









MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”
在windows下实现wordcount
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] words = line.split(" ");
for(String i:words){
context.write(new Text(i),new IntWritable(1));
}
}
}
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable i:values){
sum+=i.get();
}
context.write(key,new IntWritable(sum));
}
}
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
FileInputFormat.setInputPaths(job,new Path("E:\\ppp"));
FileOutputFormat.setOutputPath(job,new Path("D:\\wboutput"));
job.waitForCompletion(true);
}
}
将实现的WordCount打成jar包
1.首先在pox.xml配置文件中添加:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.xlh.mr.Driver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.在Driver里添加
job.setJarByClass(Driver.class);
3.在生命周期栏中选择Package选项
4.完成后就会有target一栏,
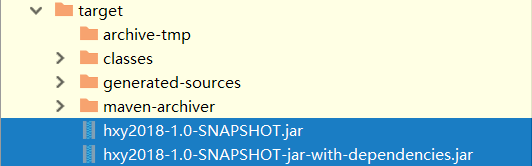
蓝色的第一行是不带有jar包的,第二行是带jar包的
5.开启虚拟机开启hdfs,输入
hadoop jar jar包名 manifest标签下的内容 要用的文件 生成的文件地址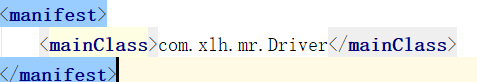
序列化
java的序列化
hadoop MapReduce序列化
1.首先让类实现Writeable接口
2.实现Writeable接口的write,readFields抽象类
3.需要一个空参构造器
4.get,set方法
5.有参构造器
6.toString方法
7.在write方法中写:
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
8.在readFields类中写:
public void readFields(DataInput dataInput) throws IOException {
upFlow=dataInput.readLong();
downFlow=dataInput.readLong();
sumFlow=dataInput.readLong();
}
顺序必须和write相同
全排序
概念:生成的文件只有一个并且全局有序
1.让bin类继承WritableComparable<排序的依据>类
2.实现这个继承类的ComparaTo方法(默认升序排列)
例(想要降序排列):
@Override
public int compareTo(FlowOrder o) {
if(this.sumFlow>o.sumFlow){
return -1;
}
if(this.sumFlow<o.sumFlow){
return 1;
}
return 0;
}
3.在写mapper类的时候,输入参数还是LongWritable,Text但是输出参数变成了FlowBen,Text,
因为排序的时间是在Mapper和Reducer之间有一个shuffer,shuffer是依据key来排序的所以要把排序依据放在key上
map方法照常写
4.Reducer类reduce方法目的就是将key,和value位置调换
5.driver类不变
分区
1.创建一个类叫HashPartitioner让他继承Partitioner类实现getPartitioner方法
Partitioner的泛型为Mapper阶段的输出类型
原因:因为分区动作是在Mapper上交数据的时候进行的所有。。
2.分区的返回值是数字从0开始
例(手机号按地区分区):
public class FlowOrderPartiti extends Partitioner<FlowOrder,Text>{
@Override
public int getPartition(FlowOrder flowOrder, Text text, int i) {
String sub = text.toString().substring(0, 3);
if ("136".equals(sub)){
return 0;
}
if ("137".equals(sub)){
return 1;
}
if ("138".equals(sub)){
return 2;
}
return 3;
}
}
3.在Driver类中要声明一下刚刚写的分区类,因为如果不声明用的还是原来的分区方法,还要声明有多少个ReduceTesk,有多少ReduceTesk就有多少文件
例(有4个文件,分区文件为FlowOrderPartiti):
job.setNumReduceTasks(4);
job.setPartitionerClass(FlowOrderPartiti.class);
Combiner
combiner阶段的任务就是将Mapper阶段的数据进行提前合并,提高Reduce阶段的效率。
combiner阶段和Reducer阶段是一样的都是继承Reduce之后重写reduce方法
之后再Driver里声明一下
job.setCombinerClass(WordCountReduce.class);
分组
1.创建一个GropConparator类继承WirtableConparator接口
2.创建一个无参构造器
public SumCountGropConparator() {
super(Text.class,true);
}
2.实现compare(writableComparable a,writableComparable b)
在这个方法里重写你需要的分组条件(默认所有都一样才是一组)
返回值和分区一样,一样的时候是返回0
3.在Driver类里添加
job.setGroupingComparatorClass(SumCountGropConparator.class);
简述shuffer的流程

这个图就很好的展现了shuffer流程
简述:
shuffer分为两个阶段(mapper,reducer)
mapper:
首先Mapper的输出会读入缓存,默认100mb,当缓存的空间达到80%的时候,会溢写到磁盘当中,在从缓存到磁盘的过程中会有分区和区内排序阶段,有可能还会有Combiner阶段进行提前合并,之后当所有的Mapper阶段的输出数据都读完之后,将一块块的分区进行归并,归并之后进行压缩,写入本地磁盘。
reducer:
每个reducetask去每个maptask的磁盘上取自己分区的数据,将数据读入到内存缓冲区中,如果内存不够也会溢写到磁盘中,最后将数据进行归并排序,最后分组。
OutputFormat
MR可以自定义输出格式
方法:
首先建一个类让其继承FileOutput类(FileOutputFormat类继承的是OutputFormat类)
FileOutput类是(org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;)
将实现FileOutput类中的getRecordWriter抽象方法,返回一个RecordWriter类对象
public RecordWriter getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new baiduRecord(taskAttemptContext);
}
之后创建baiduRecord对象让其继承RecordWriter类,实现其中的writer,close抽象方法,并在构造器中将文件系统输出流建立,在wirter方法中写
public class baiduRecord extends RecordWriter {
FSDataOutputStream fsbaidu = null;
FSDataOutputStream fsother =null;
public baiduRecord(TaskAttemptContext job) throws IOException {
FileSystem fs = FileSystem.get(job.getConfiguration());
fsbaidu = fs.create(new Path("E:\\MR\\baidu.log"));
fsother = fs.create(new Path("E:\\MR\\other.log"));
}
@Override
public void write(Object a, Object b) throws IOException, InterruptedException {
if (a.toString().contains("baidu")){
fsbaidu.write(a.toString().getBytes());
}else{
fsother.write(a.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(fsbaidu);
IOUtils.closeStream(fsother);
}
}
最后在job里加入自定义方法
job.setOutputFormatclass();
inputFormat
在mapreduce中数据输入时默认为
job.setInputFormat(TextInputFormat.class);
其格式默认为key是行号,value是一行的内容
所以map阶段的参数默认为LongWritable,Text
MapReduce也提供了其他形式的InputFormat
1.KeyValueInputFormat 这个形式的InputFormat是默认以第一个\t为标志,\t前的数据作为key
\t后的数据作为value,所以map中的输入参数就为Text,Text。
也可以把标志 \t改成其他的
Configuration configuration = new Configuration();
configuration.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR," ");
Job job = Job.getInstance(configuration);
这是将\t改成空格。
2.NLineInputFormat 这个形式的InputFormat是当一个maptask的工作量太大的时候可以指定每个maptask的工作量将工作量平均,提高效率,其默认的输入方式依然是TextInputFormat的方式
job.setInputFormatClass(NLineInputFormat.class);
NLineInputFormat.setNumLinesPerSplit(job,2);
FileInputFormat切片源码解析

切片与MapTask并行度决定机制
1.MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块
数据切片:数据切片只是逻辑上对输入进行分片,并不会在磁盘上将其分成片进行存储。
切片的大小如何确定?
1.切片的大小默认是128MB,与HDFS的块大小进行对应,因为如果不和HDFS的数据块大小保持一致的话,可能会涉及到块客户端存取的情况。
2.MapTask的数量和切片的数量对应
3.Split切片的时候是对文件进行切片,所有当有两个文件的时候
两个文件进行分别切割。
例:
两个文件一个300MB,一个51MB
则这两文件在进行切片的时候会切成4个切片
源码debug
1.首先判断state是不是define
2.判断是不是使用的新的mapreduce包
3.判断numberReduce是不是0
4.判断是否有分区
5.判断是否连接集群(clister==null)
6.检验输出路径
7.获取配置信息
创建Stag目录
8.获取本机ip地址
9.获取本机名
10.生成jobid
11.生成新的子目录
12.切片
13.设置切片大小

14.将配置文件写入jobfile,job.xml是把所有的配置文件写入一个文件中
15.进入mapper类进入run方法执行setup(context)读切片文件
16.判断是否有keyvalue
17.进入自定义mapper中执行自己写的方法
18,。之后循环
19.进入reducer方法,循环
20.ok
重点
1.首先submait方法
2.建立连接:
connect();
1).创建提交job的代理
new Cluster (getConfiguration ());
判断是本地 yarn还是远程initialize(jobTrackAddr, conf);
3.提交任务
submitter.submitJobInternal (Job.this, cluster)
创建给集群提交数据的Stag路径
JobSubmissionFiles.getStagingDir(cluster, conf);
获取jobid,并创建job路径
JobID jobId = submitClient.getNewJobID();
运算逻辑靠近数据
自定义InputFormat
1.首先定义一个类让其继承FileInputFormat类
2.之后实现FileInputFormat类的抽象方法createRecordReader
3.在此类中要返回一个RecordReader类型的对象
public RecordReader createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
MyRecordReader myRecordReader = new MyRecordReader();
myRecordReader.initialize(inputSplit,taskAttemptContext);
return myRecordReader;
}
4.创建一个类让其继承RecordReader类并实现其中的抽象方法
public class MyRecordReader extends RecordReader<Text,BytesWritable> {
FileSplit split= null;
FileSystem fileSystem =null;
FSDataInputStream open =null;
boolean log=true;
Text k = new Text();
BytesWritable v = new BytesWritable();
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//获得配置文件
Configuration conf = taskAttemptContext.getConfiguration();
//将文件切片类型inputSplit转换成FileSplit
split= (FileSplit) inputSplit;
//创建文件系统以FileSplit来建立
fileSystem = split.getPath().getFileSystem(conf);
//创建输入流
open = fileSystem.open(split.getPath());
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (log){
//获取文件名
String name = split.getPath().getName();
//建立字节数组
byte[] bytes =new byte[(int) split.getLength()];
//将文件放入数组中并输入
IOUtils.readFully(open,bytes,0,bytes.length);
k.set(name);
v.set(bytes,0,bytes.length);
log=false;
return true;
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return k;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return v;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
5.在Driver类中设置InputFormat,OutFormat要用的类
job.setInputFormatClass(MyInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









