






近期在学习李沐《动手学深度学习》课程中,一直对.sum().backward()不求甚解,看了别人的博客,也只是会了y = x²这种例子的梯度,而对于像y = Xw + b这种的就不太清楚具体梯度如何得来,尤其是X,w均为矩阵的情况就令人更加头疼。
这篇文章是我在弄懂上述y = Xw + b后写出,希望对你们有所帮助。
首先,我们清楚,对于常数b而言,不影响梯度的计算,因此,下面的例子为了简化,我们就不再加上b这一项,即y = Xw .
1.一维简单示例
1.导包
import torch
from d2l import torch as d2l对李沐课程熟悉的同学,对d2l包也应该不会陌生。
2.生成真实数据
X = torch.tensor([[1.,2.,3.]])
true_w = torch.ones(3).reshape(3,-1)
y = torch.matmul(X, true_w)X是1*3的矩阵,真实权重true_w定义为3*1的全1向量。
这时,我们打印y,得出y = X*true_w的结果
y: tensor([[6.]])3.生成预测数据
预测数据我们使用y_hat来表示,w用正态分布产生的随机数表示,注意,我们最后要对w求梯度,因此要加上requires_grad = True。
w = torch.normal(0,1,size=(3, 1), requires_grad=True)
y_hat = torch.matmul(X, w)打印y_hat,得y = X * w的结果
y_hat: tensor([[-2.1865]], grad_fn=<MmBackward0>)4.定义损失
用最简单的L2范数定义损失:
loss = (y_hat - d2l.reshape(y, y_hat.shape))**2 / 2打印loss看结果
loss: tensor([[33.5093]], grad_fn=<DivBackward0>)当然,我们也可以手动验证一下,loss = (-2.1865-6.)^2 / 2= 33.509391125,与打印的loss相同,验证成功。
5.求w梯度
loss.sum().backward()
print(w.grad)对loss进行反向传播,然后打印w梯度,看看结果:
tensor([[ -8.1865],
[-16.3730],
[-24.5595]])这些梯度怎么来的呢?我们画一下计算图:
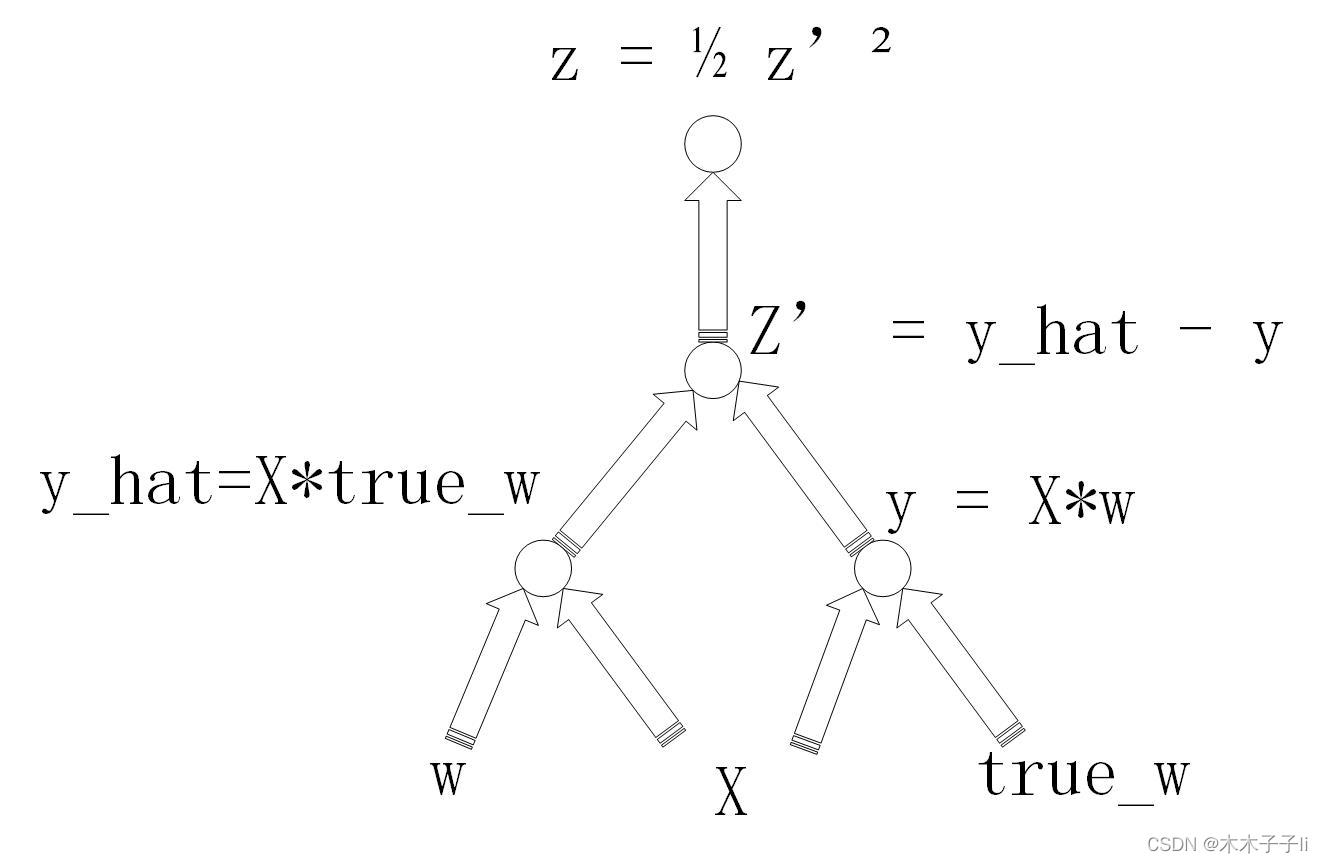
由链式法则不难得出:
那么,我们的z'表示什么?就是y_hat - y,换成数据就是-2.1865 - 6 = -8.1865
那么根据公式,我们的梯度就是-8.1865*[1,2,3] 就是我们打印出的w梯度,共有三个。
2.二维示例
现在加大X维数,其余条件不变。
'''
生成真实数据
'''
X = torch.tensor([[1.,2.,3.],[4.,5.,6.]])
true_w = torch.ones(3, requires_grad=True).reshape(3,-1)
true_w.retain_grad()
y = torch.matmul(X, true_w)
print('y:', y)
'''
生成y_hat
'''
w = torch.normal(0,1,size=(3,1), requires_grad=True)
y_hat = torch.matmul(X, w)
print('y_hat:', y_hat)
'''
定义损失
'''
loss = (y_hat - d2l.reshape(y, y_hat.shape))**2 / 2
print('loss:', loss)
loss.sum().backward()
print('w.grad:', w.grad)
我们直接看运行结果:
y: tensor([[ 6.],
[15.]], grad_fn=<MmBackward0>)
y_hat: tensor([[ -6.0518],
[-13.1038]], grad_fn=<MmBackward0>)
loss: tensor([[ 72.6224],
[394.9125]], grad_fn=<DivBackward0>)
w.grad: tensor([[-124.4671],
[-164.6226],
[-204.7782]])
那么结合我们在第一章的内容,这里w怎么计算呢?
根据链式法则公式,
然后我们乘以X的列向量,
与我们输出的w的梯度一致。
3.存疑
从运行结果看出,我们的结果是行向量,而程序结果是列向量,猜测是backward()内部实现方法导致的,但并不影响理解backward()计算,待之后搞懂行列如何变换,再来补充这一部分知识。

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









