






(一)数据不平衡处理_如何处理多类不平衡数据说不可以
数据不平衡处理
重点 (Top highlight)
One of the common problems in Machine Learning is handling the imbalanced data, in which there is a highly disproportionate in the target classes.
机器学习中的常见问题之一是处理不平衡的数据,其中目标类别的比例非常不均衡。
Hello world, this is my second blog for the Data Science community. In this blog, we are going to see how to deal with the multiclass imbalanced data problem.
大家好,这是我的第二本面向数据科学社区的博客 。 在此博客中,我们将看到如何处理多类不平衡数据问题。
什么是多类不平衡数据? (What is Multiclass Imbalanced Data?)
When the target classes (two or more) of classification problems are not equally distributed, then we call it Imbalanced data. If we failed to handle this problem then the model will become a disaster because modeling using class-imbalanced data is biased in favor of the majority class.
当分类问题的目标类别(两个或多个)没有平均分布时,我们称其为不平衡数据。 如果我们不能解决这个问题,那么该模型将成为灾难,因为使用类不平衡数据进行建模会偏向多数类。
There are different methods of handling imbalanced data, the most common methods are Oversampling and creating synthetic samples.
处理不平衡数据的方法多种多样,最常见的方法是过采样和创建合成样本。
什么是SMOTE? (What is SMOTE?)
SMOTE is an oversampling technique that generates synthetic samples from the dataset which increases the predictive power for minority classes. Even though there is no loss of information but it has a few limitations.
SMOTE是一种过采样技术,可从数据集中生成合成样本,从而提高了少数群体的预测能力。 即使没有信息丢失,它也有一些局限性。

Synthetic Samples 合成样品
Limitations:
局限性:
- SMOTE is not very good for high dimensionality data
SMOTE对于高维数据不是很好 - Overlapping of classes may happen and can introduce more noise to the data.
类的重叠可能会发生,并可能给数据带来更多的噪音。
So, to skip this problem, we can assign weights for the class manually with the ‘class_weight’ parameter.
因此,要跳过此问题,我们可以使用' class_weight '参数为该类手动分配权重。
为什么要使用班级重量? (Why use Class weight?)
Class weights modify the loss function directly by giving a penalty to the classes with different weights. It means purposely increasing the power of the minority class and reducing the power of the majority class. Therefore, it gives better results than SMOTE.
类权重通过对具有不同权重的类进行惩罚来直接修改损失函数。 这意味着有目的地增加少数群体的权力,并减少多数阶级的权力。 因此,它比SMOTE提供更好的结果。
概述: (Overview:)
I aim to keep this blog very simple. We have a few most preferred techniques for getting the weights for the data which worked for my Imbalanced learning problems.
我的目的是使这个博客非常简单。 我们有一些最优选的技术来获取对我的失衡学习问题有用的数据权重。
- Sklearn utils.
Sklearn实用程序。 - Counts to Length.
数到长度。 - Smoothen Weights.
平滑权重。 - Sample Weight Strategy.
样品重量策略。
1. Sklearn实用程序: (1. Sklearn utils:)
We can get class weights using sklearn to compute the class weight. By adding those weight to the minority classes while training the model, can help the performance while classifying the classes.
我们可以使用sklearn计算班级权重。 通过在训练模型时将这些权重添加到少数类中,可以在对类进行分类的同时帮助提高性能。
from sklearn.utils import class_weightclass_weight = class_weight.compute_class_weight('balanced,
np.unique(target_Y),
target_Y)model = LogisticRegression(class_weight = class_weight)
model.fit(X,target_Y)# ['balanced', 'calculated balanced', 'normalized'] are hyperpaameters whic we can play with.We have a class_weight parameter for almost all the classification algorithms from Logistic regression to Catboost. But XGboost has scale_pos_weight for binary classification and sample_weights (refer 4) for both binary and multiclass problems.
对于从Logistic回归到Catboost的几乎所有分类算法,我们都有一个class_weight参数。 但是XGboost具有用于二进制分类的scale_pos_weight和用于二进制和多类问题的sample_weights(请参阅4)。
2.数长比: (2. Counts to Length Ratio:)
Very simple and straightforward! Dividing the no. of counts of each class with the no. of rows. Then
非常简单明了! 除数 每个班级的人数 行。 然后
weights = df[target_Y].value_counts()/len(df)
model = LGBMClassifier(class_weight = weights)
model.fit(X,target_Y)3.平滑权重技术: (3. Smoothen Weights Technique:)
This is one of the preferable methods of choosing weights.
这是选择权重的首选方法之一。
labels_dict is the dictionary object contains counts of each class.
labels_dict是字典对象,包含每个类的计数。
The log function smooths the weights for the imbalanced class.
对数函数可平滑不平衡类的权重。
def class_weight(labels_dict,mu=0.15):
total = np.sum(labels_dict.values())
keys = labels_dict.keys()
weight = dict()for i in keys:
score = np.log(mu*total/float(labels_dict[i]))
weight[i] = score if score > 1 else 1return weight# random labels_dict
labels_dict = weights = class_weight(labels_dict)model = RandomForestClassifier(class_weight = weights)
model.fit(X,target_Y)4.样本权重策略: (4. Sample Weight Strategy:)
This below function is different from the class_weight parameter which is used to get sample weights for the XGboost algorithm. It returns different weights for each training sample.
下面的函数不同于用于获取XGboost算法的样本权重的class_weight参数。 对于每个训练样本,它返回不同的权重。
Sample_weight is an array of the same length as data, containing weights to apply to the model’s loss for each sample.
Sample_weight是与数据长度相同的数组,其中包含权重以应用于每个样本的模型损失。
def BalancedSampleWeights(y_train,class_weight_coef):
classes = np.unique(y_train, axis = 0)
classes.sort()
class_samples = np.bincount(y_train)
total_samples = class_samples.sum()
n_classes = len(class_samples)
weights = total_samples / (n_classes * class_samples * 1.0)
class_weight_dict = {key : value for (key, value) in zip(classes, weights)}
class_weight_dict[classes[1]] = class_weight_dict[classes[1]] *
class_weight_coef
sample_weights = [class_weight_dict[i] for i in y_train]
return sample_weights#Usage
weight=BalancedSampleWeights(
model = XGBClassifier(sample_weight = weight)
model.fit(X, class_weights vs sample_weight:
class_weights与sample_weight:
sample_weights is used to give weights for each training sample. That means that you should pass a one-dimensional array with the exact same number of elements as your training samples.
sample_weights用于给出每个训练样本的权重。 这意味着您应该传递一维数组,该数组具有与训练样本完全相同数量的元素。
class_weights is used to give weights for each target class. This means you should pass a weight for each class that you are trying to classify.
class_weights用于为每个目标类赋予权重。 这意味着您应该为要分类的每个类传递权重。
结论: (Conclusion:)
The above are few methods of finding class weights and sample weights for your classifier. I mention almost all the techniques which worked well for my project.
上面是为分类器找到分类权重和样本权重的几种方法。 我提到几乎所有对我的项目都有效的技术。
I’m requesting the readers to give a try on these techniques that could help you, if not take it as learning 😄 it may help you another time 😜
我要求读者尝试这些可以帮助您的技术,如果不以学习为learning,那可能会再次帮助您😜
Reach me at LinkedIn 😍
在LinkedIn上到达我
翻译自: https://towardsdatascience.com/how-to-handle-multiclass-imbalanced-data-say-no-to-smote-e9a7f393c310
(二)不用SMOTE算法,我们如何处理多类不平衡数据?
本文转载自公众号“读芯术”(ID:AI_Discovery)。
机器学习中的一个常见问题是处理不平衡数据,其中目标类中比例严重失调,存在高度不成比例的数据。
什么是多类不平衡数据?
当分类问题的目标类(两个或两个以上)不均匀分布时,称为不平衡数据。如果不能处理好这个问题,模型将会成为灾难,因为使用类不平衡数据建模会偏向于大多数类。处理不平衡数据有不同的方法,最常见的是过采样(Oversampling)和创建合成样本。
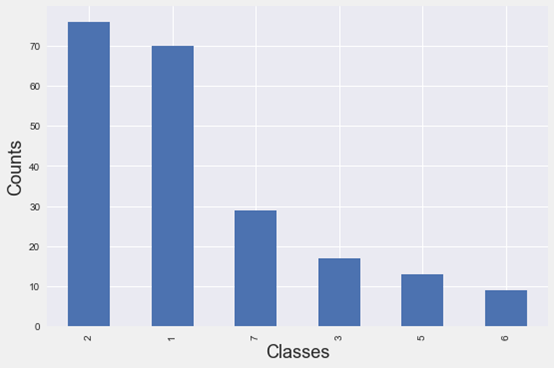
什么是SMOTE算法?
SMOTE是一种从数据集生成合成算例的过采样技术,它提高了对少数类的预测能力。虽然没有信息损失,但它有一些限制。
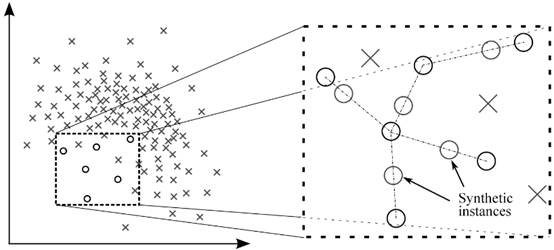
合成样本
限制:
- SMOTE不适用于高维数据。
- 可能会发生类的重叠,并给数据带来更多干扰。
因此,为了跳过这个问题,可以使用'class_weight '参数手动为类分配权重。
为什么使用类别权重(Class weight)?
类别权重通过对具有不同权重的类进行惩罚来直接修改损失函数,有目的地增加少数阶级的权力,减少多数阶级的权力。因此,它比SMOTE效果更好。本文将介绍一些最受欢迎的获得数据的权重的技术,它们对不平衡学习问题十分奏效。
(1) Sklearn utils
可以使用sklearn来获得和计算类权重。在训练模型的同时将这些权重加入到少数类别中,可以提高类别的分类性能。
- from sklearn.utils import class_weightclass_weightclass_weight =class_weight.compute_class_weight('balanced,
- np.unique(target_Y),
- target_Y)model = LogisticRegression(class_weightclass_weight = class_weight)
- model.fit(X,target_Y)# ['balanced', 'calculated balanced', 'normalized'] arehyperpaameterswhic we can play with.
对于几乎所有的分类算法,从逻辑回归到Catboost,都有一个class_weight参数。但是XGboost对二进制分类使用scale_pos_weight,对二进制和多类问题使用样本权重。
(2) 数长比
非常简单明了,用行数除以每个类的计数数,然后
- weights = df[target_Y].value_counts()/len(df)
- model = LGBMClassifier(class_weight = weights)model.fit(X,target_Y)
(3) 平和权重技术(Smoothen Weights)
这是选择权重的最佳方法之一。labels_dict是包含每个类的计数的字典对象,对数函数对不平衡类的权重进行平和处理。
- def class_weight(labels_dict,mu=0.15):
- total = np.sum(labels_dict.values()) keys = labels_dict.keys() weight = dict()for i in keys:
- score =np.log(mu*total/float(labels_dict[i])) weight[i] = score if score > 1else 1return weight# random labels_dict
- labels_dict = df[target_Y].value_counts().to_dict()weights =class_weight(labels_dict)model = RandomForestClassifier(class_weight = weights)
- model.fit(X,target_Y)
(4) 样本权重策略
下面的函数不同于用于为XGboost算法获取样本权重的class_weight参数。它为每个训练样本返回不同的权重。样本权重是一个与数据长度相同的数组,包含应用于每个样本的模型损失的权重。
- def BalancedSampleWeights(y_train,class_weight_coef):
- classes = np.unique(y_train, axis =0)
- classes.sort()class_samples = np.bincount(y_train)total_samples = class_samples.sum()n_classes = len(class_samples) weights = total_samples / (n_classes* class_samples * 1.0)
- class_weight_dict = {key : value for (key, value) in zip(classes, weights)}
- class_weight_dict[classes[1]] = class_weight_dict[classes[1]] *
- class_weight_coefsample_weights = [class_weight_dict[i] for i in y_train]
- return sample_weights#Usage
- weight=BalancedSampleWeights(target_Y,class_weight_coef)
- model = XGBClassifier(sample_weight = weight)
- model.fit(X, target_Y)
(5) 类权重与样本权重:
样本权重用于为每个训练样本提供权重,这意味着应该传递一个一维数组,其元素数量与训练样本完全相同。类权重用于为每个目标类提供权重,这意味着应该为要分类的每个类传递一个权重。
以上是为分类器查找类权重和样本权重的几种方法,所有这些技术都对笔者的项目有效,你可以试试这些技巧,绝对大有帮助。
(三)
处理样本不均衡数据一般可以有以下方法:
1、人为将样本变为均衡数据。
上采样:重复采样样本量少的部分,以数据量多的一方的样本数量为标准,把样本数量较少的类的样本数量生成和样本数量多的一方相同。
下采样:减少采样样本量多的部分,以数据量少的一方的样本数量为标准。
2、调节模型参数(class_weigh,sample_weight,这些参数不是对样本进行上采样下采样等处理,而是在损失函数上对不同的样本加上权重)
(A)逻辑回归中的参数class_weigh;
在逻辑回归中,参数class_weight默认None,此模式表示假设数据集中的所有标签是均衡的,即自动认为标签的比例是1:1。所以当样本不均衡的时候,我们可以使用形如{标签的值1:权重1,标签的值2:权重2}的字典来输入真实的样本标签比例(例如{“违约”:10,“未违约”:1}),来提高违约样本在损失函数中的权重。
或者使用”balanced“模式,sklearn内部原理:直接使用n_samples/(n_classes * np.bincount(y)),即样本总数/(类别数量*y0出现频率)作为权重,可以比较好地修正我们的样本不均衡情况。
(B)在SVM中使用SVC类的参数class_weigh和接口fit中可以设定的sample_weight:
SVC类的参数class_weigh:
对于class_weight,输入形如{"标签的值1":权重1,"标签的值2":权重2}的字典,则不同类别的C将会自动被设为不同的值:
sklearn内部原理:标签的值为1的C:权重1 * C,标签的值为2的C:权重2*C
或者,可以使用“balanced”模式,sklearn内部原理:这个模式使用y的值自动调整与输入数据中的类频率成反比的权重为 n_samples/(n_classes * np.bincount(y)
fit接口参数sample_weight:
参数形式:数组,结构为 (n_samples, ),则模型参数C则变为,每个样本的权重 * C值,这样迫使分类器强调权重更大的样本。通常,较大的权重加在少数类的样本上,以迫使模型向着少数类的方向建模。
(四)不均衡分类问题 之 class weight & sample weight
分类问题中,当不同类别的样本量差异很大,即类分布不平衡时,很容易影响分类结果。因此需要进行校正。
sklearn的做法是加权,加权就要涉及到class_weight和sample_weight,当不设置该参数时,默认所有类别的权值为1。
类型权重 class_weight
字典类型,将类索引映射到权重值。对训练集里的每个类别加权,作用于损失函数(仅在训练过程中)。从而使模型更加关注样本数量少的类别。如果某类别的样本数多,那么它的权重就低,反之则权重就高.
应用场景:
第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重class_weight={0:0.9, 1:0.1}。
第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。这时,我们可以选择balanced(scikit-learn 逻辑回归类库使用小结),让类库自动提高非法用户样本的权重。
参数设置
那么应该如何设置class_weight呢?
通过字典形式传入权重参数,如二分类问题y ∈ { 0 , 1 } y \in \{0,1\}y∈{0,1},class_weight={0:0.9, 1:0.1}
设置class_weight = 'balanced’
此时,会自动调用from sklearn.utils.class_weight import compute_class_weight计算权重,平衡输入样本中各类别之间的权重。其计算公式为:
w e i g h t = n _ s a m p l e s / ( n _ c l a s s e s ∗ n p . b i n c o u n t ( y ) ) weight = n\_samples / (n\_classes * np.bincount(y))weight=n_samples/(n_classes∗np.bincount(y))
import numpy as np
y = [0,0,0,0,0,0,0,0,1,1,1,1,1,1,2,2] #标签值,一共16个样本
a = np.bincount(y) # array([8, 6, 2], dtype=int64) 计算每个类别的样本数量
aa = 1/a #倒数 array([0.125 , 0.16666667, 0.5 ])
print(aa)
from sklearn.utils.class_weight import compute_class_weight
class_weight = 'balanced'
classes = np.array([0, 1, 2]) #标签类别
weight = compute_class_weight(class_weight, classes, y)
print(weight) # [0.66666667 0.88888889 2.66666667]
print(0.66666667*8) #5.33333336
print(0.88888889*6) #5.33333334
print(2.66666667*2) #5.33333334
# 这三个值非常接近
# 'balanced'计算出来的结果很均衡,使得惩罚项和样本量对应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这种方式在原始的损失函数的基础上乘以对应的sample_weight来计算最终的损失。这样计算而来的损失函数不会因为样本不平衡而被“推向”样本量偏少的类别中
样本权重 sample_weight
numpy权重数组。对每个样本加权(仅在训练过程中),思路和类别权重类似,即样本数多的类别样本权重低,反之样本权重高
应用场景:
样本不平衡,导致样本不是总体样本的无偏估计,从而可能导致我们的模型预测能力下降。遇到这种情况,我们可以通过调节样本权重来尝试解决这个问题。调节样本权重的方法有两种,第一种是在class_weight使用balanced。第二种是在调用fit函数时,通过sample_weight来自己调节每个样本权重。
注意事项:
在sklearn中的逻辑回归时,如果上面两种方法都用到了,那么样本的真正权重是class_weight * sample_weight.
原理:样本或类别的权重在训练模型最终通过损失函数实现(以逻辑回归为例):
算法会把每个样本的训练损失乘以它的权重class_weight*sample_weight,损失函数为:
J ( θ ) = − β ∗ ln ( θ ) = − β ∑ i = 1 m ( y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ) J(\theta) =-\beta*\ln(\theta) = −\beta∑_{i=1}^m(y^{(i)}log(h_θ(x^{(i)}))+(1−y^{(i)})log(1−h_θ{(x^{(i)})}))J(θ)=−β∗ln(θ)=−β∑
i=1
m
(y
(i)
log(h
θ
(x
(i)
))+(1−y
(i)
)log(1−h
θ
(x
(i)
)))
其中,β = ( c l a s s _ w e i g h t ∗ s a m p l e _ w e i g h t ) \beta = (class\_weight∗sample\_weight)β=(class_weight∗sample_weight)
应用:做受众选择(人群扩展、人群定向)模型,若种子包括目标商品转化和行为用户(购买较少,加入线上加购、收藏作为正样本),可考虑加大转化用户的样本权重。
如果仅仅是类不平衡,则使用class_weight;
如果类内样本之间还不平衡,则使用sample_weights。
如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。
————————————————
版权声明:本文为CSDN博主「SkullSky」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/SkullSky/article/details/106222795















 2887
2887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









