






背景
初学hadoop,这是学堂在线上面的实验课,权当做自己做的实验笔记吧。
题目
1、输入数据:
输入数据以json格式存储,每行是一条微博数据,或者是一条用户信息数据(你需要在程序中进行判断并分别处理)。每条微博数据格式如下:
{ “_id” : XX, “user_id” : XXXXXXXX, “text” : “XXXXXXXXXXXXXX”, “created_at” : “XXXXXX” }
本实验中我们只需使用user_id项,该项是发微博用户的id。
每个用户信息格式如下:
{ “_id” : XXXXXX, “name” : “XXXX” }
本实验中我们两项都会用到,_id是该用户的id,name是该用户的用户名。
输入数据的样例请见本页最后一部分“输入数据格式样例”。
2.、输出数据
本实验要求输出每个用户名及他发微薄的条数,按数量从大到小排序,示例如下:
86 贫苦少年王笨笨
82 孙子悦是CC不是cc
79 基德丨鳞
75 糖醋鱼刺
每行数目和用户名的中间用制表符(\t)隔开。
分析
统计过程
1、需要在map过程对输入的数据进行来源判断,是微博数据还是用户信息数据。
2、在map过程以同一字段(id)作为key值进行存储,而value值则是计数或者是用户名。
3、在reduce阶段,需要对value值进行判断,以区分开来数字型的统计数和字符串型的用户名。
排序过程
1、由于reduce过程自带对key值的升序排序,所以,为达到本文的要求,可以在对上述的输出结果中的key和value值进行互换,再进行一次map和reduce操作。
2、降序排序,可以通过设置job的setSortComparatorClass来进行设置。
实现结果
词频统计之后的结果:
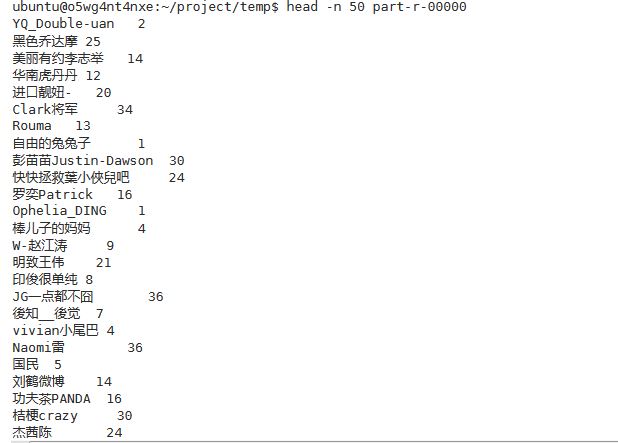
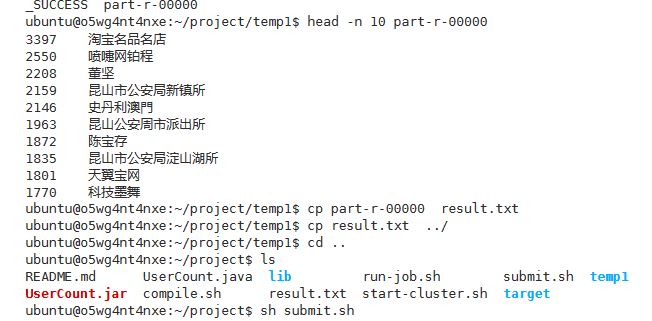
根据词频按照降序进行排序的结果:
代码
import java.io.IOException;
import java.util.Random;
import java.util.Iterator;
import java.util.StringTokenizer;
import java.util.ArrayList;
import org.json.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class UserCount{
public static class CountMapper extends Mapper<Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
String line = value.toString();
JSONObject js = new JSONObject(line);
String id = null;
String tabletype = new String();
if (js.has("user_id")){
//tabletype =1;
id = js.optString("user_id");
value.set(id);
context.write(value, new Text("1"));
}
else if(js.has("name")){
//tabletype=2;
id = js.optString("_id");
Text name = new Text(js.optString("name"));
value.set(id);
context.write(value, name);
}
}
}
public static class CountReducer extends Reducer<Text,Text,Text,IntWritable>
{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
String name="00";
for (Text val : values)
{
//sum += val.get();
sum += 1;
if (!val.toString().equals("1"))
{
name = val.toString();
}
}
sum -= 1;
if (sum > 0)
context.write(new Text(name), new IntWritable(sum));
}
}
public static class SortMapper extends Mapper<Object, Text, IntWritable,Text>
{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
//implement here
String str[] = value.toString().split("\t");
//context.write(new IntWritable(Integer.parseInt(str[1])), new Text(str[0]));
if(str[0]!=null&&str.length==2)
{
// a.set(Integer.parseInt(str[0].trim()));
// b.set(str[1].trim());
//context.write(Integer.parseInt(str[1], new Text(str[0])));
context.write(new IntWritable(Integer.parseInt(str[1])), new Text(str[0]));
}
}
}
public static class SortReducer extends Reducer<IntWritable,Text,IntWritable,Text>
{
private Text result = new Text();
public void reduce(IntWritable key,Iterable<Text> values, Context context)throws IOException, InterruptedException
{
//implement here
for(Text val : values){
result.set(val);
context.write(key,result);
}
}
}
private static class IntDecreasingComparator extends IntWritable.Comparator
{
//注意默认的comparator是Increasing的,所以你完全没有必要明白下面两个method的意义
//返回值为-1,0,1中的一个
public int compare(WritableComparable a, WritableComparable b)
{
//implement here
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)
{
//implement here
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = new Job(conf, "NameCount-count");
job.setJarByClass(UserCount.class);
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/input-user"));
Path tempDir = new Path("temp");
FileOutputFormat.setOutputPath(job, tempDir);
//implement here
//在这里你可以加入你的另一个job来进行排序
//可以使用“job.waitForCompletion(true)“,该方法会开始job并等待job结束,返回值是true代表job成功,否则代表job失败
//在SortJob中使用“sortJob.setSortComparatorClass(IntDecreasingComparator.class)”来把你的输出排序方式设置为你自己写的IntDecreasingComparator
if(job.waitForCompletion(true))
{
Job sortJob = new Job(conf, "NameCount-count-2");
sortJob.setJarByClass(UserCount.class);
FileInputFormat.addInputPath(sortJob, tempDir);
// sortJob.setInputFormatClass(SequenceFileInputFormat.class);
sortJob.setOutputKeyClass(IntWritable.class);
sortJob.setOutputValueClass(Text.class);
// sortJob.setMapperClass(InverseMapper.class);
sortJob.setMapperClass(SortMapper.class);
sortJob.setReducerClass(SortReducer.class);
sortJob.setNumReduceTasks(1);
FileOutputFormat.setOutputPath(sortJob, new Path("temp1"));
sortJob.setSortComparatorClass(IntDecreasingComparator.class);
System.exit(sortJob.waitForCompletion(true) ? 0 : 1);
}
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 2813
2813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









