





摘要
最近提出的由大型语言模型(LLM)支持的长形式问答(QA)系统显示出了很有前途的能力。然而,对其生成的抽象答案进行归因和验证可能很困难,自动评估其准确性仍然是一个持续的挑战。在这项工作中,我们引入了一种新的QA任务,通过以半提取的方式总结多个不同的来源来回答多个答案的问题。具体来说,半抽取式多源QA(SEMQA)要求模型输出一个全面的答案,同时将事实引用的跨度(从给定的输入源逐字复制)和非事实自由文本连接器混合在一起,将这些跨度粘合成一个连贯的段落。这一设置弥合了基础良好但受约束的提取式QA系统的输出与更流畅但更难完全归因于抽象答案之间的差距。特别是,它为语言模型提供了一种新的模式,利用了其高级语言生成功能,同时还通过易于验证、解释和评估的设计生成了精细的在线归因。为了研究这项任务,我们创建了第一个此类数据集QuoteSum,其中包含对自然问题和生成问题的人工书写的半提取答案,并定义了基于文本的评估指标。通过在各种环境中对几种LLM进行实验,我们发现这项任务具有惊人的挑战性,证明了QuoteSum对开发和研究这种整合能力的重要性。

1 引言
大型语言模型(LLM)最近在NLP任务中表现出了令人印象深刻的能力(Srivastava et al.,2022),尤其是在回答一般问题方面(OpenAI,2023;谷歌等人,2023)。因此,越来越多的用户在寻求信息时与此类模型进行交互。尽管LLM通常会返回高质量和正确的结果,但它们仍然会犯听起来令人信服的错误(例如,依赖过时的信息(Dhingra等人,2022;Schuster等人,2021))。增加引用可以帮助读者验证生成的答案(Bohnet等人,2023;Gao et al.,2023),但可能是不准确的,并增加了可靠性的错误印象(Liu et al.,2022;Yue et al.,2021)。此外,评估完全抽象的长格式QA系统仍然是一个挑战,主要涉及运行其他大型QA模型或昂贵的人工评级。
在这项工作中,我们介绍了半提取多源QA(SEMQA)的任务,用于回答多个答案的问题。具体来说,给定一个问题和一组检索到的段落,目标是生成一个总结的、有充分依据的答案,将逐字提取的事实陈述与自由文本连接符交织在一起。在长时间生成的答案中包含明确提取的跨度提供了多种优势。例如,它很容易支持读者快速轻松的验证——只需要确认源中的上下文。此外,它还简化和标准化了评估过程。不依赖于运行成本高、难以解释且依赖于测量模型性能的基于模型的度量(Deutsch等人,2022),提取的跨度可以很容易地使用标准字符串匹配度量来评估召回率和精度(Rajpurkar等人,2016)。最后,明确引用跨度可以简化LMs昂贵的自回归生成过程,从而实现潜在的效率增益(Mallinson等人,2022;Schuster等人,2022)。
考虑图1中的示例,该示例询问“我将在家过圣诞节”是何时发布的。完全提取的格式可能只返回一组简短的答案,而没有任何上下文化(例如,1943;2014年11月24日;…)。相反在SEMQA中,日期、相关实体名称和事实陈述被提取出来,并粘合在一起,形成一段连贯而有根据的段落。
为了研究SEMQA任务,我们构建了一个问题、相关段落和人工书写的半提取答案的数据集。我们的数据集名为QuoteSum,包括自然多源问题(Kwiatkowski et al.,2019;Min et al.,2020)和生成的多答案问题(Lewis et al.,2021)。我们创建了一个注释管道,要求作者在使用可视化并跟踪复制跨度的工具的同时编译答案。在任务定义中,我们要求作者在确保流畅性的同时,对所有事实陈述使用所提供的引用机制。我们选择关注多源环境,因为我们认为它更明显地受益于这种风格。然而,我们的方法可以很容易地放宽到单一来源和单一答案的问题。通过关注多答案问题,我们还分析了这项任务的主要挑战,要求模型(1)从每个来源提取相关上下文,将简短的答案置于上下文中,以及(2)根据不同答案彼此之间和与问题的关系巩固不同答案。
我们为SEMQA定义了基于文本的度量,并使用QuoteSum对大型QA模型进行微调,并在此任务中评估监督和上下文中的LLM。我们发现LLM仅用几个QuoteSum例子就获得了显著的性能。然而,QuoteSum调优的模型表现最好,这表明我们的数据是有用的。我们还进行了一项用户研究,将SEMQA答案与引用的抽象答案进行了比较(Gao et al.,2023),发现SEMQA回答更全面,更容易被读者手动验证。
我们的主要贡献包括:
•介绍和制定半提取多源质量保证(SEMQA)的任务。
•创建QuoteSum,这是该任务的第一个数据集,包括具有高质量人工书写半提取答案的多答案问题。
•使用基于文本的指标和通过用户研究评估不同的LLM,揭示SEMQA的挑战并促进未来的研究。
2 相关工作
许多大型开放域QA数据集都是用短提取跨度或实体作为目标答案创建的(Berant等人,2013;Joshi等人,2017;Kwiatkowski等人,2019;Rajpurkar等人,20162018)。LLM的最新进展允许将自动QA系统扩展到更具挑战性的设置,如长格式答案(Fan et al.,2019)、多个实体的答案(Amouyal et al.,2023;Zhong et al.,2022)和模糊问题(Min等人,2020;Stelmakh等人,2022)。虽然最新的基于LLM的QA模型侧重于抽象的自由文本闭书或检索然后阅读的设置(Bohnet al.,2023;Lewis等人,2020b),但评估这些模型仍然是一个挑战(Min等人,2023),即使答案有引文(Gao et al.,2021;黄和张,2023,Kamalloo等人,2023.李等人,2023.Liu等人,2023,Malaviya等人,2023:Yue等人,2023-主要涉及昂贵的基于模型的测量(Honovich等人,2022;Rashkin等人,2022)与我们提高生成答案的可信度的动机类似,Potluri等人(2023)提出了一个提取和去文本化管道,该管道从完全提取的长形式答案开始,并对其进行编辑以提高流利性。然而,他们专注于单一来源的问题,不需要多个答案的整合。
3 Semi-Extractive Multi-Source QA
为了正式定义SEMQA设置,我们假设一个输入问题q和一组可能包括问题q的答案的两个或多个段落P。为了简化设置,我们在这里假设段落P∈P已经被模型P(P|q)的一些重新搜索器选择。我们的目标是生成一个答案(q,P)→ a(1)回答q,涵盖基于来自P的信息的所有组成部分和方面,(2)关于P(明确标记提取及其来源)尽可能具有提取性,以及(3)简洁2且流畅。在a的最后两个要求之间有一个自然的权衡。这种平衡是必要的,因为天真地仅最大化(1)和(2)会导致P中的所有段落简单地串联起来。相反,仅最大化的(3)会导致空答案。我们通过寻求确保实体和核心事实陈述的提取性来解决这种紧张关系,而在其他方面则更倾向于流畅。
通过明确引用标记,我们的意思是,每个提取的跨度都应该标记为这样的跨度,并带有一个指示符,指示它是从哪个段落中提取的。段落指示符对于区分段落之间相同的跨度(例如,图1中的“我会回家过圣诞节”)以及将答案中的每个语句与原始支持源联系起来非常重要。为了简洁起见,我们将这种明确标记的半抽取式答案称为引用的答案,尽管答案不需要在引用的跨度周围包括文本引号。我们注意到,有些问题可能无法用这种形式得到充分回答。此外,写出一个充分答案的可行性也取决于给定的段落。然而,我们认为(并证明)许多问题可以用半提取的形式来回答。这种格式提供了以下所述的几个关键优点。
可验证性。与验证转述信息的答案相比,验证直接引用事实陈述的答案通常更容易,即使句子是由支持来源提供的。在后一种情况下,读者需要将生成的文本分解为陈述,审查来源,定位相关信息,并将生成的状态与之进行比较。相反,当逐字逐句地提取事实陈述时,验证生成的文本大大简化了确保这些陈述并没有断章取义。引用跨度的好处在聚合来自多个来源的信息的句子中更为明显。在跨度水平上归因大大简化了验证任务,而不是引用许多来源,从而导致组合增长。在§5.1中,我们从经验上证明了这一假设适用于人类读者。
自动评估。将输出空间压缩为包括提取的跨度的另一个优点是能够使用定义良好的基于字符串的评估度量,根据专家书面参考来检查生成模型的精确性和召回性。从本质上讲,这种表述绕过了评估自由文本答案的持续挑战。目前的解决方案依赖于基于模型的事实一致性度量(Bohnet等人,2023;霍诺维奇等人,2022;Rashkin等人,2022)。然而,用这样的措施很难建立标准化的评估协议。例如,虽然较大的主干评估模型通常性能更好,但出于成本和速度的考虑,有时会使用较小的模型。此外,用多个参考文献评估长期生成的输出暴露了更大的复杂性,因为它可能需要去文本化(Choi et al.,2021)和聚合多个有噪声的分类(Laban et al.,2022)。最后,基于黑盒模型的测量很难在实例层面上进行解释。相比之下,我们引入了支持多个源的文本匹配度量,这些度量更简单、更快、易于理解。生成的文本和属性的准确性。最后,除了简化验证和评估过程外,使用可靠来源的提取跨度来生成事实声明,有助于防止文本本身和文本归因配对中的生成错误和模型模糊。通过强制生成模型明确标记每个提取跨度的边界和来源,可以通过设计提供对正确来源的归因。
3.1 评估指标
如上所述,SEMQA的优点之一是允许纯基于字符串的evalu可解释且计算速度快,并且不需要额外的注释(如消除歧义问题)。我们制定以下措施来评估答案的流利性、准确性和全面性。
流利性。根据ASQA评估集(Stelmakh et al.,2022),在去除任何归因标记后,我们使用ROUGE-L评分(Lin,2004)将生成的答案与参考答案进行比较。我们在所有人类书面参考文献中取得最高分数。
精确性。为了评估生成答案中提取跨度的质量,我们分别计算了每个来源的归一化token-F1分数(Rajpurkar et al.,2016),并计算了各个来源的平均值,得出了参考引用答案中每个来源的最大分数:
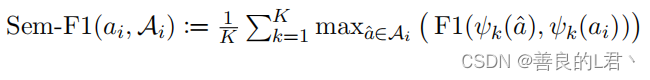
其中Ai是问题qi的一组人类书面参考答案,K是输入源的数量,ψK(a)是一个函数,它只保留在答案a中明确标记为从源K提取的标记。我们使用F1分数来测量跨度的精度(不提取不回答问题的冗余标记)和它们的回忆(提取所有答案和有用的上下文)。
全面性。我们还测量简短答案回忆,以获取生成的引用答案的方面覆盖范围:
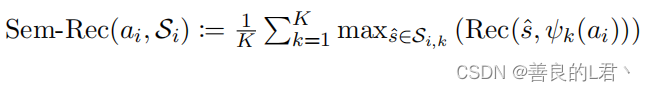
其中Si是一组简短的答案,按来源3,包含在每个人类书面参考文献中,Rec(·,·)是表征级回忆。完美的分数意味着出现在至少一个参考文献中的所有简短答案也在生成的答案中,并归因于正确的来源。
SEMQA综合得分。流利度分数忽略任何归因标记,而精确性仅测量提取(即归因)质量,忽略答案的自由文本部分。因此,我们根据ASQA(Stelmakh et al.,2022)计算它们的几何平均值,以获得反映总体答案质量的单个分数:
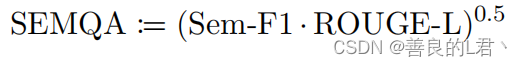
4 QuoteSum数据集
为了研究SEMQA任务,我们创建了一个新的具有(q,P,a)三元组的多答案QA数据集,其中a是人工编写的半提取答案。我们将此数据集称为QuoteSum,因为它包括基于所提供来源的输入问题的引用答案。我们使用方括号和相应源的索引来明确标记提取的跨度。例如,图1中的第一个答案是:歌曲“[1 我会回家过圣诞节]”最初由[1 Bing Crosby]于[1 1943]发布,用于标记从源1中提取的跨度。在本文中,我们将文本标记替换为彩色高亮显示。接下来,在§4.1中,我们描述了基于PAQ(Lewis等人,2021)和NQ(Kwiatkowski等人,2019)数据集的选择(q,P)对的过程。然后,在第4.2节中,我们详细介绍了撰写引用答案的众包任务。最后,我们在§4.3中提供了所有数据集的统计数据,并在§3.1中定义了评估指标。
4.1 收集多答案问题
由于我们专注于多答案问题,我们首先需要收集将提供给作者的问题和候选答案,以产生半提取答案。我们从PAQ数据集(Lewis et al.,2021)中获得机器生成的问题,从NQ的AmbigQA(Min et al.,2020)子集(Kwiatkowski et al.,2019)中获得人工书写的问题。表1给出了所选问题的示例。
Probably-Asked Questions(PAQ)。我们的第一组问题是基于PAQ数据集(Lewis et al.,2021),该数据集收集了6500万个可能被问到的问题,这些问题是从维基百科文章中自动生成的。对于每一篇文章,都使用BERT(Devlin et al.,2019)模型提取可能的答案跨度。然后,使用在NQ(Kwiatkowski et al.,2019)、TriviaQA(Joshi et al.,2017)和SQUAD (Rajpurkar et al., 2016)上训练的BART基础(Lewis et al.,2020a)问题生成模型生成问题。
我们从大型的PAQ集合开始,寻找多答案的问题,这意味着相同的问题是从两个不同的目标答案和段落中独立生成的实例。因此,我们将所有的问题(q、p、s)三组、段落和简短回答合并,得到一个映射q→[(p1、s1),…,(pk,sk)]。
为了避免包含相同答案的多个实例,我们应用了一系列过滤器。4对于每个问题q,我们根据T5-XXL(Raffel等人,2019)QA模型按P(si||)对(pi,si)进行排序,只保留得分至少为0.5的答案。然后,我们运行(pi,si)k i=1,过滤掉(1)维基百科页面的实例;(2)si的长度小于4个单词;(3) si∈pj为j < i;或(4)ϕ(si,sj)=1为j < i。
函数ϕ(x,y)是一个二进制答案相似度函数,如果至少有以下条件之一成立,则返回1:(1)列文斯坦距离Lev(x,y)≤10;(2)基于单词的交叉-联合IoU(x,y)> 0.75;或(3)语义答案相似度分类器BEM(x,y)> 0.5(Bulian et al.,2022)。第一个术语可用于识别相同名称的不同拼写(例如,席琳和席琳)。第二个术语有助于查找按不同顺序排列的列表。最后一个基于bem的语义术语捕获了其他更微妙的重复。
我们还发现,一些稍微不同的问题在意义上是相似的。为了自动合并相似的问题,我们用TF-IDF对它们进行向量化,并对余弦相似度大于0.9的问题进行合并。在合并实例时,我们重复上述相同的答案过滤过程,并通过相同的T5 QA模型保持问题对答案获得更高的平均分数。
这个过程产生了大约170K个问题,每个问题至少有两段回答。起初,这些问题在类型(例如,许多什么问题和谁问题)和答案的数量上高度不平衡。因此,我们按问题划分数据,从什么、谁、哪里、何时、什么、如何、哪个、为什么开始,包括代表或“其他”。我们还根据答案的数量进行划分。然后,我们在选择引用和求值的实例时进行平衡随机抽样。
Natural Questions (NQ)。我们还基于NQ数据集收集了人类编写的问题(克维亚特科夫斯基等人,2019年)。由于我们对多答案问题感兴趣,我们使用Min等人(2020)确定的问题子集作为多答案,以及它们注释的简短答案来消除歧义问题。我们还收集了包含pi的维基百科段落。我们注意到,一些消除歧义的问题q‘i可能会有点微妙。为了收集直接回答原始问题q的段落,我们根据T5-XXL四轴训练模型过滤掉问题q的)对,其中P(si | q,pi)< 0.5。
由于对同一问题的一些简短的回答来自于同一个段落,所以我们删除了与另一个段落的单词交叉比大于0.4的段落。最后,我们只保留至少有两个不同答案的问题。与PAQ集类似,我们看到了问题类型的不平衡(有许多由谁和何时提出问题)。再次,我们平衡了跨问题类型和答案数量的抽样,以分散在引号中包含的例子。
4.2 撰写引述的答案
我们现在详细介绍我们的注释任务,为我们收集的问题和段落(q,P)创建人类书写的半提取答案。我们为作者构建了一个网络界面,提供一个问题和一系列段落(见图a.1)。作者可以从输入的段落中选择跨度,并将其复制到答案文本框中。这些复制的跨度被合并以匹配相应的输入源,以帮助编写者跟踪覆盖的源。作者还可以使用自由文本连接提取的跨度并完成答案。提交的答案包括我们的特殊标记,用于指示哪些跨度被复制,以及它们的原始段落。
作者被要求创建一个简洁的摘要来回答问题,同时尽可能从来源复制信息跨度,并使用带有各种连接器的自由文本。他们被告知要尽可能多地报道信息,只要这些信息与给定的问题直接相关。详见附录A。
我们只向作者提供问题和匹配的段落,没有透露任何简短的回答跨度。我们选择这样做是为了避免让作者遵循在抓取过程中可能包含的任何嘈杂的答案。因此,如果作者发现有些段落不相关,他们可以选择不使用所有的输入段落。我们将这个选择过程视为任务的一部分,并将所有输入段落保留在数据集中,真实地模拟提供给答案生成模型的略显嘈杂的检索输出。
4.3 数据集统计
QuoteSum总共包含了4,009个对1,376个独特问题的半提取答案(984个来自PAQ,392个来自NQ)。如4.1中所述,我们通过问题抽样来平衡数据,以增加多样性。图2提供了问题的类型和输入通道数量的统计信息。我们将数据分别以60%、7%、33%的比例进行训练、验证和测试集的分割。我们确保测试集答案所基于的维基百科页面集与训练集和验证集不相交。
5 实验评价
如下文所述,我们研究了微调LMs和少镜头LLM的性能。我们遵循§3.1中描述的评估指标,还进行了§5.1中详细说明的用户研究。
微调模型。我们在QuoteSum训练集上微调不同尺寸的T5模型(Raffel等人,2019)。我们还对FLAN指令调谐的T5模型进行了微调(Wei et al.,2022)。有关更多详细信息,请参阅Ap pendix C。
上下文学习。我们评估了少量PaLM2的变异(谷歌等人,2023年)。我们根据句子t5(Nietal.,2022)嵌入余弦相似度(QSum)中检索最相似的问题,构建一个动态提示,为每个测试问题qi收集例子。我们还使用ALCE(Gao et al.,2023)提示进行了实验,该提示使用完全抽象的在线引用答案(例如,[1]引用源1),并使用Qsum-S提示将QSum例子转换为句子级引用。有关详细信息和示例提示,请参见附录C。
5.1 结果和分析
表2总结了微调模型和情境学习者的结果。微调模型通常在生成引用答案方面表现得更好,因为它们的大小增加了,无论是在短答案覆盖率(Sem-Rec)方面,还是在流畅性(Rouge-L)和提取跨度的精确性(Sem-F1)方面。此外,Flan-T5型号系列明显优于最初的T5,这可能是因为他们所训练的一组指令跟随任务可能能够更好地适应新的输出格式。例如,Flan-T5基础与T5 XL的分数相匹配,T5 XL有大约×13个以上的参数。
少数镜头学习者仅用几个例子就获得了相对较高的性能,证明了他们的样本效率。然而,它们仍然缺乏经过微调的模型,这表明了我们引用的摘要对训练模型生成综合引用答案的价值。
解释基于字符串的度量。我们的矩阵可以帮助理解不同模型的优势和劣势。例如,5热点模型获得了相当高的Sem-Rec分数,PaLM2-Unicron获得了高达88.87的分数,这意味着答案成功地涵盖了问题的多个方面。较低的Sem-F1分数表明,该模型可以更精确地仅提取用于回答问题的相关跨度。此外,将少镜头模型与T5大镜头模型进行比较,我们发现Rouge-L的得分是可比的,而T5模型的Sem-F1得分要高得多。这表明,少镜头模型与T5模型的流畅度相匹配,但没有将所有提取的跨度标记为引号。
这一点在表4中通过PaLM2 Bison 4shot的测试答案进行了证明。引用的答案全面地提取了给定段落中的所有简短答案,同时也有助于将每个选项置于上下文中。虽然提取的跨度为支撑通道提供了有用的属性,但可以提高输出的准确性。例如,“苏珊·伊根”可以被删除,而自由文本中给出的每个节目的年份应该从相应的段落中引用,就像在人类书面参考中一样。
与自动评估相比。为了进行比较,我们还报告了ASQA基于模型的评估指标(Stelmakh等人,2022)。消歧-F1度量要求对消歧问题列表和生成的长答案运行提取的RoBERTa大型(Liu et al.,2019)QA模型,并将每个预测的答案跨度与黄金短答案进行比较。由于我们没有针对PAQ示例的歧义问题,因此我们只评估测试集中源自AmbigQA的部分。如表3所示,我们基于Sem-F1文本的测量对所检查的模型进行了与消除歧义-F1相同的排序,而不依赖于任何QA模型或消除歧义问题。
与引用的答案进行比较。另一种归因答案的本土方法是用引文来生成答案文本。我们使用自动度量和人工评级来针对该方法评估SEMQA。为此,我们将其与最近提出的少镜头ALCE方法(Gao et al.,2023)进行了比较,该方法与我们类似,提示LLM提出问题和一组预先检索的段落。我们使用ALCE ASQA轻指令提示5,其中包括4个完全抽象的答案示例,并对输入源进行在线引用。
表3报告了PaLM2的ASQA指标(Stelmakh等人,2022)以及我们的QuoteSum提示和ALCE提示。由于在ALCE中,跨度没有明确引用,即使是从输入段落中复制的,也不能用我们的半提取度量来评分。QuoteSum提示(QSum)在ROUGE-L和Disambig-F1中都会导致更高的分数,这表明除了更好的可解释性之外,我们的半提取方法还提供了更精确的答案。为了更直接地比较这两种方法,我们自动(使用正则表达式函数)转换QuoteSum示例,以删除跨度级别的归因,并添加相应的句子级别引用(QSum-S)。然后,代替ALCE 4示例,我们通过问题相似性从训练集中动态检索示例(如QSum中)。虽然比ALCE提示有所改进,但转换后的格式(QSum-S)的得分仍然低于半提取格式(QSum),这表明了显式提取跨度的好处。
我们还进行了一项用户研究,要求人工评分者(与创建QuoteSum的人不同)使用5级Likert量表对生成的答案的流利性、全面性、正确性和归因帮助性进行评分(详见Ap pendix B)。我们比较了由SEMQA或ALCE示例提示的PaLM2 Bison 4热点的生成答案,以及QuoteSum的SEMQA人工书面答案。如图3所示,这两种模型的评分都很高,但仍低于人类表现。SEMQA模型在流利性方面的得分略低于ALCE,这表明在“粘合”方面存在挑战,所提取的跨度是连贯的。然而,人类书面参考文献获得了近乎完美的流利度分数,展示了半提取式流利答案的潜力。
SEMQA模型在综合性、正确性和归因帮助性方面表现更好。这支持了我们的假设,即半提取生成可以减少幻觉,而跨度级别的归因可以帮助读者验证生成的文本。
SEMQA手动验证更容易。我们还测量了每个示例的评级时间。由于SEMQA答案通常比ALCE答案长,我们通过每个答案中的单词数量(不包括任何归因标记)进行归一化,以计算每个单词的平均秒数。如图4所示,评级生成的SEMQA和swers比评级ALCE抽象答案快两倍多。这表明,除了更高质量的答案(根据ratings)外,带有明确标记引号的SEMQA答案也更容易被读者评估和验证。
6 结论
我们介绍了半提取多源QA(SEMQA)的任务,以及一个新的综合数据集,该数据集包含基于文本的评估度量的人工编写的SEMQA示例(QuoteSum)。我们的实验和分析揭示了SEMQA的好处,它使LLM能够生成有根据的答案,这些答案可以根据外部来源快速验证,并且易于根据参考文献进行解释和评估,从而避免了对基于模型的测量的依赖。我们希望SEMQA和发布的数据将促进围绕可靠QA提高LLM能力的进一步研究。
局限性
我们的研究范围仅限于英语问答,以及作为支持来源的英语维基百科文章。虽然我们应用了多样化的平衡抽样来从较大的NQ和PAQ集合中选择多个答案问题,发布了我们的过滤和合并功能,但我们检查的问题的范围仍然局限于这些集合中包含的问题。此外,正如我们在整篇论文中所讨论的,我们的目的并不是暗示我们的SEMQA方法适用于所有类型的问题和答案。相反,我们认为它适用于许多多答案问题,并且在适当遵循时提供了许多好处。
我们还澄清了,虽然半提取格式可能会增加与支持归因来源的一致性,但它并不能防止模型幻觉,如不正确的引用或其他断章取义的问题(Zhang et al.,2023)。
我们发现,半提取式答案更容易根据归因来源进行手动验证。最后,需要注意的是,生成答案的正确性也取决于所提供来源的准确性,其中可能包括不正确或误导性信息。在这里,为了简化设置并保持重点,我们假设源是由一些可能有噪声的检索器提供的。我们将检索部分的进一步研究留给未来的研究。
更广泛的影响
我们公开发布了为这项研究收集的数据集,包括人类书写的半提取答案。我们希望这将有助于未来对启用半提取式QA系统的研究,进一步探索其权衡,并确定此类模型的理想问题覆盖范围。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









