









一. 为什么要使用梯度下降
不管是监督还是非监督,每个模型都有自己的损失函数,损失函数中包含了若干模型参数,比如多元线性回归模型中的损失函数很复杂,无法得到模型参数的估计值及求解公式,因此需要一种大多数函数都适用的方法,即梯度下降法。
二. 推导梯度下降公式
1.已知我们的MSE损失函数公式如下:
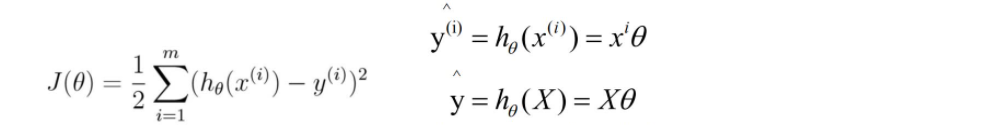
下面推导公式中θj是某个特征维度Xj的权值系数,也可以写成 Wj,在损失函数mse中,x和y是已知的θ是未知的,此时θ不是一个变量而是一堆变量,所以我们只能对含有一堆变量中的mse函数中的一个变量求导,即偏导。下面是对θj求导。

上述解析:
设:x 的导数就是 2x,根据链式求导法则,我们可以推出第一步。然后是多元线性回归,
所以 hθ (x) 就是 w.T * x 也是 x0w0 + x1w1 + …+ xn*wn 到这里我们是对θj 来求偏导,那么和 Wj 没有关系的可以忽略不计,所以只剩下 Xj。
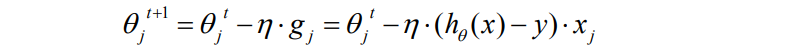
三. 代码实现梯度下降线性回归模型
1.需求:
1. 全量梯度下降,随机梯度下降,批量梯度下降
2.动态调整学习率
2.全量梯度下降
import numpy as np
# 设置超参数
lr = 0.0001
n_epoch = 10000
t0,t1 = 5, 500
def learning_rate(t):
return t0/(t + t1)
#1. 创建数据集
X = np.random.rand(100,1)
X_b = np.c_[ np.ones((100,1)), X]
y = 4 + 3 * X + np.random.randn(100,1)
#2. 初始化θ,w0,w1,..wn
theta = np.random.randn(2,1)
#3.求梯度 g = (hθ(x) -y ) * X , y_hat = hθ(x) = θX
for epoch in range(n_epoch):
gradients = T_b.T.dot(X_b.dot(theta) -y)
lr = learning_rate(epoch)
theta = theta - lr * gradients
print(theta)
2.随机梯度下降
import numpy as np
# 设置超参数
lr = 0.0001
n_epoch = 10000
t0,t1 = 5, 500
m=100 # 样本数量
def learning_rate(t):
return t0/(t + t1)
# 创建数据集
X = np.random.rand(100,1)
y = 5 + 4 * x + np.random.randn(100,1)
#创建恒为1的截距项
X_b = np.c_[np.ones((100,1)),X]
# 初始化随机θ
theta = np.random.randn(2,1)
# 计算梯度
for epoch in range(n_epoch):
# 所有数据都能取到
# 打乱数据
arr = np.arange(len(X_b))
np.random.shuffle(arr)
X_b = X_b[arr]
y = y[arr]
for i in range(m):
xi = X_b[i:i+1]
yi = y[i:i+1]
gradients = xi.T.dot(xi.dot(theta) -y)
lr = learning_rate(epoch * m + i)
theta = theta - lr * graients
print(theta)
3.批量梯度下降
import numpy as np
# 设置超参数
lr = 0.0001
n_epoch = 10000
t0,t1 = 5, 500
m=100
bath_size= 10
num_bath_size = int (m/bath_size)
def learning_rate(t):
return t0/(t + t2)
# 构建数据集
X = np.random.rand(100,1)
y = 5 + 4 * X + np.random.randn(100,1)
X_b = np.c_[ np.ones((100,1)), X]
# 初始化θ
theta = np.random.randn(2,1)
# 求梯度
for epoch in range(n_epoch):
arr = np.arange(len(X_b))
np.random.shuffle()
X_b = X_b[arr]
y = y[arr]
for batch in range(mun_bath_size):
grandients = X_b.T.dot(X_b.dot(theta) -y)
lr = learning_rate(epoch * mun_bath_size + batch)
theta = theta - lr * grandients
print(theta)

















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











