






| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年7月2日10:33:05 | V0.1 | 宋全恒 | 新建文档 |
简介
最近笔者一直在进行大模型量化方法smoothquant的理解,真的很痛苦,工作让自己很有压力,也很焦虑,因为在深度学习,pytorch等内容自己可以说是一片空白。在看《动手学深度学习》试图理解注意力机制的时候,基本上,连Pytorch的API都不知道是什么作用,尴尬。
代码片段
def desc_tensor(tensor_name: str, input: torch.Tensor):
print(f"{tensor_name}.shape: {input.shape}, {tensor_name}: {input}")
上述函数就是打印形状和内容。
数据准备
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本特征值,一维
desc_tensor("x_train", x_train)
def f(x):
return 2 * torch.sin(x) + x**0.8
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出,训练样本的输出有噪声
desc_tensor("y_train", y_train)
x_test = torch.arange(0, 5, 0.1) # 测试样本
desc_tensor("x_test", x_test)
y_truth = f(x_test) # 测试样本的真实输出
desc_tensor("y_truth", y_truth)
n_test = len(x_test) # 测试样本数
上述代码完成数据的准备。
上述代码输出为:
x_train.shape: torch.Size([50]), x_train: tensor([0.0736, 0.1322, 0.2616, 0.3973, 0.4368, 0.7189, 0.8092, 1.0006, 1.0852,
1.1395, 1.2161, 1.2728, 1.4399, 1.5584, 1.6083, 1.7416, 2.0141, 2.0670,
2.1935, 2.2082, 2.4173, 2.4371, 2.5372, 2.8215, 2.8556, 2.9002, 3.0286,
3.1282, 3.1787, 3.2221, 3.2794, 3.3748, 3.4067, 3.4859, 3.5163, 3.5940,
3.6314, 3.9116, 4.0168, 4.0484, 4.2881, 4.4079, 4.4449, 4.5230, 4.5395,
4.5820, 4.6896, 4.8165, 4.8539, 4.8894])
y_train.shape: torch.Size([50]), y_train: tensor([ 1.0983, 1.0704, 1.1664, 2.1487, 1.7268, 2.2859, 2.8247, 2.3314,
3.2909, 2.9276, 2.5803, 3.9804, 4.9895, 3.4367, 4.3392, 3.9830,
3.2611, 4.1902, 3.1661, 4.0057, 3.4129, 3.1090, 3.5707, 2.7524,
2.6210, 2.7465, 3.2516, 2.8707, 2.1943, 2.1605, 2.0417, 2.1155,
1.2779, 2.5241, 2.7864, 1.7184, 2.4311, 1.1558, 1.2115, 1.4064,
1.5413, 0.9137, 0.9059, -0.1208, 2.0855, 1.9010, 1.5624, 1.3536,
1.2801, 2.0003])
x_test.shape: torch.Size([50]), x_test: tensor([0.0000, 0.1000, 0.2000, 0.3000, 0.4000, 0.5000, 0.6000, 0.7000, 0.8000,
0.9000, 1.0000, 1.1000, 1.2000, 1.3000, 1.4000, 1.5000, 1.6000, 1.7000,
1.8000, 1.9000, 2.0000, 2.1000, 2.2000, 2.3000, 2.4000, 2.5000, 2.6000,
2.7000, 2.8000, 2.9000, 3.0000, 3.1000, 3.2000, 3.3000, 3.4000, 3.5000,
3.6000, 3.7000, 3.8000, 3.9000, 4.0000, 4.1000, 4.2000, 4.3000, 4.4000,
4.5000, 4.6000, 4.7000, 4.8000, 4.9000])
y_truth.shape: torch.Size([50]), y_truth: tensor([0.0000, 0.3582, 0.6733, 0.9727, 1.2593, 1.5332, 1.7938, 2.0402, 2.2712,
2.4858, 2.6829, 2.8616, 3.0211, 3.1607, 3.2798, 3.3782, 3.4556, 3.5122,
3.5481, 3.5637, 3.5597, 3.5368, 3.4960, 3.4385, 3.3654, 3.2783, 3.1787,
3.0683, 2.9489, 2.8223, 2.6905, 2.5554, 2.4191, 2.2835, 2.1508, 2.0227,
1.9013, 1.7885, 1.6858, 1.5951, 1.5178, 1.4554, 1.4089, 1.3797, 1.3684,
1.3759, 1.4027, 1.4490, 1.5151, 1.6009])
torch.rand(n_train)
在 PyTorch 中,torch.rand() 函数用于生成一个服从均匀分布的随机张量。n_train 通常是一个整数,表示生成的随机张量的大小或形状的某个维度。
例如,如果 n_train 为 100 ,那么 torch.rand(100) 将会返回一个包含 100 个在 0 到 1 之间均匀分布的随机数的一维张量。
再比如,如果 n_train 是一个形如 (50, 20) 的元组,那么 torch.rand((50, 20)) 将会返回一个 50 行 20 列的二维张量,其中的元素均为 0 到 1 之间的随机数。
这种生成随机数的操作在深度学习中非常常见,比如用于初始化模型的参数、生成随机噪声、创建随机训练数据等。
因此上述生成的x_train是经过排序的一维张量
x_train.shape: torch.Size([50]), x_train: tensor([0.0169, 0.0976, 0.1260, 0.1368, 0.2244, 0.4306, 0.4410, 0.5209, 0.5289,
0.6025, 0.6599, 0.7643, 0.7733, 1.4212, 1.5469, 1.6012, 1.7084, 1.7927,
1.9298, 2.2269, 2.3982, 2.5221, 2.6622, 2.7772, 2.8637, 3.1061, 3.2140,
3.2942, 3.4743, 3.5215, 3.5434, 3.6285, 3.7366, 3.7419, 3.8012, 3.8657,
3.8757, 3.9042, 3.9068, 4.0276, 4.0312, 4.1802, 4.2205, 4.2774, 4.3827,
4.4240, 4.7451, 4.7467, 4.8329, 4.9662])
可以认为这些数据是一维的特征,只有一个特征的样本点。
torch.normal(0.0, 0.5, (n_train,)
torch.normal(0.0, 0.5, (n_train,)) 是 PyTorch 中的一个函数,用于生成一个形状为 (n_train,) 的张量,其中的元素是从均值为 0.0 ,标准差为 0.5 的正态分布中随机采样得到的。
例如,如果 n_train = 5 ,那么生成的张量可能类似于 tensor([-0.12, 0.35, -0.47, 0.21, 0.68]) 。
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出,训练样本的输出有噪声
desc_tensor("y_train", y_train)
y_train是根据样本特征的函数输出,并且给了噪声,噪声是由torch.normal实现的。
y_train.shape: torch.Size([50]), y_train: tensor([ 0.0532, -0.3962, 0.3167, 0.0432, 0.4059, 1.7667, 1.9315, 2.2291,
1.5607, 1.1984, 2.2742, 1.5393, 1.9934, 3.4132, 4.1268, 2.9857,
4.1783, 3.3583, 3.8928, 2.8433, 2.7262, 3.5476, 3.6824, 2.8866,
2.8662, 2.6184, 1.5334, 1.7058, 1.4948, 2.5213, 2.1404, 2.0452,
1.5318, 1.7644, 0.8230, 2.0289, 1.9411, 0.9761, 1.6779, 1.1254,
1.2463, 0.8375, 1.0576, 0.9743, 1.6792, 1.1347, 1.2610, 0.9748,
2.1265, 1.1456])
torch.arrange
在 Python 中,torch.arange(0, 5, 0.1) 是使用 PyTorch 库生成一个数值序列的操作。
arange 函数的作用是生成一个按照指定步长在给定范围内的一维张量。
在这个例子中,起始值是 0 ,结束值是 5 (但不包括 5 ),步长是 0.1 。
x_test = torch.arange(0, 5, 0.1) # 测试样本
desc_tensor("x_test", x_test)
输出如下所示:
x_test.shape: torch.Size([50]), x_test: tensor([0.0000, 0.1000, 0.2000, 0.3000, 0.4000, 0.5000, 0.6000, 0.7000, 0.8000,
0.9000, 1.0000, 1.1000, 1.2000, 1.3000, 1.4000, 1.5000, 1.6000, 1.7000,
1.8000, 1.9000, 2.0000, 2.1000, 2.2000, 2.3000, 2.4000, 2.5000, 2.6000,
2.7000, 2.8000, 2.9000, 3.0000, 3.1000, 3.2000, 3.3000, 3.4000, 3.5000,
3.6000, 3.7000, 3.8000, 3.9000, 4.0000, 4.1000, 4.2000, 4.3000, 4.4000,
4.5000, 4.6000, 4.7000, 4.8000, 4.9000])
根据输出样本得到其真实y_truth,去掉噪声即可。不再赘述。
平均注意力汇聚
#平均注意力汇聚
# tensor(2.0133)
print(y_train.mean())
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
desc_tensor("y_hat", y_hat)
输出为:
tensor(1.8758)
y_hat.shape: torch.Size([50]), y_hat: tensor([1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758])

基本上就是估计每个x_test中的所有元素,都使用平均值来估计。所以y_hat均为一样的元素,其值为每个训练样本的输出。训练样本的输出,即y_train
repeat_interleave
torch.repeat_interleave() 是 PyTorch 中的一个函数,用于按指定的方式重复张量中的元素。
函数原型为:
torch.repeat_interleave(input, repeats, dim=None) → Tensor
参数说明:
input:输入的张量。
repeats:用于指定每个元素应该重复的次数。可以是一个整数,表示所有元素的重复次数;也可以是一个与输入张量维度相匹配的张量(会被广播来适应输入张量的维度),指定每个元素的不同重复次数。
dim:沿着哪个维度进行重复。如果为 None,则会将整个张量视为一维,先将输入张量展平为向量,然后将每个元素重复 repeats 次,并返回重复后的张量。
import torch
# 创建一个示例张量
tensor = torch.tensor((1, 2, 3))
# 重复每个元素两次
result = torch.repeat_interleave(tensor, repeats=2)
print(result) # tensor((1, 1, 2, 2, 3, 3))
# 传入多维张量,默认展平
y = torch.tensor(((1, 2), (3, 4)))
torch.repeat_interleave(y, 2)
print(result) # tensor((1, 1, 2, 2, 3, 3, 4, 4))
# 指定维度
torch.repeat_interleave(y, 3, 0)
print(result) # tensor(((1, 2), (1, 2), (1, 2), (3, 4), (3, 4), (3, 4)))
torch.repeat_interleave(y, 3, dim=1)
print(result) # tensor(((1, 1, 1, 2, 2, 2), (3, 3, 3, 4, 4, 4)))
# 指定不同元素重复不同次数
torch.repeat_interleave(y, torch.tensor((1, 2)), dim=0)
print(result) # tensor(((1, 2), (3, 4), (3, 4)))
因此,下述的代码
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
desc_tensor("y_hat", y_hat)
会将均值重复n_test次,有n_test个样本,就有n_test个输出。重复的张量为均值。所以,y_hat最终输出如下:
tensor(1.8758)
y_hat.shape: torch.Size([50]), y_hat: tensor([1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758, 1.8758,
1.8758, 1.8758, 1.8758, 1.8758, 1.8758])
另外,对于非参数注意力汇聚
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
desc_tensor("x_test.repeat_interleave(n_train)", x_test.repeat_interleave(n_train))
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
desc_tensor("X_repeat", X_repeat)
x_test是一个size为50的一维张量,重复n_train,得到的张量为size为2500一维张量,重新reshape((-1, n_train)),可以得到torch.Size([50, 50])
观察数据输出
x_test.repeat_interleave(n_train).shape: torch.Size([2500]), x_test.repeat_interleave(n_train): tensor([0.0000, 0.0000, 0.0000, ..., 4.9000, 4.9000, 4.9000])
X_repeat.shape: torch.Size([50, 50]), X_repeat: tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.1000, 0.1000, 0.1000, ..., 0.1000, 0.1000, 0.1000],
[0.2000, 0.2000, 0.2000, ..., 0.2000, 0.2000, 0.2000],
...,
[4.7000, 4.7000, 4.7000, ..., 4.7000, 4.7000, 4.7000],
[4.8000, 4.8000, 4.8000, ..., 4.8000, 4.8000, 4.8000],
[4.9000, 4.9000, 4.9000, ..., 4.9000, 4.9000, 4.9000]])
其实相当于将每个样本都平铺成了与训练数据大小的一维向量。而训练数据的形状为
x_train.shape: torch.Size([50]), x_train: tensor([0.0464, 0.1128, 0.1603, 0.3447, 0.4062, 0.4840, 0.5957, 0.7545, 0.8199,
0.9850, 1.0124, 1.1479, 1.6265, 1.6271, 1.6857, 1.8017, 1.8471, 1.9210,
1.9900, 2.2928, 2.3209, 2.4196, 2.7914, 2.8065, 2.8819, 2.9643, 2.9759,
2.9759, 3.0450, 3.0513, 3.0672, 3.2207, 3.3531, 3.4449, 3.5675, 3.6859,
3.6904, 3.7664, 3.7733, 3.8745, 3.9900, 4.0378, 4.4568, 4.5311, 4.8160,
4.8700, 4.9068, 4.9236, 4.9528, 4.9992])
曲线
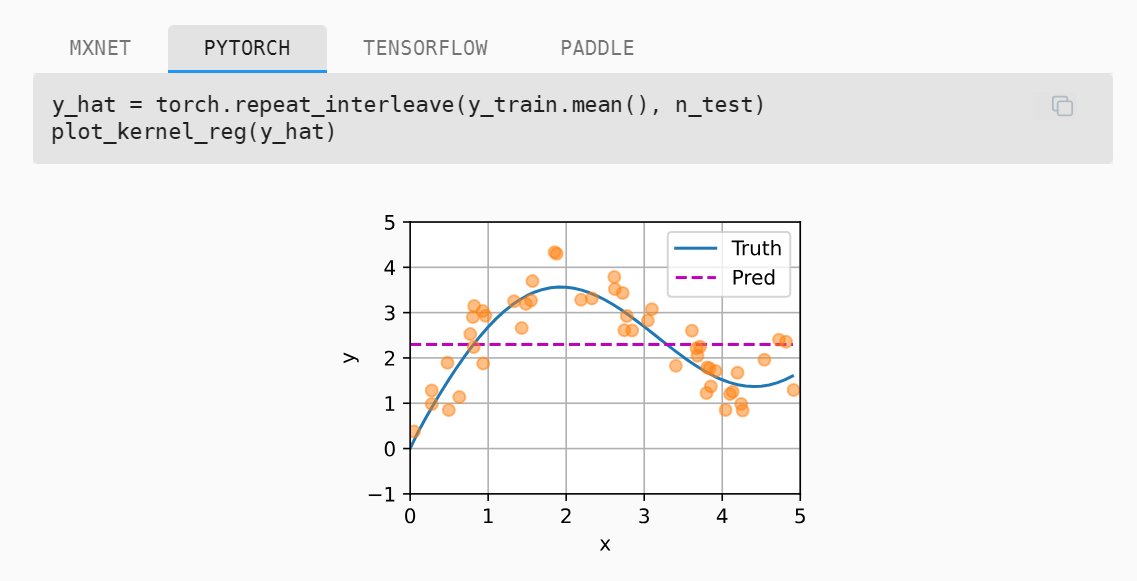
非参数的注意力汇聚
具体的理论如下图所示

# 非参数注意力汇聚
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
desc_tensor("x_test.repeat_interleave(n_train)", x_test.repeat_interleave(n_train))
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
desc_tensor("X_repeat", X_repeat)
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重, dim=1,表示水平方向执行softmax
# 每个测试样本都有一个权重向量,用来分配给训练样本的值,所以X_repeat的第0维代表测试样本数目。
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
desc_tensor("attention_weights", attention_weights)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
desc_tensor("y_hat", y_hat)
x_test.repeat_interleave(n_train).reshape((-1, n_train))
可以说这个是理解的最关键的地方。
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
desc_tensor("x_test.repeat_interleave(n_train)", x_test.repeat_interleave(n_train))
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
desc_tensor("X_repeat", X_repeat)
观察输出就能理解其作用
x_test.repeat_interleave(n_train).shape: torch.Size([2500]), x_test.repeat_interleave(n_train): tensor([0.0000, 0.0000, 0.0000, ..., 4.9000, 4.9000, 4.9000])
X_repeat.shape: torch.Size([50, 50]), X_repeat: tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.1000, 0.1000, 0.1000, ..., 0.1000, 0.1000, 0.1000],
[0.2000, 0.2000, 0.2000, ..., 0.2000, 0.2000, 0.2000],
...,
[4.7000, 4.7000, 4.7000, ..., 4.7000, 4.7000, 4.7000],
[4.8000, 4.8000, 4.8000, ..., 4.8000, 4.8000, 4.8000],
[4.9000, 4.9000, 4.9000, ..., 4.9000, 4.9000, 4.9000]])
对于X_repeat[1],其值如下为:
desc_tensor("X_repeat[1]", X_repeat[1])
X_repeat[1].shape: torch.Size([50]), X_repeat[1]: tensor([0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,
0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,
0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,
0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,
0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,
0.1000, 0.1000, 0.1000, 0.1000, 0.1000])
可以非常直观的,其为一个Size为训练样本个数的,每个值都为特征值的一维向量。而x_train代表了每一个训练样本的特征值。
x_train: tensor([0.0464, 0.1128, 0.1603, 0.3447, 0.4062, 0.4840, 0.5957, 0.7545, 0.8199,
0.9850, 1.0124, 1.1479, 1.6265, 1.6271, 1.6857, 1.8017, 1.8471, 1.9210,
1.9900, 2.2928, 2.3209, 2.4196, 2.7914, 2.8065, 2.8819, 2.9643, 2.9759,
2.9759, 3.0450, 3.0513, 3.0672, 3.2207, 3.3531, 3.4449, 3.5675, 3.6859,
3.6904, 3.7664, 3.7733, 3.8745, 3.9900, 4.0378, 4.4568, 4.5311, 4.8160,
4.8700, 4.9068, 4.9236, 4.9528, 4.9992])
只要X_repeat[1]和X_train进行注意力函数计算,就可以得到该样本的注意力权重向量。而这是理解注意力权重的关键。
如果一个键𝑥𝑖越是接近给定的查询𝑥, 那么分配给这个键对应值𝑦𝑖的注意力权重就会越大, 也就“获得了更多的注意力”。
推而广之,就可以得到每个样本的注意力权重向量。
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重, dim=1,表示水平方向执行softmax
# 每个测试样本都有一个权重向量,用来分配给训练样本的值,所以X_repeat的第0维代表测试样本数目。
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
desc_tensor("attention_weights", attention_weights)
attention_weights.shape: torch.Size([50, 50]), attention_weights: tensor([[7.9322e-02, 7.8703e-02, 7.4210e-02, ..., 1.9919e-06, 1.9906e-06,
3.1810e-07],
[7.4538e-02, 7.4164e-02, 7.1046e-02, ..., 2.8908e-06, 2.8888e-06,
4.7962e-07],
[6.9811e-02, 6.9658e-02, 6.7795e-02, ..., 4.1814e-06, 4.1787e-06,
7.2078e-07],
...,
[3.8590e-06, 4.3718e-06, 8.6768e-06, ..., 7.2127e-02, 7.2128e-02,
6.9390e-02],
[2.6456e-06, 3.0056e-06, 6.0604e-06, ..., 7.6366e-02, 7.6368e-02,
7.6329e-02],
[1.8052e-06, 2.0567e-06, 4.2132e-06, ..., 8.0476e-02, 8.0480e-02,
8.3571e-02]])
y_hat = torch.matmul(attention_weights, y_train)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
desc_tensor("y_hat", y_hat)
上述代码,就是计算输入样本向量,得到样本向量的注意力权重矩阵,由注意力权重与训练样本的输出值得到每个测试样本点额预测值。
输出为:
y_hat.shape: torch.Size([50]), y_hat: tensor([1.8532, 1.8984, 1.9455, 1.9945, 2.0452, 2.0976, 2.1516, 2.2069, 2.2632,
2.3201, 2.3771, 2.4338, 2.4895, 2.5434, 2.5950, 2.6435, 2.6883, 2.7286,
2.7639, 2.7937, 2.8177, 2.8355, 2.8471, 2.8523, 2.8512, 2.8438, 2.8305,
2.8113, 2.7866, 2.7567, 2.7219, 2.6828, 2.6397, 2.5931, 2.5436, 2.4917,
2.4381, 2.3833, 2.3279, 2.2726, 2.2178, 2.1642, 2.1121, 2.0621, 2.0143,
1.9690, 1.9265, 1.8868, 1.8498, 1.8157])
带参数的注意力汇聚
非参数的Nadaraya-Watson核回归具有一致性(consistency)的优点: 如果有足够的数据,此模型会收敛到最优结果。 尽管如此,我们还是可以轻松地将可学习的参数集成到注意力汇聚中。
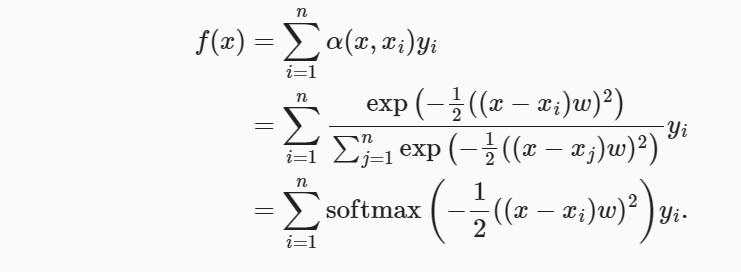
在注意力机制的背景中,我们可以使用小批量矩阵乘法来计算小批量数据中的加权平均值。
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
输出为:
tensor([[[ 4.5000]],
[[14.5000]]])
整体代码如下所示:
# 有参数的注意力汇聚
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
print(f"keys.shape[1]: {keys.shape[1]}")
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
desc_tensor("queries", queries)
desc_tensor("keys", keys)
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
desc_tensor("X_tile", X_tile)
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
desc_tensor("y_train.repeat((n_train))", y_train.repeat((n_train)))
desc_tensor("(1 - torch.eye(n_train)).type(torch.bool)", (1 - torch.eye(n_train)).type(torch.bool))
desc_tensor("X_tile[(1 - torch.eye(n_train)).type(torch.bool)]", X_tile[(1 - torch.eye(n_train)).type(torch.bool)])
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
desc_tensor("keys", keys)
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
torch.unsqueeze
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
具体可以参见 06-27 周四 理解torch.squeeze和unsqueeze
x_train.repeat((n_train, 1))
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
desc_tensor("X_tile", X_tile)
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
desc_tensor("y_train.repeat((n_train))", y_train.repeat((n_train)))
desc_tensor("y_train.repeat((n_train))", y_train.repeat((n_train)))
这个也是自己吃不准的一个点,先观察输出数据的规律
x_train.shape: torch.Size([50]), x_train: tensor([0.0080, 0.1126, 0.2243, 0.4227, 0.4530, 0.4641, 0.6772, 0.6974, 0.7801,
0.8157, 1.0047, 1.1698, 1.2155, 1.2209, 1.2784, 1.3083, 1.3226, 1.3716,
1.4326, 1.4574, 1.7757, 1.8574, 1.8607, 2.1956, 2.3369, 2.4488, 2.5350,
2.7527, 2.7608, 2.8140, 3.0537, 3.1229, 3.1685, 3.2174, 3.3556, 3.4792,
3.5381, 3.5654, 3.6416, 3.8366, 3.8523, 3.9104, 3.9585, 4.0991, 4.2512,
4.4546, 4.6719, 4.7526, 4.7701, 4.8853])
X_tile.shape: torch.Size([50, 50]), X_tile: tensor([[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
...,
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853]])
Y_tile.shape: torch.Size([50, 50]), Y_tile: tensor([[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
...,
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116]])
y_train.repeat((n_train)).shape: torch.Size([2500]), y_train.repeat((n_train)): tensor([ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116])
X-tile相当于将x_train重复了50次。而Y_tile一样,代表的事每个位置对应的训练样本的标签。代码还演示了y_train.repeat((n_train)).shape,可以看到,在这种情况下,生成的张量Size为2500.
索引张量
当使用布尔张量(bool 张量)作为索引来检索二维张量中的数据时,结果会得到一个新的一维张量,该张量包含了原始二维张量中与布尔张量中 True 位置相对应的元素。
也就是说,布尔张量中 True 对应的位置,会把二维张量数据中相应位置的元素取出来,组成一个新的一维张量。
例如,假设有一个二维张量 tensor 和一个布尔张量 mask ,通过 tensor[mask] 就可以得到满足 mask 中 True 条件的对应元素所组成的一维张量。
以下是一个使用 PyTorch 示例代码来说明的过程:
python
Copy
import torch
# 创建一个示例的二维张量
tensor = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 创建一个布尔张量作为索引
mask = torch.tensor([[True, False, True],
[False, True, False],
[True, False, True]])
# 使用布尔张量进行索引
result = tensor[mask]
print(result)
在上述示例中,mask 张量中为 True 的位置对应了 tensor 中的元素 1、3、5、7 和 9,所以最终的结果 result 是一个包含这些元素的一维张量。
需要注意的是,使用布尔索引时,总是会返回一个新创建的数据,而原始的二维张量不会被改变。并且,布尔张量和原始二维张量的形状需要是可以广播的,也就是说它们在某些维度上可以自动扩展或收缩以匹配对方的形状,以便进行正确的索引操作。不同的深度学习框架可能会有一些细微的差别,但总体的原理是相似的。如果你使用的是其他框架,请参考相应框架的文档来了解具体的细节和语法。
X_tile[(1 - torch.eye(n_train)).type(torch.bool)]
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
desc_tensor("(1 - torch.eye(n_train)).type(torch.bool)", (1 - torch.eye(n_train)).type(torch.bool))
desc_tensor("X_tile[(1 - torch.eye(n_train)).type(torch.bool)]", X_tile[(1 - torch.eye(n_train)).type(torch.bool)])
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
desc_tensor("keys", keys)
输出为
X_tile.shape: torch.Size([50, 50]), X_tile: tensor([[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
...,
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.7526, 4.7701, 4.8853]])
(1 - torch.eye(n_train)).type(torch.bool).shape: torch.Size([50, 50]), (1 - torch.eye(n_train)).type(torch.bool): tensor([[False, True, True, ..., True, True, True],
[ True, False, True, ..., True, True, True],
[ True, True, False, ..., True, True, True],
...,
[ True, True, True, ..., False, True, True],
[ True, True, True, ..., True, False, True],
[ True, True, True, ..., True, True, False]])
X_tile[(1 - torch.eye(n_train)).type(torch.bool)].shape: torch.Size([2450]), X_tile[(1 - torch.eye(n_train)).type(torch.bool)]: tensor([0.1126, 0.2243, 0.4227, ..., 4.6719, 4.7526, 4.7701])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.1126, 0.2243, 0.4227, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.2243, 0.4227, ..., 4.7526, 4.7701, 4.8853],
[0.0080, 0.1126, 0.4227, ..., 4.7526, 4.7701, 4.8853],
...,
[0.0080, 0.1126, 0.2243, ..., 4.6719, 4.7701, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.6719, 4.7526, 4.8853],
[0.0080, 0.1126, 0.2243, ..., 4.6719, 4.7526, 4.7701]])
keys.shape[1]: 49
理解了上述根据bool索引索引张量的情形之后,就比较好理解上述代码了。
而values
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
输出为
Y_tile.shape: torch.Size([50, 50]), Y_tile: tensor([[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
...,
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116],
[ 0.4227, -0.4596, 1.1265, ..., 1.5574, 1.5653, 1.3116]])
values.shape: torch.Size([50, 49]), values: tensor([[-0.0254, 1.1587, 0.7200, ..., 1.3849, 1.0986, 2.3063],
[ 1.1319, 1.1587, 0.7200, ..., 1.3849, 1.0986, 2.3063],
[ 1.1319, -0.0254, 0.7200, ..., 1.3849, 1.0986, 2.3063],
...,
[ 1.1319, -0.0254, 1.1587, ..., 1.5425, 1.0986, 2.3063],
[ 1.1319, -0.0254, 1.1587, ..., 1.5425, 1.3849, 2.3063],
[ 1.1319, -0.0254, 1.1587, ..., 1.5425, 1.3849, 1.0986]])
torch.eye
torch.eye 是 PyTorch 库中的一个函数,用于创建一个单位矩阵(identity matrix)。
单位矩阵是一个主对角线元素为 1,其余元素为 0 的方阵。
以下是一个使用 torch.eye 的示例代码:
import torch
# 创建一个 3x3 的单位矩阵
identity_matrix = torch.eye(3)
print(identity_matrix)
训练过程分析
# 有参数的注意力汇聚
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
print(f"keys.shape[1]: {keys.shape[1]}")
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
desc_tensor("queries", queries)
desc_tensor("keys", keys)
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
desc_tensor("self.attention_weights.unsqueeze(1)", self.attention_weights.unsqueeze(1))
desc_tensor("values.unsqueeze(-1)", values.unsqueeze(-1))
desc_tensor("self.attention_weights", self.attention_weights)
result = torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
desc_tensor("result", result)
return result
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
整体输出结果如下所示:
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012]],
[[0.0408, 0.0410, 0.0410, ..., 0.0017, 0.0017, 0.0015]],
[[0.0378, 0.0385, 0.0386, ..., 0.0019, 0.0019, 0.0018]],
...,
[[0.0013, 0.0018, 0.0022, ..., 0.0444, 0.0444, 0.0444]],
[[0.0013, 0.0018, 0.0022, ..., 0.0446, 0.0446, 0.0446]],
[[0.0012, 0.0017, 0.0021, ..., 0.0456, 0.0456, 0.0456]]],
grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012],
[0.0408, 0.0410, 0.0410, ..., 0.0017, 0.0017, 0.0015],
[0.0378, 0.0385, 0.0386, ..., 0.0019, 0.0019, 0.0018],
...,
[0.0013, 0.0018, 0.0022, ..., 0.0444, 0.0444, 0.0444],
[0.0013, 0.0018, 0.0022, ..., 0.0446, 0.0446, 0.0446],
[0.0012, 0.0017, 0.0021, ..., 0.0456, 0.0456, 0.0456]],
grad_fn=<SoftmaxBackward0>)
result.shape: torch.Size([50]), result:
tensor([2.6708, 2.6724, 2.7030, 2.6391, 2.6704, 2.6802, 2.6765, 2.6743, 2.6786,
2.6684, 2.6742, 2.6767, 2.6856, 2.6920, 2.6831, 2.6653, 2.6811, 2.6626,
2.6882, 2.6612, 2.6531, 2.6516, 2.6576, 2.6362, 2.6461, 2.6379, 2.6087,
2.6194, 2.6069, 2.6263, 2.6099, 2.6178, 2.5972, 2.5616, 2.5257, 2.5476,
2.5324, 2.5129, 2.4957, 2.4388, 2.4172, 2.3935, 2.3419, 2.3212, 2.2719,
2.2970, 2.2273, 2.2297, 2.2340, 2.1866], grad_fn=<ViewBackward0>)
epoch 1, loss 45.286987
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[1.0000e+00, 1.8949e-07, 5.8606e-08, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[4.2845e-03, 6.1174e-01, 3.8035e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[2.1042e-11, 1.5855e-02, 7.3026e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
...,
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7562e-01,
3.9396e-01, 2.2565e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4250e-01,
3.8914e-01, 2.6572e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2600e-01,
3.5301e-01, 4.2085e-01]]], grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[1.0000e+00, 1.8949e-07, 5.8606e-08, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[4.2845e-03, 6.1174e-01, 3.8035e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[2.1042e-11, 1.5855e-02, 7.3026e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
...,
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7562e-01, 3.9396e-01,
2.2565e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4250e-01, 3.8914e-01,
2.6572e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2600e-01, 3.5301e-01,
4.2085e-01]], grad_fn=<SoftmaxBackward0>)
result.shape: torch.Size([50]), result:
tensor([0.7730, 1.0293, 1.8906, 0.7111, 1.3232, 2.4632, 2.6642, 2.5581, 2.6834,
3.1112, 3.1901, 3.2107, 2.7483, 2.9665, 3.5804, 3.3067, 3.6816, 3.3278,
3.6952, 3.7707, 3.7031, 3.6863, 3.8162, 3.2543, 3.6103, 3.8478, 3.3332,
3.6108, 3.2388, 3.5525, 3.2751, 2.2200, 2.1697, 2.7777, 1.9013, 2.0239,
1.9653, 1.6203, 2.0469, 1.1035, 1.4041, 1.2050, 1.3945, 1.4993, 0.8547,
1.5829, 1.5999, 1.7047, 1.7837, 1.5318], grad_fn=<ViewBackward0>)
epoch 2, loss 13.764773
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[1.0000e+00, 2.3913e-07, 7.5275e-08, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[4.6008e-03, 6.0969e-01, 3.8180e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[3.0155e-11, 1.6711e-02, 7.2662e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
...,
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7494e-01,
3.9297e-01, 2.2697e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4233e-01,
3.8820e-01, 2.6660e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2742e-01,
3.5286e-01, 4.1956e-01]]], grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[1.0000e+00, 2.3913e-07, 7.5275e-08, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[4.6008e-03, 6.0969e-01, 3.8180e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[3.0155e-11, 1.6711e-02, 7.2662e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
...,
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7494e-01, 3.9297e-01,
2.2697e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4233e-01, 3.8820e-01,
2.6660e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2742e-01, 3.5286e-01,
4.1956e-01]], grad_fn=<SoftmaxBackward0>)
result.shape: torch.Size([50]), result:
tensor([0.7730, 1.0320, 1.8878, 0.7139, 1.3218, 2.4614, 2.6642, 2.5587, 2.6849,
3.1108, 3.1899, 3.2106, 2.7486, 2.9667, 3.5792, 3.3075, 3.6798, 3.3274,
3.6945, 3.7689, 3.7025, 3.6859, 3.8157, 3.2548, 3.6094, 3.8442, 3.3336,
3.6080, 3.2407, 3.5529, 3.2765, 2.2206, 2.1717, 2.7758, 1.9039, 2.0274,
1.9641, 1.6203, 2.0452, 1.1041, 1.4041, 1.2081, 1.3938, 1.4984, 0.8557,
1.5830, 1.6008, 1.7054, 1.7842, 1.5322], grad_fn=<ViewBackward0>)
epoch 3, loss 13.725468
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[1.0000e+00, 3.0133e-07, 9.6533e-08, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[4.9380e-03, 6.0764e-01, 3.8322e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[4.3114e-11, 1.7606e-02, 7.2296e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
...,
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7425e-01,
3.9197e-01, 2.2829e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4215e-01,
3.8726e-01, 2.6748e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2884e-01,
3.5270e-01, 4.1827e-01]]], grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[1.0000e+00, 3.0133e-07, 9.6533e-08, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[4.9380e-03, 6.0764e-01, 3.8322e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[4.3114e-11, 1.7606e-02, 7.2296e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
...,
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7425e-01, 3.9197e-01,
2.2829e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4215e-01, 3.8726e-01,
2.6748e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.2884e-01, 3.5270e-01,
4.1827e-01]], grad_fn=<SoftmaxBackward0>)
result.shape: torch.Size([50]), result:
tensor([0.7730, 1.0347, 1.8849, 0.7167, 1.3204, 2.4595, 2.6643, 2.5593, 2.6864,
3.1104, 3.1897, 3.2104, 2.7490, 2.9668, 3.5780, 3.3083, 3.6780, 3.3270,
3.6938, 3.7671, 3.7019, 3.6854, 3.8151, 3.2554, 3.6084, 3.8406, 3.3340,
3.6053, 3.2426, 3.5532, 3.2779, 2.2214, 2.1737, 2.7739, 1.9066, 2.0310,
1.9629, 1.6202, 2.0435, 1.1048, 1.4040, 1.2113, 1.3931, 1.4975, 0.8568,
1.5830, 1.6016, 1.7061, 1.7846, 1.5326], grad_fn=<ViewBackward0>)
epoch 4, loss 13.686062
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[1.0000e+00, 3.7916e-07, 1.2360e-07, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[5.2973e-03, 6.0556e-01, 3.8462e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[6.1495e-11, 1.8541e-02, 7.1927e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
...,
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7356e-01,
3.9096e-01, 2.2959e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4197e-01,
3.8632e-01, 2.6835e-01]],
[[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.3025e-01,
3.5254e-01, 4.1699e-01]]], grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[1.0000e+00, 3.7916e-07, 1.2360e-07, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[5.2973e-03, 6.0556e-01, 3.8462e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
[6.1495e-11, 1.8541e-02, 7.1927e-01, ..., 0.0000e+00, 0.0000e+00,
0.0000e+00],
...,
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.7356e-01, 3.9096e-01,
2.2959e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 3.4197e-01, 3.8632e-01,
2.6835e-01],
[0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.3025e-01, 3.5254e-01,
4.1699e-01]], grad_fn=<SoftmaxBackward0>)
result.shape: torch.Size([50]), result:
tensor([0.7730, 1.0373, 1.8820, 0.7195, 1.3189, 2.4576, 2.6644, 2.5600, 2.6879,
3.1100, 3.1895, 3.2103, 2.7495, 2.9670, 3.5768, 3.3091, 3.6762, 3.3265,
3.6931, 3.7653, 3.7013, 3.6849, 3.8146, 3.2560, 3.6075, 3.8370, 3.3344,
3.6025, 3.2446, 3.5536, 3.2793, 2.2222, 2.1757, 2.7720, 1.9091, 2.0346,
1.9618, 1.6202, 2.0417, 1.1054, 1.4040, 1.2146, 1.3924, 1.4967, 0.8580,
1.5831, 1.6024, 1.7068, 1.7850, 1.5330], grad_fn=<ViewBackward0>)
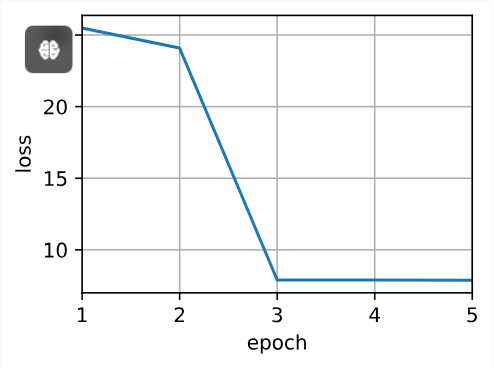
epoch 5, loss 13.646553
进入循环时候,forward三个参数的取值如下所示:
x_train.shape: torch.Size([50]), x_train:
tensor([0.0275, 0.2534, 0.4027, 0.4116, 0.4814, 0.7350, 0.9525, 0.9893, 1.0756,
1.2226, 1.2445, 1.2630, 1.4367, 1.4376, 1.6184, 1.6724, 1.7035, 1.7405,
1.8590, 1.9831, 2.0216, 2.0287, 2.0664, 2.3298, 2.3379, 2.4487, 2.4836,
2.5276, 2.5991, 2.6170, 2.6273, 2.8346, 2.9432, 3.0862, 3.2165, 3.3258,
3.4001, 3.4257, 3.6092, 3.8970, 4.0259, 4.0832, 4.2058, 4.4121, 4.5847,
4.6085, 4.7533, 4.7725, 4.7821, 4.8301])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
values.shape: torch.Size([50, 49]), values:
tensor([[0.7730, 0.3867, 2.0678, ..., 1.5573, 1.4135, 2.2149],
[0.2395, 0.3867, 2.0678, ..., 1.5573, 1.4135, 2.2149],
[0.2395, 0.7730, 2.0678, ..., 1.5573, 1.4135, 2.2149],
...,
[0.2395, 0.7730, 0.3867, ..., 1.7128, 1.4135, 2.2149],
[0.2395, 0.7730, 0.3867, ..., 1.7128, 1.5573, 2.2149],
[0.2395, 0.7730, 0.3867, ..., 1.7128, 1.5573, 1.4135]])
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
这个要看一下数据转变,基本上由于keys.shape[1]变成了49,因此相当于重复49次,得到的结果为tensor.Size(50,49)
print(f"keys.shape[1]: {keys.shape[1]}")
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
desc_tensor("queries", queries)
desc_tensor("keys", keys)
输出结果为:
keys.shape[1]: 49
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
可以看到,每一个训练样本数据和所有其他的数据进行注意力权重计算。
带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
queries.shape: torch.Size([50, 49]), queries:
tensor([[0.0275, 0.0275, 0.0275, ..., 0.0275, 0.0275, 0.0275],
[0.2534, 0.2534, 0.2534, ..., 0.2534, 0.2534, 0.2534],
[0.4027, 0.4027, 0.4027, ..., 0.4027, 0.4027, 0.4027],
...,
[4.7725, 4.7725, 4.7725, ..., 4.7725, 4.7725, 4.7725],
[4.7821, 4.7821, 4.7821, ..., 4.7821, 4.7821, 4.7821],
[4.8301, 4.8301, 4.8301, ..., 4.8301, 4.8301, 4.8301]])
keys.shape: torch.Size([50, 49]), keys:
tensor([[0.2534, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.4027, 0.4116, ..., 4.7725, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4116, ..., 4.7725, 4.7821, 4.8301],
...,
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7821, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.8301],
[0.0275, 0.2534, 0.4027, ..., 4.7533, 4.7725, 4.7821]])
看着这个queries和keys,会发现,两个张量形状相同,都没有使用广播,其实理解起来还是比较容器的。就能得到attention_weights
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
desc_tensor("self.attention_weights.unsqueeze(1)", self.attention_weights.unsqueeze(1))
desc_tensor("values.unsqueeze(-1)", values.unsqueeze(-1))
desc_tensor("self.attention_weights", self.attention_weights)
输出结果为:
self.attention_weights.shape: torch.Size([50, 49]), self.attention_weights:
tensor([[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012],
[0.0408, 0.0410, 0.0410, ..., 0.0017, 0.0017, 0.0015],
[0.0378, 0.0385, 0.0386, ..., 0.0019, 0.0019, 0.0018],
...,
[0.0013, 0.0018, 0.0022, ..., 0.0444, 0.0444, 0.0444],
[0.0013, 0.0018, 0.0022, ..., 0.0446, 0.0446, 0.0446],
[0.0012, 0.0017, 0.0021, ..., 0.0456, 0.0456, 0.0456]],
grad_fn=<SoftmaxBackward0>)
self.attention_weights.unsqueeze(1).shape: torch.Size([50, 1, 49]), self.attention_weights.unsqueeze(1):
tensor([[[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012]],
[[0.0408, 0.0410, 0.0410, ..., 0.0017, 0.0017, 0.0015]],
[[0.0378, 0.0385, 0.0386, ..., 0.0019, 0.0019, 0.0018]],
...,
[[0.0013, 0.0018, 0.0022, ..., 0.0444, 0.0444, 0.0444]],
[[0.0013, 0.0018, 0.0022, ..., 0.0446, 0.0446, 0.0446]],
[[0.0012, 0.0017, 0.0021, ..., 0.0456, 0.0456, 0.0456]]],
grad_fn=<UnsqueezeBackward0>)
values.unsqueeze(-1).shape: torch.Size([50, 49, 1]), values.unsqueeze(-1):
tensor([[[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]],
...,
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.4135],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[2.2149]],
[[0.2395],
[0.7730],
[0.3867],
...,
[1.7128],
[1.5573],
[1.4135]]])
上述就是使用了批量矩阵乘,(50, 1, 49) 和(50, 49, 1)得到的结果为(50, 1, 1)。values.unsqueeze(-1)得到的49个元素,是不断重复的。其实就是训练的输出值。而self.attention_weights.unsqueeze(1)相当于每个样本在其他49个训练样本特征的权重向量。
self.attention_weights.unsqueeze(1):
tensor([[[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012]],#样本0和49个元素的权重矩阵
[[0.0408, 0.0410, 0.0410, ..., 0.0017, 0.0017, 0.0015]],#样本1和49个元素的权重矩阵
[[0.0378, 0.0385, 0.0386, ..., 0.0019, 0.0019, 0.0018]],#样本2和49个元素的权重矩阵
...,
[[0.0013, 0.0018, 0.0022, ..., 0.0444, 0.0444, 0.0444]],#样本47和49个元素的权重矩阵
[[0.0013, 0.0018, 0.0022, ..., 0.0446, 0.0446, 0.0446]],#样本48和49个元素的权重矩阵
[[0.0012, 0.0017, 0.0021, ..., 0.0456, 0.0456, 0.0456]]],#样本49和49个元素的权重矩阵
grad_fn=<UnsqueezeBackward0>)
torch.bmm
对于样本0相对于其他49个样本的权重注意力矩阵值如下所示:
[0.0453, 0.0447, 0.0446, ..., 0.0013, 0.0013, 0.0012],#样本0和49个元素的权重矩阵
# 为49个标签值
[0.7730],
[0.3867],
[2.0678],
...,
[1.5573],
[1.4135],
[2.2149]
矩阵相乘相等于计算了号样本的注意力汇聚加权和。
result = torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
desc_tensor("result", result)
输出结果为
result.shape: torch.Size([50]), result:
tensor([2.6708, 2.6724, 2.7030, 2.6391, 2.6704, 2.6802, 2.6765, 2.6743, 2.6786,
2.6684, 2.6742, 2.6767, 2.6856, 2.6920, 2.6831, 2.6653, 2.6811, 2.6626,
2.6882, 2.6612, 2.6531, 2.6516, 2.6576, 2.6362, 2.6461, 2.6379, 2.6087,
2.6194, 2.6069, 2.6263, 2.6099, 2.6178, 2.5972, 2.5616, 2.5257, 2.5476,
2.5324, 2.5129, 2.4957, 2.4388, 2.4172, 2.3935, 2.3419, 2.3212, 2.2719,
2.2970, 2.2273, 2.2297, 2.2340, 2.1866], grad_fn=<ViewBackward0>)
通过torch.bmm(self.attention_weights.unsqueeze(1),values.unsqueeze(-1))形成的效果,将权重矩阵的一行看成一个整体,values.unsqueeze(-1)将列看成一个整体。
l = loss(net(x_train, keys, values), y_train)
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
对于上述的训练循环,net()的输出为torch.Size([50]),可以与y_train进行均方误差的统计,求和即可得到所有样本的输出。
以该模型进行预测,可以看到新模型不平滑了。
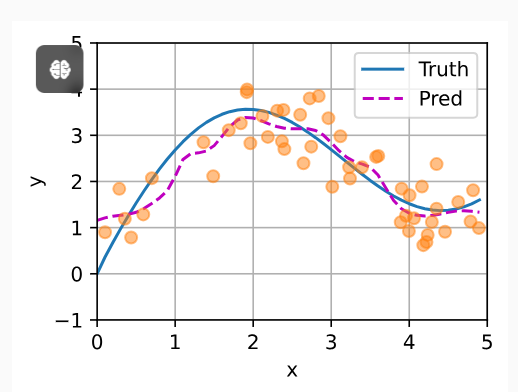
总结
其实这就是注意力评分函数
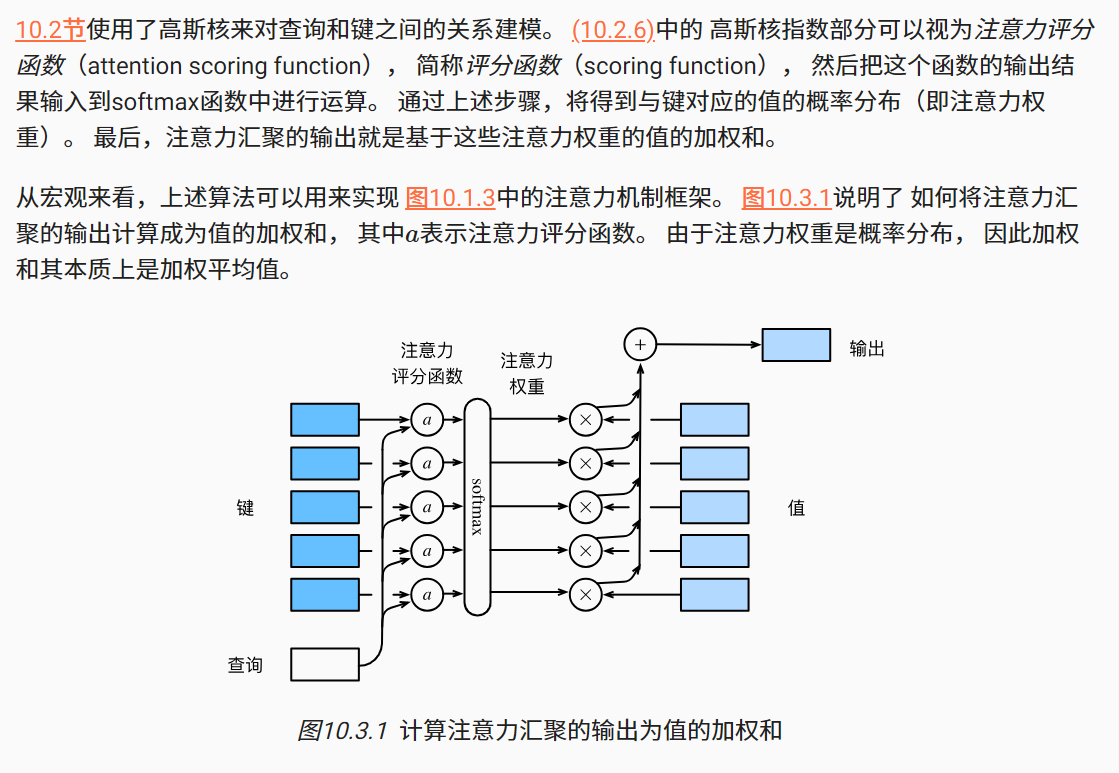
在理解自注意力,上图是非常形象的一种表示,上图中查询是一个值,但实际的时候,应该是一批数据,所以会使用torch.bmm,这个还是非常直观的,对于一个查询,其和所有的键根据注意力评分函数计算注意力权重向量,然后与值进行加权和最终得到了输出结果,这边是注意力的全部含义。
理解这个的过程是非常辛苦的,Pytorch是一门数据的科学,计算的科学,是非常凝练的一门学科。















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









