







前言:
生活中,人们经常会遇到各种最优化问题,比如如何在最短时间从一个地点到另外一个地点?如何在投入最少的资金而却能得到最高的受益?如何设计一款芯片使其功耗最低而性能最好?这一节就要学习一种最优化算法——Logistic回归,设计最优化算法的目的依然是用于分类。在这里,Logistic回归的主要思想是根据现有的数据对分类边界线建立回归公式,达到分类的目的。假设我们有一堆数据,需要划一条线(最佳直线)对其分类,这就是Logistic回归的目的。
而“Logistic回归”中的“回归”又是代表什么?数学认为,回归是一个拟合过程,回归分析本质上就是一个函数估计的问题,就是找出因变量和自变量之间的因果关系。具体到例子,假设我们有一些数据点,现在使用一条直线对这些点进行拟合,使得这条线尽可能地表示数据点的分布,这个拟合过程就称作“回归”。
在机器学习任务中,训练分类器时就是寻找最佳拟合曲线的过程,因此接下来将使用最优化算法。在实现算法之前,先总结Logistic回归的一些属性:
- 优点:计算代价不高,易于理解和实现
- 缺点:容易欠拟合,分类精度可能不高
- 适用的数据类型:数值型和标称型数据
目录:
一、基于Sigmoid函数的Logistic回归
- Sigmoid函数
- 基于最优化方法的最佳回归系数确定
- 梯度上升法的实现
- 随机梯度上升算法的实现
二、一个实例:从疝气病症预测病马的死亡率
- 准备数据
- 测试算法,使用Logistic回归进行分类
三、总结
===============================================
一、基于Sigmoid函数的Logistic回归
1.Sigmoid函数
Logistic回归想要得到的函数是,能接受所有的输入然后返回预测的类别,比如,在两类情况下函数应输出类别0或1。sigmoid函数可是胜任这一工作,它像是一个阶跃函数。其公式如下:
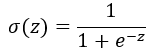
其中:
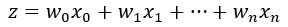
向量w称为回归系数,也就是我们要找到的最佳参数, x是n维的特征向量,是分类器的输入数据。
下面附上书本上的图,该图是函数在不同坐标尺度下的曲线图:
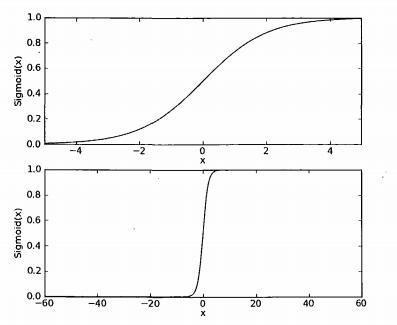
为了实现Logistic回归分类器,我们可以在每个特征上乘以一个回归系数,然后把所有的结果值相加,将这个总和结果代入sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5的数据被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
2.基于最优化方法的最佳回归系数确定
上面提到Sigmoid函数里的一部分:
其中向量w称为回归系数,也就是我们要找到的最佳参数, x是n维的特征向量,是分类器的输入数据。接下来将介绍几种需找最佳参数的方法:
- 梯度上升法:基于的思想是要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。
- 梯度下降法:与梯度上升的思想相似,但方向相反,即如果要找到某函数的最小值,最好的方法是沿着该函数的梯度方向的反方向寻找。
这里使用梯度上升法,对于一个函数f(x,y),其梯度表示方法如下:
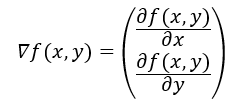
该梯度意味着要沿x和y的方向分别移动一定的距离,这其实是确立了算法到达每个点后下一步移动的方向。其中,函数f(x,y) 必须要在待计算的点上有定义并且可微。
移动方向确定了,这里我们定义移动的大小为步长,用α表示,用向量来表示的话,梯度上升算法的迭代公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









