






 本文介绍了cleanRL库中的关键概念,如向量化环境、Critic网络(用于状态价值估计)和Actor网络(生成动作分布),并详细解读了get_action_and_value函数中的操作。同时提到了batch_size、minibatch_size和num_iterations等参数。参考了ppo_continuous_action源码解析。
本文介绍了cleanRL库中的关键概念,如向量化环境、Critic网络(用于状态价值估计)和Actor网络(生成动作分布),并详细解读了get_action_and_value函数中的操作。同时提到了batch_size、minibatch_size和num_iterations等参数。参考了ppo_continuous_action源码解析。
cleanRL官网:Examples - CleanRL
cleanRL的tensorboard:
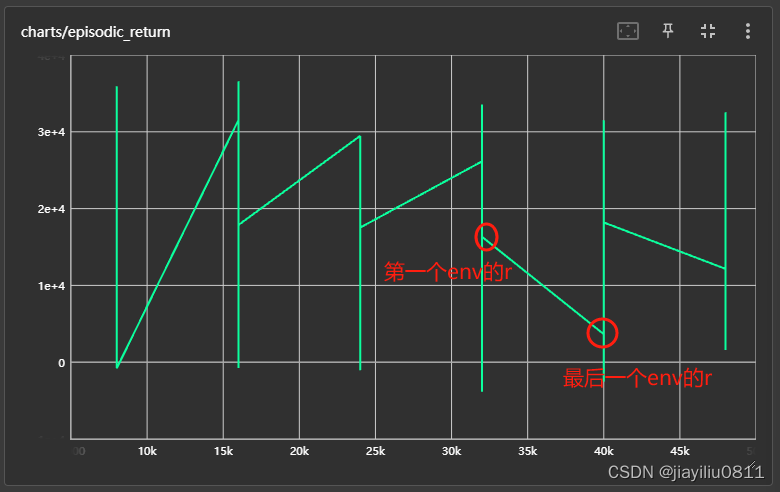
向量化环境:会在回合结束时,自动reset一次
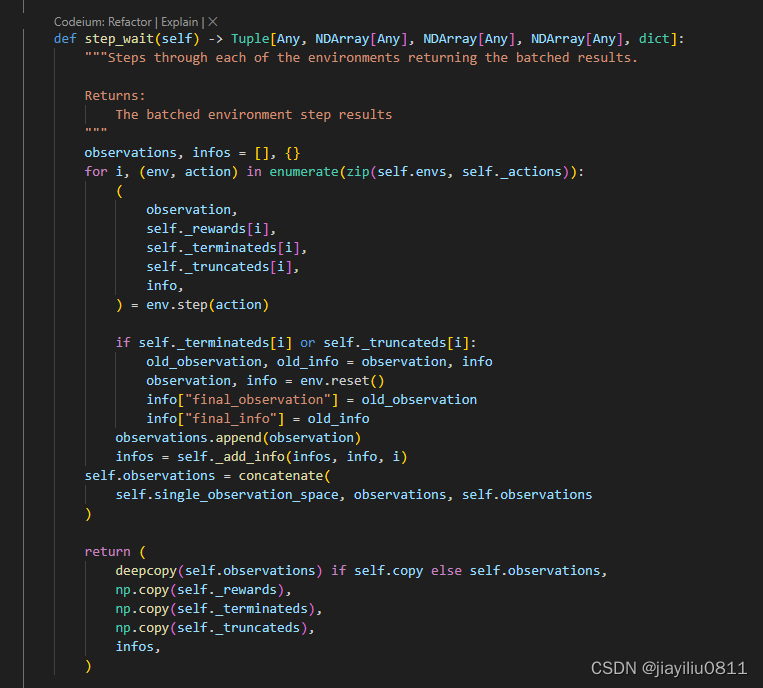
cleanRL代码注解
Critic网络的输入尺寸为(batch_size, obs_dim, 64),输出尺寸为(batch_size, 1),作用是形成obs到value的映射。向外暴露get_value函数以计算状态价值。
Actor网络包含两部分:self.action_mean将obs映射到动作均值,输入尺寸为(batch_size, obs_dim, 64),输出尺寸为(batch_size, action_dim)
self.actor_logstd是一个(1, action_dim)大小的Parameter,用于形成动作方差的对数(后面需要对其使用torch.exp保证其为正数)
get_action_and_value函数中计算了:
- 动作分布
probs - 动作采样
probs.sample() - 对数似然
probs.log_prob(action).sum(1) - 熵
probs.entropy().sum(1) - 状态价值
self.critic(x)
参数释义:
batch_size:num_envs与num_steps的乘积,表示跑一次迭代能收集到多少样本minibatch_size:每次训练都从大的batch中抽取小的minibatch进行训练num_iterations:整个训练过程跑几轮迭代
参考:















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









