







在第二篇我们说过mpi里的函数很多都有大写和小写的版本,并且大写的版本是需要buffer的,但那时候并没有说明怎么使用和为什么要这样用,今天就让我填这个坑吧.
为什么?
这次先说为什么,为什么需要有大写版本的函数?
事实上我们是把因果颠倒了,在c语言里,MPI只有大写版本的函数,没有小写版本的.
显然,关注效率的C语言当然会更喜欢你提供一个buffer,然后拷贝复制,而不是通过返回值传递,这样可以避免很多无谓的数据复制.
但对于python来说,编程的效率更重要,于是才有了小写版本的函数.
其次,为什么我们还需要学习大写版本的函数?
因为有一些函数没有小写版本!(比如非阻塞型的广播)
这是一个很致命的原因.
怎么做?
python有不少库能提供buffer型的数据类型,比如说numpy的array.
下面我们使用numpy的array充当buffer,尝试使用大写版本的Send和Recv来点对点通信.
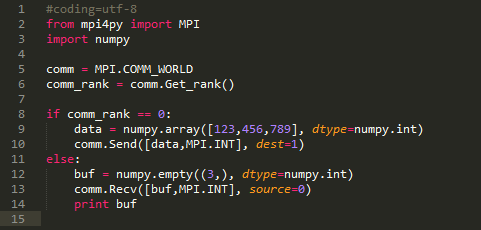
代码:
运行结果:
代码解释:
关于numpy的array的使用方法,请移步百度,这里不多讲.
代码里进程0创建了一个放有3个int的数组,并向进程1发送.
而进程1也创建了一个放有3个int的数组作为buffer,通过Recv函数接收.
这里第一个重点是大写版本函数的用法和以前小写版本函数的区别.
首先,没有返回值,也就是接收数据不通过返回值,而是通过参数.
其次,发送和接收数据的格式不一样.你需要提供一个列表(或元组).
列表第0项放的是buffer的名字(相当于C里的指针),第1项放的是数据类型,这里是MPI.INT
事实上你还可以指定你要发送多少个数据(在C里这是必须的,指针本身不知道自己有多少个数据),格式是[buffer,count,type]
数据类型:
关于数据类型,这里有一个常用的简单对应表.
| numpy.array | MPI | python |
|---|---|---|
| numpy.int | MPI.INT | int |
| numpy.float | MPI.DOUBLE | float |
| numpy.int64 | MPI.INTEGER64 | int |
这里的int一般就是4个字节的int,而float则是8个字节的double.
由于buffer里的整数都是像C里的一样,有范围限制的,而python的int是没有的,因此使用的时候必须要小心溢出.
注意:
python的列表list并不能充当buffer,因为它本质不是一个C里的固定好类型的数组,而numpy的array则是这种类型固定的数组.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









