










一、CoCa 模型简介
CoCa(Contrastive Captioner)是 Google 提出的一种图文联合学习模型,核心思想是统一 图文对比学习 与 图像字幕生成任务,实现一种通用的图文基础模型(Image-Text Foundation Model)。
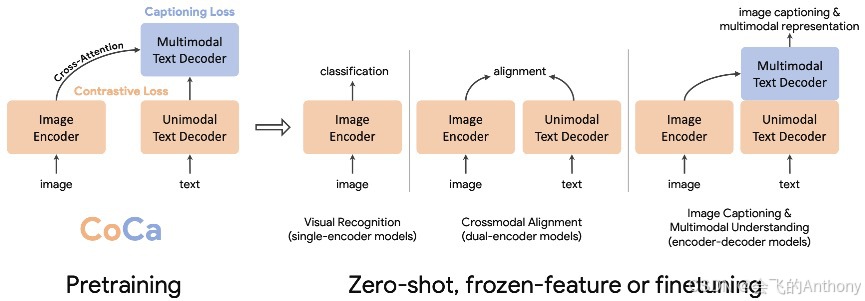
CoCa 由以下三部分构成:
-
视觉编码器(Vision Transformer):提取图像 patch 表征;
-
语言建模器(Transformer):对文本进行建模与解码;
-
双任务目标:
-
文本生成任务(Captioning loss):通过自回归的方式生成描述;
-
对比学习任务(Contrastive loss):类似 CLIP,通过最大化图文对的匹配相似度进行表示学习。
-
它的训练目标是将图文理解与生成统一在一个模型中,同时优化两个目标函数,提升模型在下游多模态任务上的泛化能力。
二、环境配置与依赖导入
import torch
from torch import einsum, nn
import torch.nn.functional as F
from einops import rearrange, repeat
三、CoCa 模型各模块详解
1. LayerNorm 与 Residual
为确保数值稳定性,CoCa 自定义了不含 bias 的 LayerNorm:
class LayerNorm(nn.Module):
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.ones(dim))
self.register_buffer("beta", torch.zeros(dim))
def forward(self, x):
return F.layer_norm(x, x.shape[-1:], self.gamma, self.beta)
同时实现了 Residual 模块,用于残差连接:
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
2. Rotary Positional Embedding(旋转位置编码)
用于 Transformer 模块中的位置编码:
class RotaryEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, max_seq_len, *, device):
seq = torch.arange(max_seq_len, device=device, dtype=self.inv_freq.dtype)
freqs = einsum("i , j -> i j", seq, self.inv_freq)
return torch.cat((freqs, freqs), dim=-1)
3. Transformer Block
使用了并行注意力机制:
class ParallelTransformerBlock(nn.Module):
def __init__(self, dim, dim_head=64, heads=8, ff_mult=4):
...
self.rotary_emb = RotaryEmbedding(dim_head)
self.fused_attn_ff_proj = nn.Linear(dim, sum(self.fused_dims), bias=False)
...
def forward(self, x, attn_mask=None):
...
q, k, v, ff = self.fused_attn_ff_proj(x).split(self.fused_dims, dim=-1)
...
q = apply_rotary_pos_emb(self.get_rotary_embedding(n, device), q)
...
out = einsum("b h i j, b j d -> b h i d", attn, v)
return self.attn_out(rearrange(out, "b h n d -> b n (h d)")) + self.ff_out(ff)
搭配旋转操作 apply_rotary_pos_emb 和 rotate_half,实现绝对位置嵌入替代方案。
4. 图文交叉注意力层:CrossAttention
class CrossAttention(nn.Module):
def __init__(self, dim, context_dim=None, dim_head=64, heads=8, ...):
...
self.to_q = nn.Linear(dim, inner_dim, bias=False)
self.to_kv = nn.Linear(context_dim, dim_head * 2, bias=False)
def forward(self, x, context):
...
sim = einsum('b h i d, b j d -> b h i j', q, k)
...
out = einsum('b h i j, b j d -> b h i d', attn, v)
...
return self.to_out(out) + self.ff(x) if self.ff else self.to_out(out)
用于图文信息融合,文本 attends to 图像 patch tokens。
四、主模型结构:CoCa 类实现
class CoCa(nn.Module):
def __init__(..., caption_loss_weight=1.0, contrastive_loss_weight=1.0, ...):
...
self.token_emb = nn.Embedding(num_tokens, dim)
self.text_cls_token = nn.Parameter(torch.randn(dim))
self.img_attn_pool = CrossAttention(...)
...
self.unimodal_layers = nn.ModuleList([...])
self.multimodal_layers = nn.ModuleList([...])
...
self.to_logits = nn.Sequential(
LayerNorm(dim),
nn.Linear(dim, num_tokens, bias=False)
)
...
forward 流程:
-
embed_text:文本序列加 CLS token → unimodal transformer → text embedding -
embed_image:ViT 编码图像 → attention pool → 图像 CLS / patch tokens -
forward:multimodal 层:文本 attends 图像、计算 logits(caption)和 latent(contrastive)、最终返回 loss / logits / embedding
五、完整训练示例
1. 加载图像编码器(ViT)
from vit_pytorch import ViT
from vit_pytorch.extractor import Extractor
vit = ViT(
image_size=256,
patch_size=32,
num_classes=1000,
dim=1024,
depth=6,
heads=16,
mlp_dim=2048
)
vit = Extractor(vit, return_embeddings_only=True)
2. 构建 CoCa 模型
coca = CoCa(
dim=512,
img_encoder=vit,
image_dim=1024,
num_tokens=20000,
unimodal_depth=6,
multimodal_depth=6,
dim_head=64,
heads=8,
caption_loss_weight=1.0,
contrastive_loss_weight=1.0
).to(device)
3. 输入数据与训练
text = torch.randint(0, 20000, (4, 512)).to(device)
images = torch.randn(4, 3, 256, 256).to(device)
loss = coca(
text=text,
images=images,
return_loss=True
)
loss.backward()
4. 获取模型输出
-
获取 caption logits(生成任务)
logits = coca(
text=text,
images=images
) # shape: (batch, seq_len, vocab_size)
-
获取 text/image embedding(检索任务)
text_embeds, image_embeds = coca(
text=text,
images=images,
return_embeddings=True
) # shape: (batch, dim)
六、总结
CoCa 作为一款统一图文基础模型,设计非常 elegant:
-
✨ 对比目标拉近图文全局表示
-
✨ Captioning 实现图像生成文字
-
✨ 结构解耦,便于灵活扩展
-
✨ 图像输入统一为 patch embedding + attention pooling
从零样本图文检索到高质量图像描述,CoCa 展现了强大的多模态建模能力。
📌 下一篇将进入 RLHF(Reinforcement Learning with Human Feedback)相关内容,开启多轮对话训练的范式探索,敬请期待!
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于人工智能、自然语言处理和计算机视觉的精彩内容。
谢谢大家的支持!



















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











