






零、读取输入输出
1、常用格式:
数据类型(input()),eg:input1 = int(input()),str(input())
2、可能使用的函数:split,map,
python按分行符来判断是第几个输入,也就是说如果每个变量输入完成后均回车,那么只需要依次读取即可。
如果同一行会有两个输入,并用分割符隔开,那么需要靠split函数,通过分割符来识别,将变量的输入区分开。
map函数也会常用。首先说,map函数的功能是对某组数据重复某函数操作(库函数、自编函数均可),语法为:map(function, iterable)。
因此在读取输入时,map函数可用于将多个输入,统一为相同的数据类型,eg:
n,k = list(map(int,input().split()))
num = list(map(int,input().split()))
这里的应用场景是:第一行输入两个整数n和k,第二行输入一个整数数组,并在读取输入后,把他们以list数据形式。
一、单个数值计算
涉及数值运算时,直接 import math,或者:
form math import floor, ceil, sqrt, sin, cos, asin, acos, mod
常用的三角函数、计算等都需要import math,在使用的时候,写作eg:math.sqrt()
二、数组运算
import numpy
还可写作:import numpy as np,之后使用的时候写作np.array
要注意,python和MATLAB不同,a = []创建的不是空数组而是空列表,两个列表之间是不能直接做加减乘除运算的!如果要创建数组的话,需要使用numpy中单独的命令b = np.array([1,2,3])。列表和数组可以使用numpy中的函数互相转换:array到list:b.tolist(),list到array:np.arrar(list)。
三、列表
有一些基本操作:
a[::-1]:倒序
sorted:排序
用推导式生成列表 [i for循环循环遍历i的输入]
四、字符串
输入一个字符串,字符串中的每个字符为一个数据,因此可以使用下标进行访问。字符串不可修改(不能用a[2]=H这样直接复制进行修改)。
常用函数:
1、index,可以直接照抄某字符/字符串在某字符串中出现的位置。
语法:v=a.index("and")(返回v为a的下标索引)
2、spline:按指定的分隔符,将字符串分开为若干个字符串,并存入列表(新变量)。
语法:字符串.split('分隔符')
3、strip:字符串的规整操作,去前后指定字符串。
语法为:字符串.strip('要去除的字符串")
注意:并不将要去除的字符串视为一个整体,而是将要去除的字符串的每一个字符都会移除(按照字字符串进行移除)。
要去除的字符串为空时,为默认操作去除空格。
4、replace,将字符串内的全部字符串1,替换为字符串2(类似word中的全部替换的用法)。
语法为:字符串.replace(字符串1,字符串2)
不会对原字符串修改,而是生成了一个新的字符串,因此需要使用新的变量。
5、join,连接任意数量的字符串(包括要连接的元素字符串、元组、列表、字典),用新的目标分隔符连接,返回新的字符串。每两个相邻元素直接都会被加入这个分隔符。
语法为:‘分隔符’.join(变量名)
可以用来整理输出格式。join括号里只支持字符串由字符串组成的列表(字典,字符串,元组)
6、常用1:统计字符串中某字符串出现的次数(count),count的输入不仅仅可以是一个字符,还可以是一个字符串整体。
7、支持for循环
五、集合
感觉集合还蛮常用的,特点是,集合中的元素唯一,无法通过元素遍历(for i in setA),也无法通过索引遍历
妙想:将set转换为list之后再遍历,利用set中数据唯一的特点
1、定义和创建
也是{}定义,但是由于字典也是大括号,因此在定义空集合时,不能直接直接a={}.
需要用set()函数,eg:a=set(),定义一个空集合。有值时可以直接赋值定义。
将其他数据类型转换为集合,set(a),a可以是list
print集合中的所有元素可以直接print(setname)
2、增加、删除元素
添加单个元素setname.add(单个元素)
一次添加多个元素setname.update(列表、元组、集合)
随机删除一个元素setname.pop()
指定删除某个元素setname.remove('要删除的元素‘’)。同样的,由于是删除指定元素,所以最好加一个判断元素是否在集合中的if语句,防止要删除的元素不在集合中而报错中断程序。
全部清除setname.clear()
直接删除这个集合并清除变量名 del setname
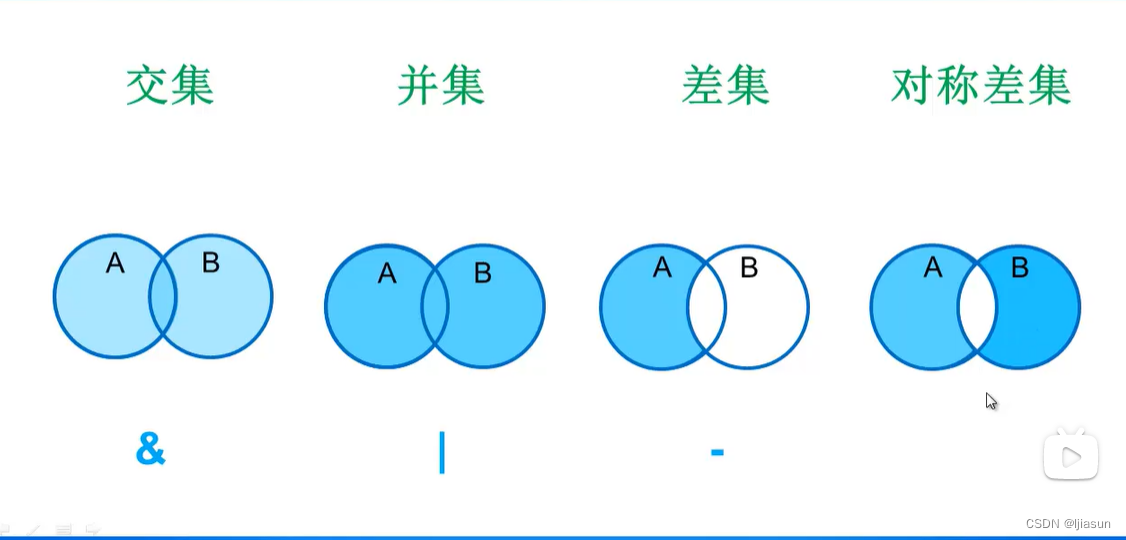
3、交、并、差逻辑运算
a - b: a有b没有的元素---->差集,只在a中出现的元素
a | b: a有或者b有的元素--->并集
a & b: ab都有的元素----->交集
a ^ b: ab中不同时拥有的元素,a有b没有或者是b有a没有的---->对称差集(a-b)+(b-a)所有的元素
六、栈和队列*
栈是先进后出(只有一个口的瓶子),队列是先进先出(排队)。用两个栈即可实现队列。
push(x) -- 将一个元素放入队列的尾部。或者用append(x)
pop() -- 从队列首部移除元素。
peek() -- 返回队列首部的元素。
empty() -- 返回队列是否为空。

栈和队列应该都是属于一种逻辑结果?本质还是一个列表,只是说给列表的数据的增删改查,加了一个规则
单调栈
七、二叉树的遍历
八、回溯算法解应用题
九、元组的使用
十、类
十一、字典
字典第一个特点就是键对值,有遇到这种对应查找的时候,可以使用
键唯一,值可以有多个
1、字典的创建和删除:
可以直接定义{键对值,键对值},{元组(()定义的数据),列表}
可以用zip函数,将两个列表组合转换为zip对象,再用dict函数将zip对象转为字典
语法:dic = dict(zip(key,values))
只有key也可以创建词典,用dick.fromkeys(keys列表)
删除整个字典,用del 字典名,会清除掉这个变量
如果只想清空这个字典,但是保留变量名用字典名.clear()
用字典推导式快速生成字典(列表也可以用此操作,只是[]换{})
语法为:{键表达式:值表达式 for循环遍历得到键和值表达式中的输入}
根据要print的内容选择合适的print方法(见2、访问)
2、访问
输出全部内容,print( dic(字典变量名) )
通过键来访问value,dic[key]------>输出字典dic中这个key对应的value
通过get函数访问,dic.get(key,默认值)----->输出字典dic中这个key对应的value。默认值可以不指定,不指定时,如果该键无对应值则返回None,指定则返回想要的内容
注意注意,查找字典元素的关键是key。因此只能判断key在不在字典中,if key in dic
3、遍历
遍历键对值,用dic.items(),返回一个列表,列表中包含若干个元组,一个元组是一对键对值。
要将key和value分开,用一个for循环遍历,print中还可以加链接字符
for key,value in dic.items():
print(key,'链接字符',value)提供key和values函数来分别查找key的列表,和value的列表。
dic.keys(),dic.values()
同样由于items,keys,values这三个函数的返回值都是列表,因此可以用元素遍历。
4、添加、修改、删除元素
添加就直接赋值就行了:dic[newkey] = 值(是字符串的话要加引号)
如果添加的key本来已经存在,那么执行的是修改操作--->将原来对应的value覆盖掉
删除元素,同样可以用del,语法为:del dic[key]。在删除时最好判断一下元素是否存在如果判断再删除。即加一个if判断,eg:if key in dic















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









