







背景
最近负责的一个自研的 Dubbo 注册中心经常收到 CPU 使用率的告警,于是进行了一波优化,效果还不错,于是打算分享下思考、优化过程,希望对大家有一些帮助。
自研 Dubbo 注册中心是个什么东西,我画个简图大家稍微感受一下就好,看不懂也没关系,不影响后续的理解。
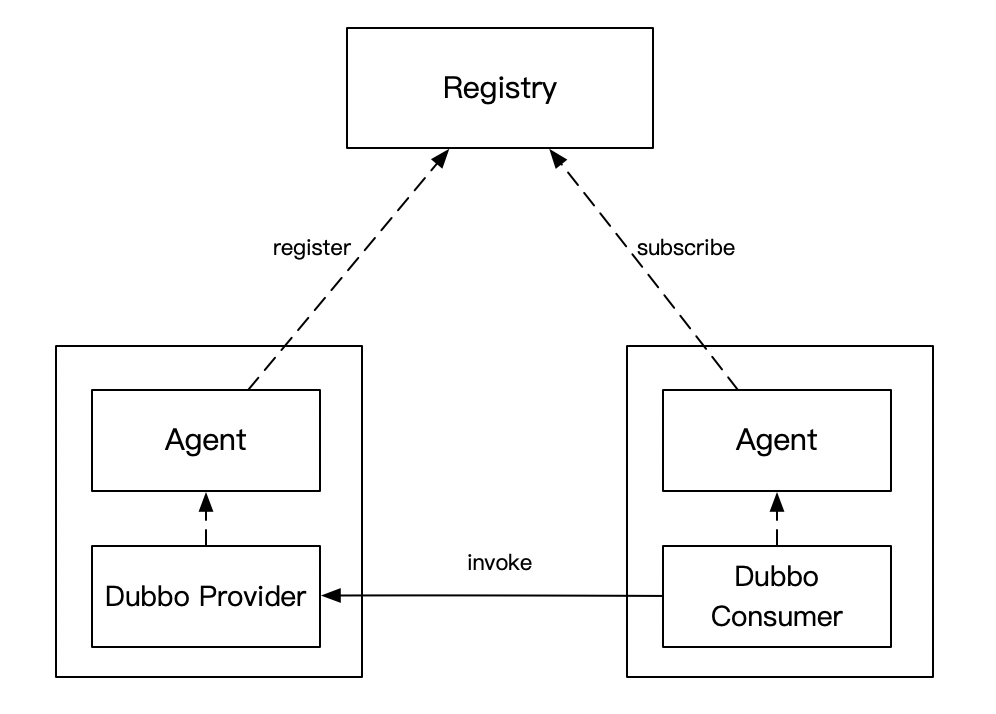
- Consumer 和 Provider 的服务发现请求(注册、注销、订阅)都发给 Agent,由它全权代理
- Registry 和 Agent 保持 Grpc 长链接,长链接的目的主要是 Provider 方有变更时,能及时推送给相应的 Consumer。为了保证数据的正确性,做了推拉结合的机制,Agent 会每隔一段时间去 Registry 拉取订阅的服务列表
- Agent 和业务服务部署在同一台机器上,类似 Service Mesh 的思路,尽量减少对业务的入侵,这样就能快速的迭代了
回到今天的重点,这个注册中心最近 CPU 使用率长期处于中高水位,偶尔有应用发布,推送量大时,CPU 甚至会被打满。
以前没感觉到,是因为接入的应用不多,最近几个月应用越接越多,慢慢就达到了告警阈值。
寻找优化点
由于这项目是 Go 写的(不懂 Go 的朋友也没关系,本文重点在算法的优化,不在工具的使用上), 找到哪里耗 CPU 还是挺简单的:打开 pprof 即可,去线上采集一段时间即可。
具体怎么操作可以参考我之前的这篇文章,今天文章中用到的知识和工具,这篇文章都能找到。
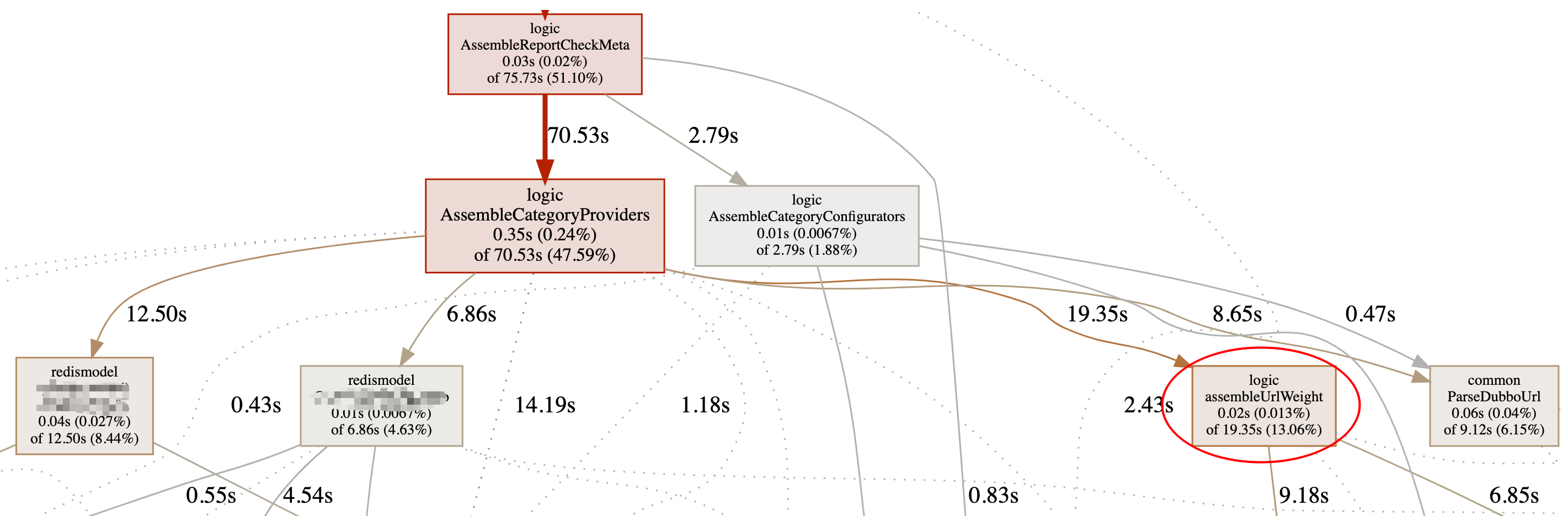
CPU profile 截了部分图,其他的不太重要,可以看到消耗 CPU 多的是 AssembleCategoryProviders方法,与其直接关联的是
- 2个 redis 相关的方法
- 1个叫
assembleUrlWeight的方法
稍微解释下,AssembleCategoryProviders 方法是构造返回 Dubbo provider 的 url,由于会在返回 url 时对其做一些处理(比如调整权重等),会涉及到对这个 Dubbo url 的解析。又由于推拉结合的模式,线上服务使用方越多,这个处理的 QPS 就越大,所以它占用了大部分 CPU 一点也不奇怪。
这两个 redis 操作可能是序列化占用了 CPU,更大头在 assembleUrlWeight,有点琢磨不透。
接下来我们就分析下 assembleUrlWeight 如何优化,因为他占用 CPU 最多,优化效果肯定最好。
下面是 assembleUrlWeight 的伪代码:
func AssembleUrlWeight(rawurl string, lidcWeight int) string {
u, err := url.Parse(rawurl)
if err != nil {
return rawurl
}
values, err := url.ParseQuery(u.RawQuery)
if err != nil {
return rawurl
}
if values.Get("lidc_weight") != "" {
return rawurl
}
endpointWeight := 100
if values.Get("weight") != "" {
endpointWeight, err = strconv.Atoi(values.Get("weight"))
if err != nil {
endpointWeight = 100
}
}
values.Set("weight", strconv.Itoa(lidcWeight*endpointWeight))
u.RawQuery = values.Encode()
return u.String()
}
传参 rawurl 是 Dubbo provider 的url,lidcWeight 是机房权重。根据配置的机房权重,将 url 中的 weight 进行重新计算,实现多机房流量按权重的分配。
这个过程涉及到 url 参数的解析,再进行 weight 的计算,最后再还原为一个 u
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2566
2566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









