






本文优点:1可以计算离散型和数值型混合的数据;2我的第七步“计算准确率”,简洁又明了,非常好看
我简单的按照df[attr].unique()的长度来区分离散型连续型,因为一般离散型就两种或三种取值,其它都是连续型。
发布时间2024.1.1
完整代码在最下面。(虽然我是jupyter编辑器,但我特意用print输出)
test.xlsx百度网盘链接
链接:https://pan.baidu.com/s/1B6tE4FgOPc5-ebz6ZHq51Q?pwd=1111
提取码:1111

- 导入包
# 朴素贝叶斯 离散(文本型) 连续(数值型)
import pandas as pd
import numpy as np
import random as r
- 读取excel
根据excel类型使用不同函数读取
.xls .xlsx用
df=pd.read_excel(file_name,sheet_name=‘Sheet1’)
.csv用
df=pd.read_csv(file_name,encoding=‘gbk’)
file_name='test.xlsx'
df=pd.read_excel(file_name,sheet_name='Sheet1')
row,col=df.shape
print(df.info())
print(df.head())
print(row,col)
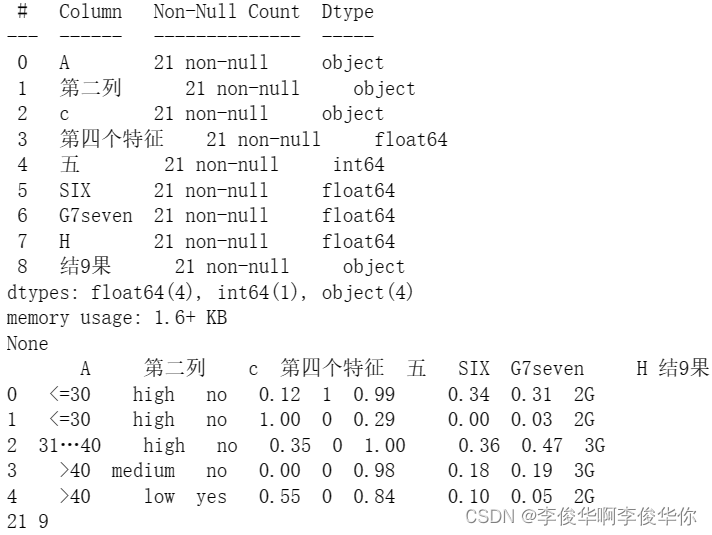
- 看看数据,离散型统计个数,连续型计算平均值
d_attrs=[]#离散型特征列名
c_attrs=[]#连续型特征列名
for col in df.columns[:-1]:
if len(df[col].unique())<=3:#离散型要么0\1 要么高\中\低 再多应该大概可能不存在
print('离散型→',df[col].value_counts())
d_attrs.append(col)
else:
print('数值型→',df[col].describe())
c_attrs.append(col)

- 手动拆分训练集测试集
# 手动拆分训练集
_test=set()
test_size=int(row*0.3)
_train=list()
train_size=row-test_size
while len(_test)<test_size:
_test.add(r.randint(0,len(df)-1))
for i in range(len(df)-1):
if i not in _test:
_train.append(i)
print('测试集序号→',_test)
print('训练集序号→',_train)
test=df.iloc[ list(_test) ]
train=df.iloc[_train]
label0,label1=df.iloc[:,-1].unique().tolist()#分类结果1,分类结果2 标签0,标签1
train0=train[ train[df.columns[-1]]==label0 ]#只包含分类结果1的训练集
train1=train[ train[df.columns[-1]]==label1 ]#只包含分类结果2的训练集
print(test)
print(train0)
print(train1)

- 一个自定义函数,概率密度函数
# 落在x处概率密度函数(probability density function)
def f(mean , std , x):# mean训练集平均值 std标准差 x测试集样本特征值
prob_density = (1/std*np.sqrt(2*np.pi)) * np.exp(-0.5*((x-mean)/std)**2)
return prob_density
- 统计概率,保存到字典
# 离散型特征各种情况发生的概率,和数值型特征列的平均值 标准差
temp=train[df.columns[-1]].value_counts(normalize=True)#【分类结果1好瓜概率,分类结果2坏瓜概率】
dict0={'分类结果1概率':temp[label0]}
dict1={'分类结果2概率':temp[label1]}
for attr in d_attrs:
temp0=train0[attr].value_counts(normalize=True)
dict0[attr]=temp0
temp1=train1[attr].value_counts(normalize=True)
dict1[attr]=temp1
for attr in c_attrs:
dict0[attr]=[train0[attr].mean(),train0[attr].std()]
dict1[attr]=[train1[attr].mean(),train1[attr].std()]
print(dict0)
print(dict1)
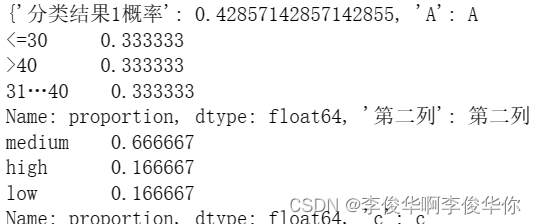
- 计算测试集准确率
# 计算测试集准确率
print(' 真实值 预测值 是否匹配')
count=0
for i in range(test_size):
each=test.iloc[i]
p0=dict0['分类结果1概率']
p1=dict1['分类结果2概率']
for attr in d_attrs:#离散型
try:
p0*=dict0[attr][each[attr]]
except:
p0=0
try:
p1*=dict1[attr][each[attr]]
except:
p1=0
for attr in c_attrs:
mean,std=dict0[attr]
p0*=f(mean,std,each[attr])
mean,std=dict1[attr]
p1*=f(mean,std,each[attr])
real=each[df.columns[-1]]
if p0>p1:
predict=label0
else:
predict=label1
if real==predict:
count+=1
print('%2d %6s %6s √'%(i+1,real,predict))
else:
print('%2d %6s %6s'%(i+1,real,predict))
print('准确率→ %d/%d %f'%(count,test_size,count/test_size))

完整代码
# 朴素贝叶斯 离散(文本型) 连续(数值型)
import pandas as pd
import numpy as np
import random as r
# 这是备用的数据,防止你打不开excel
## excel文件要前n-1列为特征,第n列为分类结果,分类结果只能两种 0\1 或 YES\NO
columns=['A', '第二列', 'c', '第四个特征', '五', 'SIX', 'G7seven', 'H', '结9果']
data= [['<=30', 'high', 'no', 0.12, 1, 0.99, 0.34, 0.31, '2G'],
['<=30', 'high', 'no', 1.0, 0, 0.29, 0.0, 0.03, '2G'],
['31…40', 'high', 'no', 0.35, 0, 1.0, 0.36, 0.47, '3G'],
['>40', 'medium', 'no', 0.0, 0, 0.98, 0.18, 0.19, '3G'],
['>40', 'low', 'yes', 0.55, 0, 0.84, 0.1, 0.05, '2G'],
['>40', 'low', 'yes', 0.0, 0, 1.0, 0.14, 0.08, '2G'],
['31…40', 'low', 'yes', 0.35, 1, 0.98, 0.21, 0.12, '3G'],
['<=30', 'medium', 'no', 0.07, 0, 0.53, 0.11, 0.02, '2G'],
['<=30', 'low', 'yes', 0.0, 0, 0.4, 0.05, 0.01, '3G'],
['>40', 'medium', 'yes', 0.07, 1, 0.71, 0.19, 0.08, '3G'],
['<=30', 'medium', 'yes', 0.0, 0, 0.98, 0.22, 0.14, '3G'],
['31…40', 'medium', 'no', 0.12, 0, 0.79, 0.04, 0.04, '2G'],
['31…40', 'high', 'yes', 0.0, 0, 0.96, 0.17, 0.44, '3G'],
['>40', 'medium', 'no', 0.03, 0, 0.76, 0.05, 0.09, '2G'],
['<=30', 'medium', 'no', 0.22, 1, 0.95, 0.19, 0.15, '3G'],
['<=30', 'low', 'yes', 0.62, 0, 1.0, 0.28, 0.22, '3G'],
['31…40', 'medium', 'yes', 0.18, 1, 1.0, 0.27, 0.21, '2G'],
['31…40', 'high', 'no', 0.45, 0, 1.0, 0.16, 0.15, '3G'],
['31…40', 'low', 'no', 0.17, 0, 0.99, 0.09, 0.13, '3G'],
['>40', 'low', 'yes', 0.0, 0, 0.99, 0.19, 0.16, '3G'],
['>40', 'high', 'no', 0.02, 1, 0.91, 0.16, 0.11, '3G']]
df=pd.DataFrame(data,columns=columns)
file_name='test.xlsx'
df=pd.read_excel(file_name,sheet_name='Sheet1')
row,col=df.shape
print(df.info())
print(df.head())
print(row,col)
d_attrs=[]#离散型特征列名
c_attrs=[]#连续型特征列名
for col in df.columns[:-1]:
if len(df[col].unique())<=3:#离散型要么0\1 要么高\中\低 再多应该大概可能不存在
print('离散型→',df[col].value_counts())
d_attrs.append(col)
else:
print('数值型→',df[col].describe())
c_attrs.append(col)
# 手动拆分训练集
_test=set()
test_size=int(row*0.3)
_train=list()
train_size=row-test_size
while len(_test)<test_size:
_test.add(r.randint(0,len(df)-1))
for i in range(len(df)-1):
if i not in _test:
_train.append(i)
print('测试集序号→',_test)
print('训练集序号→',_train)
test=df.iloc[ list(_test) ]
train=df.iloc[_train]
label0,label1=df.iloc[:,-1].unique().tolist()#分类结果1,分类结果2 标签0,标签1
train0=train[ train[df.columns[-1]]==label0 ]#只包含分类结果1的训练集
train1=train[ train[df.columns[-1]]==label1 ]#只包含分类结果2的训练集
print(test)
print(train0)
print(train1)
# 落在x处概率密度函数(probability density function)
def f(mean , std , x):# mean训练集平均值 std标准差 x测试集样本特征值
prob_density = (1/std*np.sqrt(2*np.pi)) * np.exp(-0.5*((x-mean)/std)**2)
return prob_density
# 离散型特征各种情况发生的概率,和数值型特征列的平均值 标准差
temp=train[df.columns[-1]].value_counts(normalize=True)#【分类结果1好瓜概率,分类结果2坏瓜概率】
dict0={'分类结果1概率':temp[label0]}
dict1={'分类结果2概率':temp[label1]}
for attr in d_attrs:
temp0=train0[attr].value_counts(normalize=True)
dict0[attr]=temp0
temp1=train1[attr].value_counts(normalize=True)
dict1[attr]=temp1
for attr in c_attrs:
dict0[attr]=[train0[attr].mean(),train0[attr].std()]
dict1[attr]=[train1[attr].mean(),train1[attr].std()]
print(dict0)
print(dict1)
# 计算测试集准确率
print(' 真实值 预测值 是否匹配')
count=0
for i in range(test_size):
each=test.iloc[i]
p0=dict0['分类结果1概率']
p1=dict1['分类结果2概率']
for attr in d_attrs:#离散型
try:
p0*=dict0[attr][each[attr]]
except:
p0=0
try:
p1*=dict1[attr][each[attr]]
except:
p1=0
for attr in c_attrs:
mean,std=dict0[attr]
p0*=f(mean,std,each[attr])
mean,std=dict1[attr]
p1*=f(mean,std,each[attr])
real=each[df.columns[-1]]
if p0>p1:
predict=label0
else:
predict=label1
if real==predict:
count+=1
print('%2d %6s %6s √'%(i+1,real,predict))
else:
print('%2d %6s %6s'%(i+1,real,predict))
print('准确率→ %d/%d %f'%(count,test_size,count/test_size))















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









