







富文本没有word这么多格式,这点真的有点烦。。。用word转富文本后一堆出问题的,凑合着看吧

运算器
数据格式
整数:
由符号位与量值组成。
浮点数:
按IEEE754标准,32位与64位的数据格式如下:
| 31 30 23 22 0 | ||
| S | E | M |
| 63 62 52 51 0 | ||
| S | E | M |
其中S是符号位,E是阶码,M是尾数,一个数为2^e.M
为了提高精度,有一个规定,尾数的值不为0时。尾数最高有效位为1。
x的值为(-1)S*(1.M)*2^(E-127)
题目:将-1011.1001101表示成IEEE754标准32位浮点数规格
-1011.1001101 = -1.0111001101 *

需要注意到。2^11不是2的11次方,而是二进制的11,即十进制2的3次方
数的机器码表示
加入符号位,负为1正为0
原码:原来的数的2进制形式。原码运算加减法复杂。如100的原码为0100
反码:正数时,跟原码一样。负数时,是原码的按位取反。
补码:当数字为正数时,与原码一样。当数字为负数时,补码为反码+1。补码的优点是不管加法减法,都使用加法。
+1011的原码是01011,反码跟补码也是01011
-0101的原码是10101,反码是01010,补码是01011
补码计算
两个正数相加后超过最大正数,称为正溢。两个负数相加小于最小负数,称为负溢。
可采用的检测方法有两种:双符号位法或单符号位法。
双符号位法
符号位用量为表示,如100补码就变成00100,然后进行计算。
如果结果的符号位是00或11,代表结果正确。如果是10或者11,则发生了溢出。其中01为正溢出,10为负溢出。
单符号位法
即只用一个符号位表示
当最高有效位产生进位而符号位无进位时,产生正溢。当最高有效位无进位而符号位有进位时。产生负溢。如100的补码是0100,如下
| 0 | 1 | 0 | 0 |
| 符号位 | 最高有效位 |
|
|
校验码
防止故障或干扰出现的错误。使用校验码,当出现错误时,检测甚至校验错误。
奇校验:X的每个位按位加,只有当数据X包含奇数个1时,才能使奇校验位的值为1
偶校验:X中包含偶数个1,才能使偶校验位C=0
发送方使用奇偶校验,计算出C,然后将(x1,x2...xn,C)发给接受方,接收方将此数据进行校验,F=x1+x2+...xn+C,如果最后的值F=1,则没错出。先奇后偶或者先偶后奇
存储器
cache
直接映射
cache行号i与主存块号j的关系:通过i=j mod m进行映射,m为cache总行数
即内存与cache的地址映射是一开始定好的,如,内存中的0块跟16块都映射到同一块cache时,当程序需要同时使用这两块,cache就得不断换来换去,而不能做到两块都放到cache里。
直接映射cache的主要优点是实现简单,缺点是如果使用中的多个块映射到cache同一行,则命中率下降。
全相联映射
内存中每个块都可以映射到cache的每一行中,但是,每次要遍历所有行看是否已存在,代价过大。适用于小容量cache
组相联映射
组相联是上面两种的折中方案,内存块放哪个组是固定的,但存到该组的哪一行是灵活的。
替换策略
LFU(最不常用算法),即访问次数最少的那行换出
LRU(近期最少使用算法)
随机算法:最垃圾但最简单
主存
衡量主存速度的三个指标是:存取时间,存储周期,存储器带宽。
数据线与地址线计算
【例4-1-24】某SRAM芯片,其存储容量为64K×16位,该芯片的地址线和数据线数目为 。
A. 64、16 B. 16、64 C. 64、8 D. 16、16
解:由于芯片是16位,因此数据线就为16条。又64K=216,因此地址线也为16
容量计算
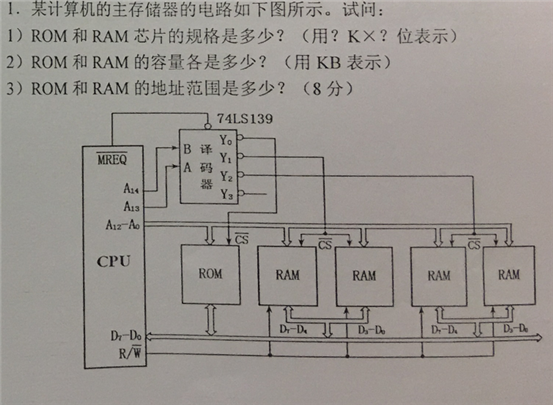
解:
1) 由于下面数据为D0-D7共8位,得出,这是8位的CPU。直接传入ROM,所以ROM数据线为8位,RAM中分两条线到RAM,因此RAM数据线为4位。
地址线为A12-A0,共13位,都直接传入ROM跟RAM,因此
ROM规格为213B*8位=8KB*8位,RAM规格为213B*4位=8KB*4位
2) 由于CPU数据为8位,ROM为一个且刚好为8位,因此容量为8M。RAM两个一组供一个8位线。因此每组容量为8M,而这里有两组(共四个)RAM,因此容量为16KB,
3) 因为译码器的Y0指向ROM,因此ROM为第一个地址。大小为8KB=2000H,占0-1FFFH的位置。RAM为Y1,Y2的信号,接在ROM之后,为2000-5FFFH
虚拟存储器
也即虚拟内存。
虚拟存储器分为:页式,段式,段页式。
页式虚存是对应硬盘按页分配内存的。缺点是在运行的一个程序可能一部分在主存,一部分在硬盘。
段式虚存即用设置的段分,可以动态改变长度。需要记录段起始位置跟段长。但是用段会留下太多外碎片,
段页式会在段内记录页号。减少碎片
指令系统
指令周期是指CPU从主存取出来一条指令至执行完该指令的时间,
CPU的指令周期一般由若干个CPU周期构成, 然后CPU周期中又包含多个时钟周期
一个较完善的指令系统应当包含数据传送类指令,算术运算类指令,逻辑运算类指令,程序控制类指令,IO类指令,字符串类指令,系统控制类指令
地址码
| 三地址指令 | OP码 | A1 | A2 | A3 | |
| 二地址指令 | OP码 | A1 | A2 | ||
| 一地址指令 | OP码 | A | |||
| 零地址指令 | OP码 | —— | |||
其中二地址指令有三种类型:
RR型:寄存器→寄存器→操作数
RS型:寄存器→内存→操作数
SS型:内存→内存→操作数
单字长:跟机器字一样长。如下,是单字长双地址(两个寄存器地址)
| 15 |
|
| 0 |
| OP | —— | 源寄存器 | 目标寄存器 |
双字长:机器字长的两倍。注意下面有个位移量,再看指令长度。如下是双字长双地址的。
| 15 |
|
| 0 |
| OP | —— | 源寄存器 | 目标寄存器 |
| 位移量(16位) | |||
半字长:机器字长的一半
指令寻址
指令寻址有顺序寻址和跳跃寻址。平常就用顺序寻址,遇到转移指令就用跳跃寻址。
操作数寻址方式
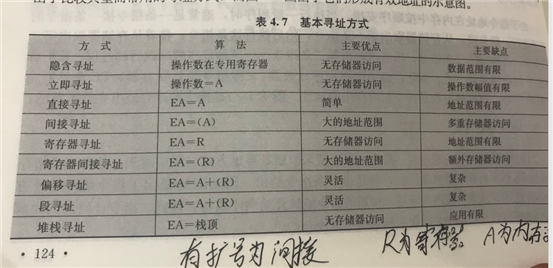

隐含寻址:操作数在专用寄存器。也就是不显示声明,默认去那个寄存器找。例如push默认找ss寄存器
立即寻址:指令的地址字段是操作数本身,而不是它的地址。
直接寻址:最平常的,地址字段是啥就去哪找。
间接寻址:需要两段查找,即需要两次访问内存,效率低。
寄存器寻址:操作数在寄存器中。
寄存器间接寻址:寄存器中存放地址,此地址指向内存单元,内存单元存放操作数
偏移寻址:
包括相对寻址,基址寻址与变址寻址。
相对寻址:开始使用偏移地址。记录与当前地址的偏移值。因此有效地址是当前指令地址的一个上下范围的偏移。
基址寻址:就是段地址+偏移地址的形式。但是BR不能由用户指定

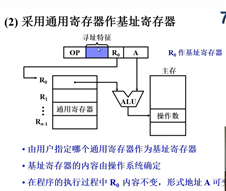
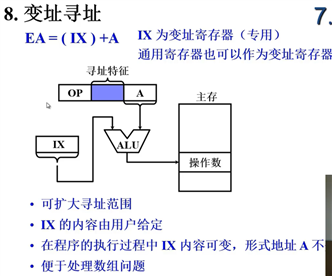
变址寻址:与基址寻址的区别是,IX可以由用户指定。
指令设计
书里题课后题第8:
某机器字长32位,主存容量为1MB,采用单字长指令,共有50条指令,试采用直接,立即,寄存器寻址,寄存器间接四种寻址方式设计指令格式。CPU中有PC,IR,AR,DR和16个通用寄存器:
(1) 指令格式如何安排
(2) 能否增加其他寻址方式。
解:

OP:50个操作码,又25<50<26,因此OP需要6位。
X:寻址方式4种,因此2位
D:主存大小1MB,而1MB=220,因此需20位。又因为需要16个寄存器,因此多4位放入。共24位。
题目2:内存空间大小大于直接寻址范围

或许会注意到,寻址空间64K,形式地址D才8位,这样不够直接寻址。是的,所以这里的直接寻址只够,寻找8位数据。其他的由间接,变址,相对来寻找。但不管怎么寻址, 16位机器最大范围不超过216=64K。(intel有使用36位或40位的,因为已经够用,地址线不需要那么多位。)
CPU
指令周期
数据缓冲存储器(DR):用于暂存ALU的运算结果,或由数据存储器读出的一个数据字,或来自外部接口的一个数据字。
指令寄存器(IR):用于保存当前正在执行的一条指令
程序计数器(PC):用来确定下一条指令的地址。
数据地址寄存器(AR):用来保存CPU所访问的数据cache存储器中单元的地址。


取指阶段不管什么样的指令基本都是一样的。
流水CPU
流水CPU的主要问题是资源相关,数据相关和控制相关,为此需要采用相应的技术对策,才能保证流水线畅通而不断流。
RISC
RISC指令系统的最大特点是:
1. 指令条数少
2. 指令长度固定,指令格式和寻址方式种类少
3. 只有存储器读与存储器写指令访问存储器,其余指令的操作均在寄存器之间进行
总线系统
传送信息
计算机系统中,传输信息采用三种方式:串行传送,并行传送和分时传送。
串行传送:一条传输线,成本低廉。适合远距离传送
并行传送:多条传输线。效率考虑,系统总线上必须使用并行传送
分时传送:一种采用总线复用方式,划分不同时间间隔传送数据或者地址。一种根据设备分。
总线的仲裁
总线的仲裁包括集中式仲裁与分布式仲裁两类。
集中式仲裁
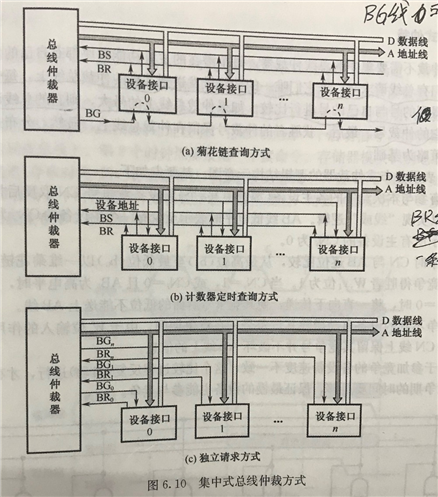
菊花链式仲裁:跟链表一样,一个传一个,有请求的就响应,因此优先级是固定的,为距离总线仲裁器的距离。缺点很明显,如果前面一直有人用,后面的就可能会一直无法访问总线。
计数器定时查询方式:加一条设备地址线用来判别谁获得,有请求发到BR线,当计数器的值与请求总线的地址一致时,此设备获得总线使用权(如从1数到7,先数到的获得),仲裁器。可以发现,优先级也是固定的,但可以自己设置初值,从而改变优先级。
独立请求方式:每个设备都有独立的BG线跟BR线,此时便不需要BS线。每个都独立了,因此优点是相应时间快,还可以随便屏蔽掉某个设备
分布式仲裁
每个设备把自己的仲裁号发到共享的仲裁总线上竞争,每次选出小于一定范围的退出,需要进行多次,竞争期时间要足够,保证速度慢的设备也能参与竞争
总线数据传送模式
1. 读写操作
2. 块传送操作
3. 写后读,读后写操作
4. 广播,广集操作
外存与IO设备
IO系统
DMA传送方式
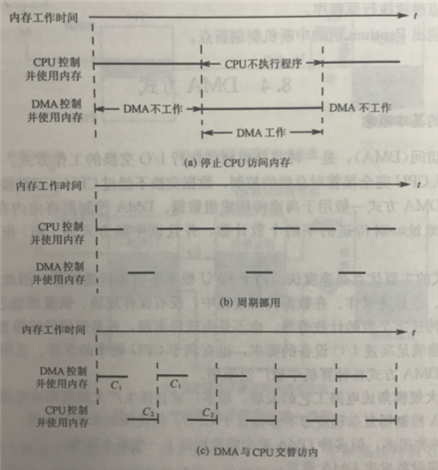
1. 停止CPU访问内存:DMA要使用时,并在DMA完成前,CPU不能访问总线。控制简单,但CPU无法充分利用。基本不使用
2. 周期挪用:在DMA跟CPU都有访问请求。前一个IO设备需要在下一个访内请求前存取完毕,这样不会耽误CPU访内请求,又能兼顾CPU运算,即用一会,还回去,再用一会。适用于IO密集型。
3. DMA与CPU交替访内:DMA跟CPU交替使用内存,比如,规定,每人使用10个时钟周期,由总线控制传输,CPU一样发送访内请求。这样CPU跟DMA都不知道对方的存在,因此也称“透明的DMA”。相应硬件逻辑也更复杂。适用于CPU密集型。
DMA控制器
DMA控制器按通道结构分为选择性DMA控制器和多路型DMA控制器。
选择型DMA:每次从多个中选出一个,传输完一个马上又可以为其他设备服务。适用于数据传输率高以至于接近内存速度的设备。
多路型DMA:同时为多个慢速DMA服务。负责的设备多,因此每个的速度就慢了















 6121
6121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









