







声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
Wav2Vec2.0 on the Edge: Performance Evaluation
本文为Meta Inc在2022.02.12更新的文章,主要进行wav2vec2.0在边缘设备上的性能测试,具体的文章链接
https://arxiv.org/pdf/2202.05993.pdf
(本文主要是实验结果分享,我给总结成实验报告形式,结果仅供参考)
1 实验背景和目的
Wav2Vec2.0 是通过无监督学习Self-supervised learning对音频进行表征学习,其学习的表征信息供下游的语音识别等任务使用,如图1所示。过往的研究还没有对Wav2Vec2.0在边缘设备上进行性能测试,因此本文主要分享该实验成果。
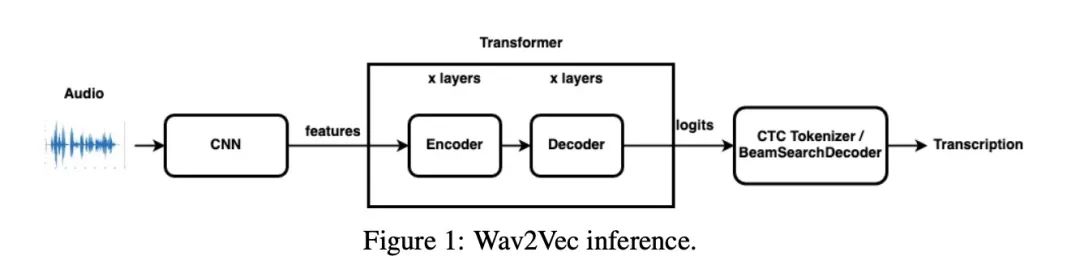
2 实验设置
本文实验的整套方案是在PyTorch生态上进行,其量化等操作都是其生态api。该实验的模型准备如图2所示,图3和图4展示测试流程。实验数据为LibriSpeech,实验使用的lm为KenLM。实验设备Raspberry Pi 的配置如table 1所示。实验的指标包括
accuracy(WER), latency(RTF) and efficiency(CPU, memory and power consumption)。



3 实验结果
首先看一下语音识别的WER指标如table 2所示,有了语言模型,WER 至少比没有语言模型的 WER 好 30 %。beam size 100 至少有 ∼3 % 的改进。使用量化语言模型WER 比不使用语言模型的好 ∼25 %。

接下来看一下RTF,核数越多rtf越小,但3核和4核差别不大,都勉强实时。图5到图8展示了能量开销,系统稳态为∼ 3.1W,则每增加一核开销∼ 1.1W, ∼ 1.7W, ∼ 2.3W and ∼ 2.9W 。图9和图10对比量化和非量化模型的能源开销。图11和图12为内存开销和cpu占用情况,可以看到使用语言模型的内存占用增加较大。





4 总结
本文评估在边缘设备树莓派上的 Wav2Vec 模型推理性能,其RTF勉强达到实时。 通过使用语言模型,模型的准确率提高了∼30%,但增加了约 200% 内存成本。 通过使用量化语言模型,内存占用可以大大减少。 模型量化比未量化模型的能源开销低约 27%。















 3507
3507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











