







1、SAX解析介绍
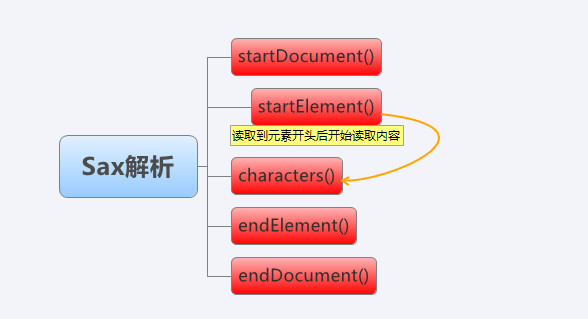
在前文介绍XML的时候介绍过SAX解析,就不过多介绍了。SAX解析是jdk自带的解析方式,所以不用添加jar包引用。SAX解析每次识别出文档中的某些内容,就会生成一个事件。这些事件也就是回调方法,由事件处理函数做相应动作,然后继续同样的解析,直至文档结束。在触发器中,首先开始读取文档,然后开始逐个解析元素,每个元素中的内容会返回到characters()方法接着结束元素读取,所有元素读取完后,结束文档解析,如下图所示:
2、实现思路
(1)首先,针对我们从XML中需要获取的信息,先建立一个实体类,存放相关的信息(2)其次,我们需要新建一个类,继承DefaultHandler,重写其中的一些方法,DefaultHandler它实现了ContentHandler接口。
(3)然后,根据读取的xml路径,传递给SAXParserFactory创建的SAXParser解析器,再调用parse()方法;
(4)最后,在parse()方法中传递DefaultHandler这个类的扩展类的实例,就是第二步中的重写类
(5)注意,解析XML文件的主要工作,是放在DefaultHandler的实现类中的!
3、举例说明
3.1 创建实体类:
public class Person {
private Integer id;
private String name;
private Short age;
public Person(){}
public Person(Integer id, String name, Short age) {
this.id = id;
this.name = name;
this.age = age;
}
// 省略setter()和getter()方法
}3.2 新建类继承DefaultHandler:
public class SAXForHandler extends DefaultHandler {
private static final String TAG = "SAXForHandler";
private List<Person> persons;
private String perTag ;//通过此变量,记录前一个标签的名称。
Person person;//记录当前Person
public List<Person> getPersons() {
return persons;
}
//适合在此事件中触发初始化行为。
public void startDocument() throws SAXException {
persons = new ArrayList<Person>();
Log.i(TAG , "***startDocument()***");
}
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if("person".equals(localName)){
for ( int i = 0; i < attributes.getLength(); i++ ) {
Log.i(TAG ,"attributeName:" + attributes.getLocalName(i)
+ "_attribute_Value:" + attributes.getValue(i));
person = new Person();
person.setId(Integer.valueOf(attributes.getValue(i)));
}
}
perTag = localName;
Log.i(TAG , qName+"***startElement()***");
}
public void characters(char[] ch, int start, int length) throws SAXException {
String data = new String(ch, start, length).trim();
if(!"".equals(data.trim())){
Log.i(TAG ,"content: " + data.trim());
}
if("name".equals(perTag)){
person.setName(data);
}else if("age".equals(perTag)){
person.setAge(new Short(data));
}
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
Log.i(TAG , qName+"***endElement()***");
if("person".equals(localName)){
persons.add(person);
person = null;
}
perTag = null;
}
public void endDocument() throws SAXException {
Log.i(TAG , "***endDocument()***");
}
}
3.3 调用SAXParser解析文档:
InputStream inputStream = this.getClass().getClassLoader().
getResourceAsStream("person.xml");
SAXForHandler saxForHandler = new SAXForHandler();
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
saxParser.parse(inputStream, saxForHandler);
List<Person> persons = saxForHandler.getPersons();
inputStream.close();
for(Person person:persons){
Log.i(TAG, person.toString());
}3.4 解释说明:
(1)startDocument事件,这个事件的调用,只是在解析文档的最开始的时候,执行一些初始化的工作,之后基本上不会再用(2)我们把需要解析的XML文件内容交给解析器之后,解析器就会以流的形式解析文本。
4、注意问题
解析XML有两种形式,需要创建一个XMLReader或者直接使用SAXParser使用XMLReader
XMLReader xmlReader = saxParser.getXMLReader();
xmlReader.setContentHandler(handler);
xmlReader.parse(new InputSource(is));saxParser.parser(is,handler)实际上两者在使用效果上是一样的,在使用上,SAXParser是对XMLReader的一个封装,能够接受更多类型的参数,能方便的对不同数据源的XML文档信息进行解析,而XMLReader在使用上,就比较繁琐一点。















 2334
2334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









