







一、项目背景
母婴用品是淘宝的热门购物类目,随着国家鼓励二胎、三胎政策的推进,会进一步促进了母婴类目商品的销量。与此年轻一代父母的育儿观念也发生了较大的变化,因此中国母婴电商市场发展形态也越来越多样化。随之引起各大母婴品牌更加激烈的争夺,越来越多的母婴品牌管窥到行业潜在的商机,纷纷加入母婴电商,行业竞争越来越激烈。本项目会基于“淘宝母婴购物”数据集进行可视化分析,帮助开发者更好地做出数据洞察。
二、项目目标
- 流量分析:年/季度/月/日的商品销量如何?有什么规律
- 类别分析:商品销量按照类目分类有什么规律?哪些类目的商品更有价值?
- 复购率分析:全部母婴商品的当月复购率变化趋势,大类商品复购率趋势
三 、项目完成过程
(一)、数据预处理
1、导入数据
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
df = pd.read_csv("(sample)sam_tianchi_mum_baby_trade_history.csv")
 原数据集中有29971条数据,数据集字段如下
原数据集中有29971条数据,数据集字段如下
| 字段 | 字段说明 |
|---|---|
| user_id | 用户标识 |
| auction_id | 交易ID |
| cat1 | 商品一级类目ID |
| cat_id | 商品二级类目ID |
| buy_amount | 购买数量 |
| day | 订单发生日期 |
2、查看单个订单购买量分布
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 确保buy_mount字段是数值类型
df['buy_mount'] = pd.to_numeric(df['buy_mount'], errors='coerce')
# 删除buy_mount为NaN的行
df = df.dropna(subset=['buy_mount'])
# 计算购买量的分布
buy_mount_distribution = df['buy_mount'].value_counts()
# 创建散点图显示购买量分布
plt.figure(figsize=(10, 6))
sns.scatterplot(x = buy_mount_distribution.index, y = buy_mount_distribution)
plt.xlabel('购买量')
plt.ylabel('订单数量')
plt.title('单个订单购买量分布')
plt.show() 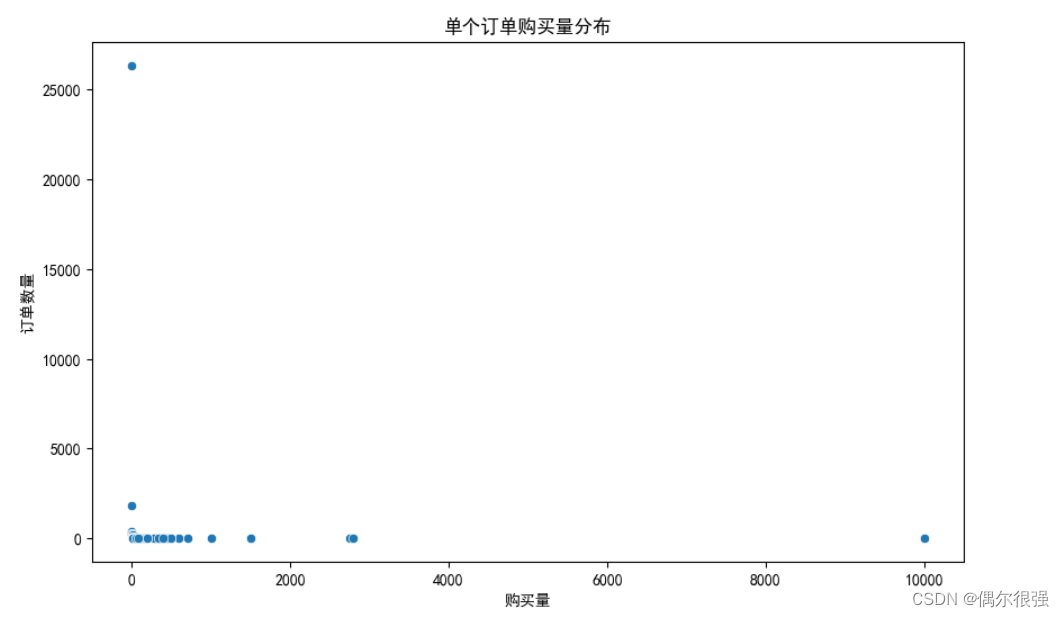
一件订单购买量大多在[1,2000] 这个区间
3、保留buy_amount[1,195]以内的订单
# 保留buy_amount[1,195]以内的订单
df = df[(df['buy_mount'] >= 1) & (df['buy_mount'] <= 195)]4、查看有无缺失值异常值
df.isnull().any()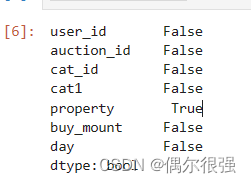
数据集中的property全是数字,需要有对应的字典才能知道对应什么属性,在后续需要删除,所以这个字段的缺失值先不处理
5、查看各字段有多少个值
count_user = df.user_id.nunique()
count_auction = df.auction_id.nunique()
count_category_1 = df.cat1.nunique()
count_category_2 = df.cat_id.nunique()
count_buy_mount = df.buy_mount.sum()
print("用户数", count_user)
print("交易数", count_auction)
print("商品一级类目数:", count_category_1)
print("商品二级类目数:", count_category_2)
print("总销量:", count_buy_mount)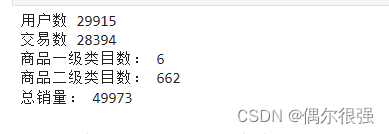
5、 trade中的auction_id未指定是什么属性,我们就将他默认改为item_id
df.rename(columns={"auction_id": "item_id"}, inplace=True)6、property全是数字,需要有对应的字典才能知道对应什么属性,这边先删除
# 删除property列
df.drop("property", axis=1, inplace=True)
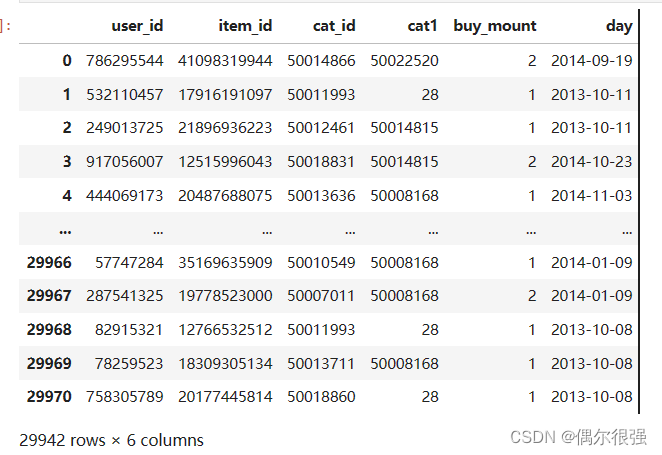
7、day改成日期形式并为表增加对应的字段,年、季、月便于后续分析
df["day"] = pd.to_datetime(df.loc[:,"day"], format="%Y%m%d")
df['year'] = df["day"].dt.year
df['quarter'] =df["day"].dt.quarter
df['month'] = df["day"].dt.month
(二)、流量分析
1、年销量趋势
# 根据年月查看销量趋势
year_stats = df.groupby(by='year')['buy_mount'].sum()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3410
3410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









