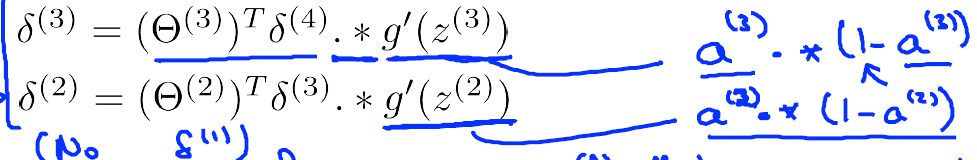
由此,我们得到计算 δ 的方式,下面来看BP算法的伪代码:

ps:最后一步之所以写+=而非直接赋值是把Δ看做了一个矩阵,每次在相应位置上做修改。
从后向前此计算每层依的δ,用Δ表示全局误差,每一层都对应一个Δ(l)。再引入D作为cost function对参数的求导结果。下图左边j是否等于0影响的是否有最后的bias regularization项。左边是定义,右边可证明(比较繁琐)。

Backpropagation in Practice
1.向前传播 Forward propagation,得到每个权重 θ ,若有疑惑可参考 第四周课程
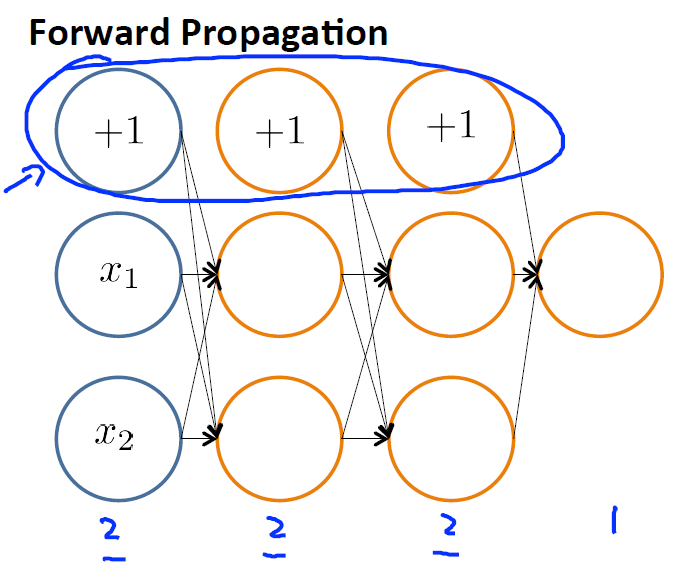
PS:bias units 并不算在内。所以1,2,3层的神经元个数为2,而不是3
2.简化神经网络的代价函数(去除正则项,即
λ=0
)
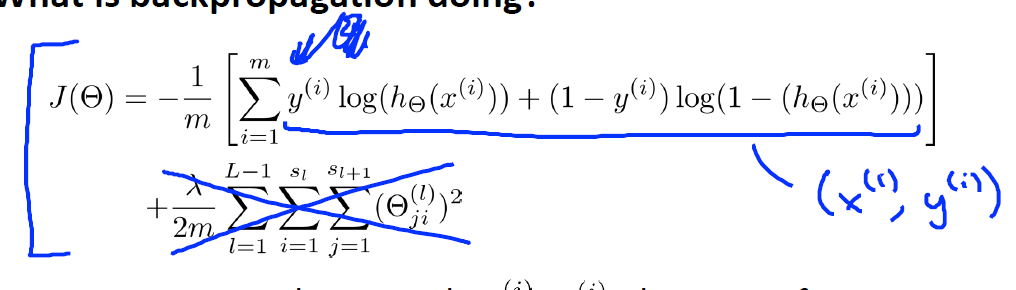
我们仅关注一个样本
(x(i),y(i))
,并且仅针对一个输出单元的神经网络(上例),这样Cost function可以简化为如下的形式:
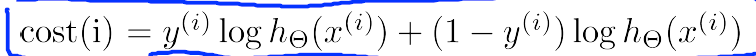
3.计算误差
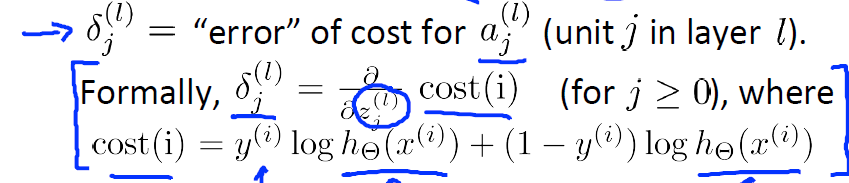
δ(l)j
记为l层神经元j的误差
BP算法主要是从输出层反向计算各个节点的误差的,故称之为反向传播算法,对于上例,计算的过程如下图所示:
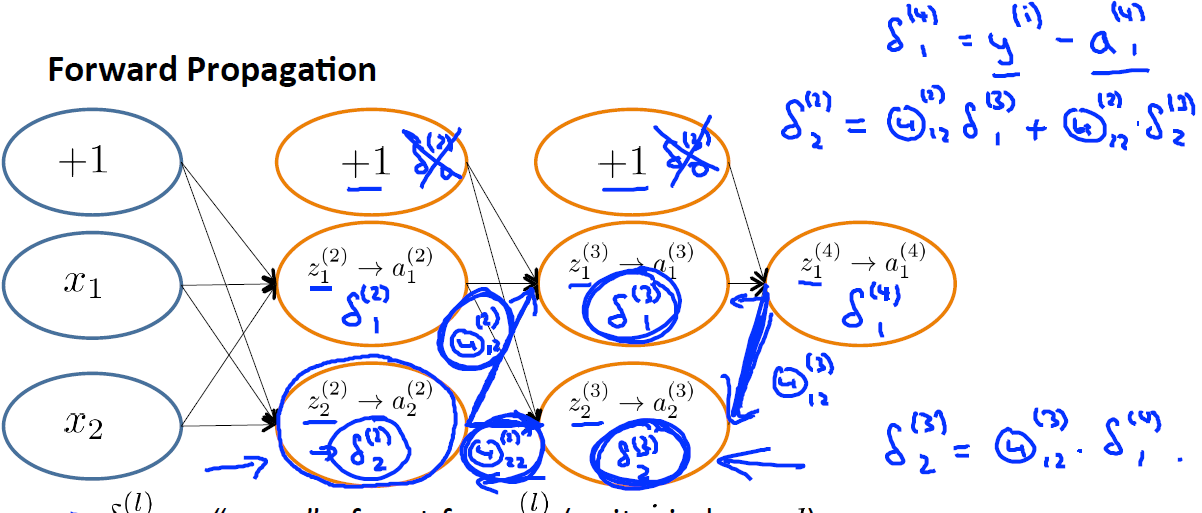
换句话说, 对于每一层来说,
δ
分量都等于后面一层所有的
δ
加权和,其中权值就是参数
θ
。
这节主要是讲参数的向量化,以及将其还原

具体不懂可以实践一下。
神经网络中的参数很多,如何检测自己所编写的代码是否正确?
对于下面这个 θ−J(θ) 图,取Θ点左右各一点 (θ+ε),(θ−ε) ,则有点 θ 的导数(梯度)近似等于 J(θ+ε)−J(θ−ε)/(2ε)
对于每个参数的求导公式如下图所示

由于在back-propagation算法中我们一直能得到J(Θ)的导数D(derivative),那么就可以将这个近似值与D进行比较,如果这两个结果相近就说明code正确,否则错误,如下图所示:

实现时的注意点:
- 首先实现反向传播算法来计算梯度向量DVec;
- 其次实现梯度的近似gradApprox;
- 确保以上两步计算的值是近似相等的;
- 在实际的神经网络学习时使用反向传播算法,并且关掉梯度检查。
特别重要的是:
一定要确保在训练分类器时关闭梯度检查的代码。如果你在梯度下降的每轮迭代中都运行数值化的梯度计算,你的程序将会非常慢。
如何初始化参数向量or矩阵。通常情况下,我们会将参数全部初始化为0,这对于很多问题是足够的,但是对于神经网络算法,会存在一些问题,以下将会详细的介绍。
对于梯度下降和其他优化算法,对于参数
θ
向量的初始化是必不可少的。能不能将初始化的参数全部设置为0:

看下图,如果将参数全设置为0
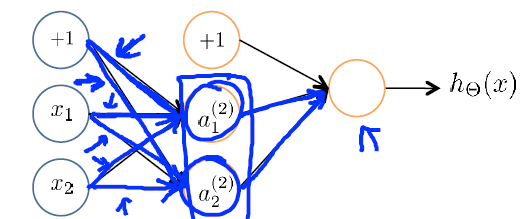
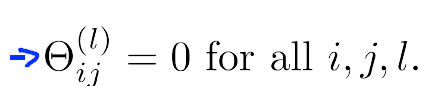
会导致一个问题,例如对于上面的神经网络的例子,如果将参数全部初始化为0,在每轮参数更新的时候,与输入单元相关的两个隐藏单元的结果将是相同的,
因此,我们需要随机初始化:

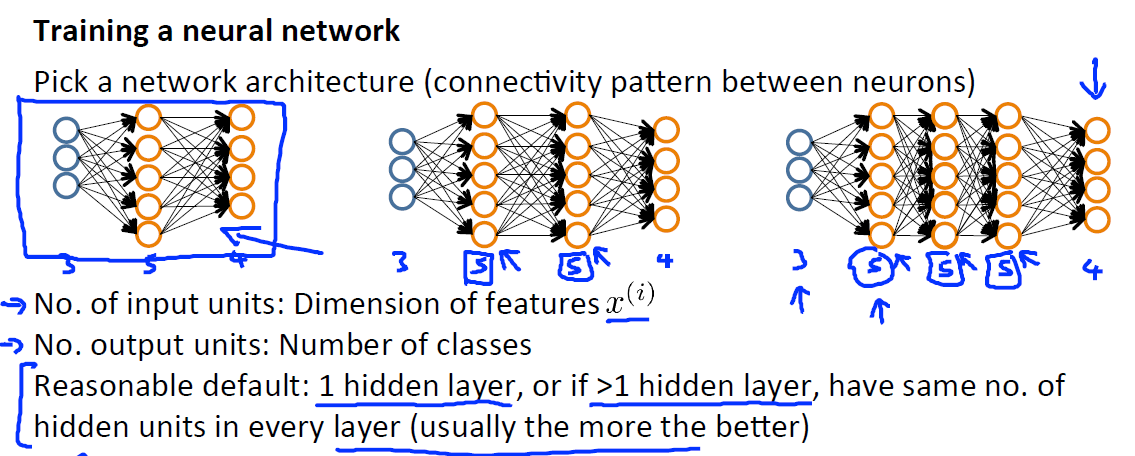
首先需要确定一个神经网络的结构-神经元的连接模式, 包括:
输入单元的个数:特征
x(i)
的维数;
输出单元的格式:类的个数
隐藏层的设计:比较合适的是1个隐藏层,如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。


在确定好神经网络的结构后,我们按如下的步骤训练神经网络:
随机初始化权重参数;
实现:对于每一个 x(i) 通过前向传播得到 hθ(x(i)) ;
实现:计算代价函数 J(θ) ;
实现:反向传播算法用于计算偏导数 ϑϑΘ(l)jkJ(Θ)
使用梯度检查来比较反向传播算法计算的 ϑϑΘ(l)jkJ(Θ) 和数值估计的 J(θ) 的梯度,如果没有问题,在实际训练时关闭这部分代码;
在反向传播的基础上使用梯度下降或其他优化算法来最小化 J(θ) ;
参考:http://blog.csdn.net/abcjennifer/article/details/7758797
http://52opencourse.com/174
http://blog.sina.com.cn/s/blog_88f0497e0102v79c.html















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









