










目录

(一)构建过程
方法1:

requires_grad: 如果需要为张量计算梯度,则为True,否则为False。我们使用pytorch创建tensor时,可以指定requires_grad为True(默认为False),
方法2:

接下来得到损失函数:y=kx+b,下面的这段解释保证是理论界的精华所在:
b=torch.randn(3,4,requires_grad=True)# 缺失情况下默认 requires_grad = False
t=x+b
y=t.sum()
##由于t是直接创建的,所以它没有grad_fn,而y是通过一个加法操作创建的,所以y有grad_fn,y的类型为:grad_fn=<SumBackward0>
##像x这种直接创建的称为叶子节点,叶子节点对应的grad_fn是None。
y
tensor(-2.1310, grad_fn=<SumBackward0>)
##y此时为损失函数
y.backward()#调用反向传播,使用backward()方法后,就可以查看x的梯度值
b.grad
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])
注意:
grad_fn: grad_fn用来记录变量是怎么来的,方便计算梯度
grad:当执行完了backward()之后,通过x.grad查看x的梯度值。grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
下面举个例子,来学习一下这个东西:
(二)代码实现过程
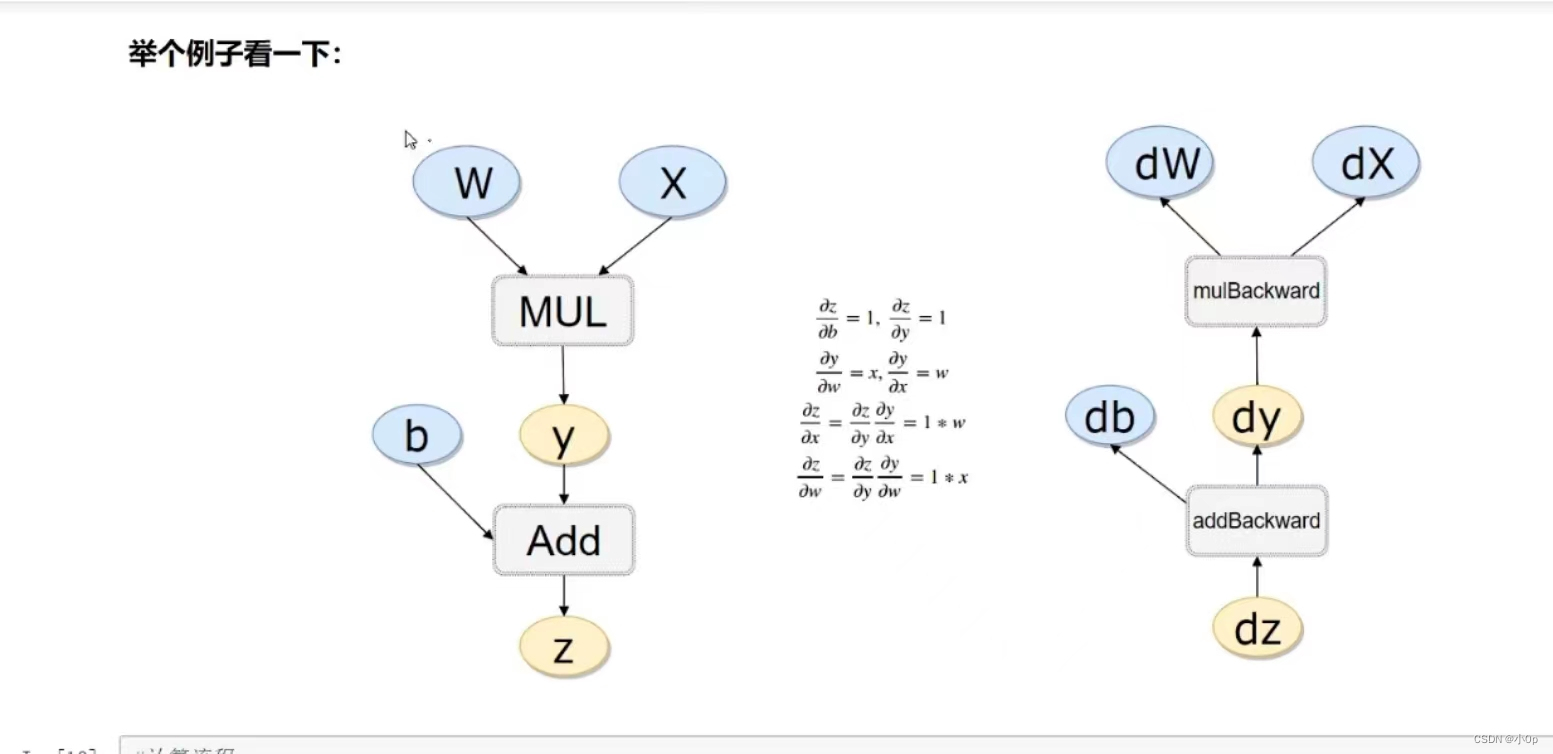
下面构建损失函数y=wx+b
x=torch.randn(1)
b=torch.rand(1,requires_grad=True)
w=torch.rand(1,requires_grad=True)
y=w*x
z=y+b需要计算张量计算梯度时结果为True,不需要计算张量梯度时结果为False
x.requires_grad,b.requires_grad,w.requires_grad,y.requires_grad,
(False, True, True, True)判断某个节点是否为叶子
x.is_leaf,b.is_leaf,w.is_leaf,y.is_leaf,z.is_leaf
(True, True, True, False, False)检验一哈,x,b,w确实为叶子,y,z不是叶子
执行backward()
z.backward(retain_graph=True)这样可以计算梯度值。
w.grad
tensor([-3.3664])
b.grad
tensor([4.])每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。当再次进行时:
z.backward(retain_graph=True)
w.grad
tensor([-4.2080])
b.grad
tensor([5.])
上面的梯度值可以累加。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









