







声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。文章同列统计可访问。http://yqli.tech/page/tts_paper.html
如有转载,请标注来源。 欢迎关注微信公众号:低调奋进
RW-Resnet: A Novel Speech Anti-Spoofing Model Using Raw Waveform
本文为上海大学在2021.08.12更新的文章,本篇文章主要使用原始波形做反欺诈的研究,具体的文章链接https://arxiv.org/pdf/2108.05684.pdf
1 研究背景
语音合成的进步给说话人验证(SV)系统造成挑战,因此应对合成语音的反欺诈技术也逐渐成为了热点。以前的Anti-Spoofing的系统输入的特征需要使用第三方的工具进行特征提取,本文的主要特点是直接对原始的音频数据进行处理,使其性能得到提升。
2 详细设计
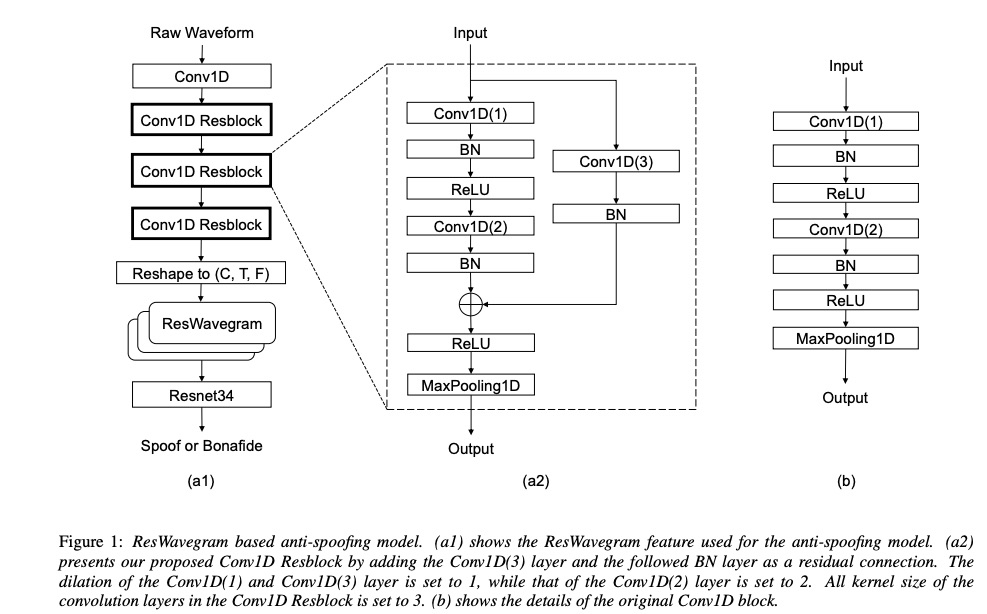
图一为整个系统的RW-Resnet的结构,其主要包括两个部分:ResWaveGram和Resnet34。其中ResWavegram的职能为特征提取,其使用的conv1D Resblock如图a2所示,相较图b来说添加了一层conv1D(3)-BN进行res连接,使其信息更好表征音频。Resnet34主要对表征的信息进行判别。
3 实验
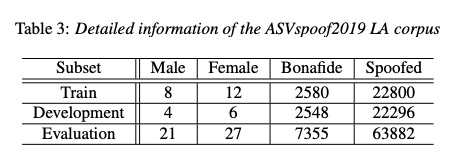
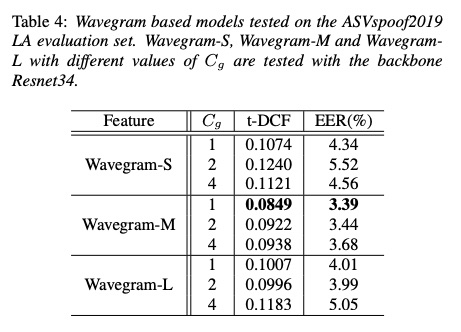
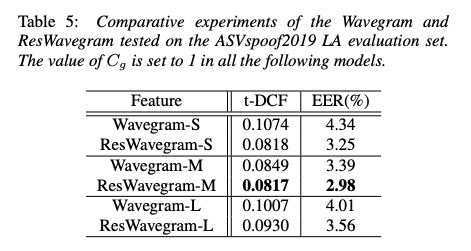
本文的实验数据如table 3所示。其中table 4展示了不同参数量对结果(t-DCF和EER指标,指标越低越好)影响.table5对比是否使用res对系统的影响,使用功res方式更好。table6和table7和现有系统对比。
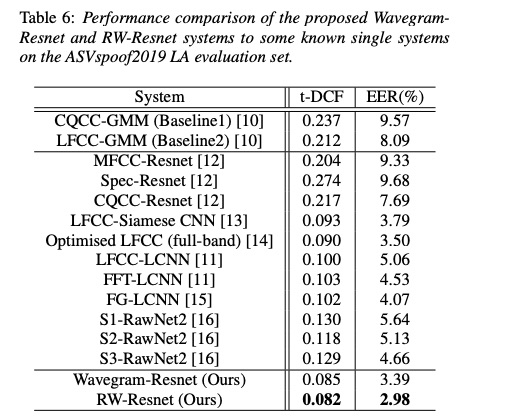
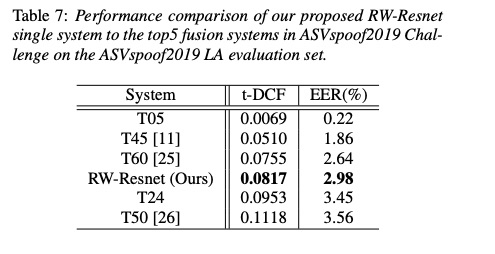
4 总结
针对合成语音技术对说话人验证系统造成的挑战,本文设计直接使用原始音频的模型RW-Resnet进行Anti-Spoofing,使其表现优异。
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











