







区别
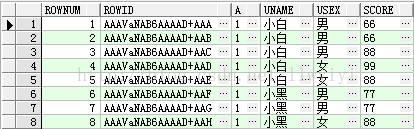
rownum和rowid都是伪列
rownum是根据sql查询出的结果给每行分配一个编号
rowid是物理结构上的,在每条记录insert到数据库中时,都会有一个唯一的物理记录
rownum
先看结果:
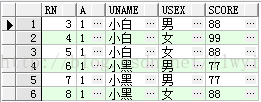
①查找前三行的数据
Select *from test where rownum<=3;

②查找三行以后的数据
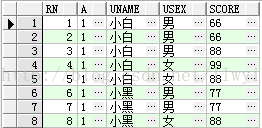
错误:Select *from test where rownum>=3;返回为空

正解:Select *from(select rownum rn,t.* from test t)t where t.rn>=3;
解析:
第①种,
第一行数据rownum=1,然后发现rownum<=3满足则往下走
第二行数据rownum=2,满足继续,
第三行数据rownum=3,满足继续,
第四行数据rownum=4,不满足rownum<=3,然后将此行删除,继续
第五行数据rownum=4,关键在这里rownum还等于4,意思只要rownum不满足条件,它的值就不变,不满足rownum<=3,删除此行,继续
第六行一样,一直到了最后一行。
当然这里的删除是针对返回结果集来说的,并不是把表中的数据删除
第②种:
第一行数据rownum=1,不满足删除此行,继续
第二行数据依旧rownum=1,一直到最后一行,返回结果集为空
所以要借助子查询,可以这样理解子查询的查询流程要依赖上面所述的方法,然后得到查询结果附上新的rownum
在这个子查询得到的结果表中进行过滤查询,也就是主查询,而主查询就不需要再次依赖上面的方法进行,而是直接把rownum当成字段进行过滤where t.rn>=3,没有附新的rownum
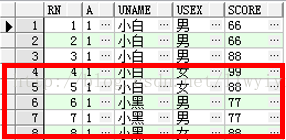
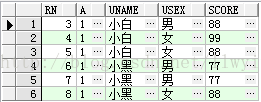
所以Select *from(select rownum rn,t.* from test t)t where t.rn>=3;的结果是
③经典应用,分页查询
子查询用rownum查出所有的记录,然后主查询where借助子查询的rownum过滤出需要的数据(也就是第21-30条的记录,每页10条),即让rn>=21and rn<=30(主查询)
例如:
select *from (select rownum rn, s.* from student s) where rn>=21 and rn<=30
为什么这里必须用子查询
不用子查询,select xxx fromxxx where rownum>=3 and rownum<=7 查询结果是空。
个人理解,擦亮眼睛,有错必究:
因为此时遍历结果集中的第一行,rownum为1,不满足rownum>=3,删除结果集中的第一行,此时rownum不动,刚才的第二行数据上移,此时rownum还是1,只不过后面的数据发生了变化。如此重复,每次都删一行,直到最后一行,返回空结果集。
如果满足的话,就不删除本行数据,而rownum向下移动遍历下一行且rownum值要加1
举一反三:
1.Select *from test where rownum!=4;
和①效果一样
2.select rownum rn,t.* from test t wheret.score>=70

如上述所示,这里的rownum是对得到的结果集重新进行了编排
row_number () over (order by xxx)
和rownum类似只不过是多了个排序的功能,order by默认升序
按照分数排序后取出前三行的数据,这里用主查询是得不到结果的,因为如果写成这样
select uname,usex,score, row_number () over(order by score) rn from test where rn<=3;
是不能执行的,因为rn是一个聚合函数(和rownum最大的区别),where后不能用聚合函数
所以要借助子查询:
select uname,usex,score,rn from (selectt.*,row_number () over (order by score) rnfromtest t) where rn<=3;
Rowid
传统的方法:
1. 创建一个临时表用distinct把原表重复的数据过滤出去
2. 用truncate清空原表
3. 把临时表的数据重新填充到原表
但表数据是亿级的,这种方法效率就很低了
create table test_tmp as select distinct* from test;
truncatetable test;
insertinto test select * from test_tmp;
Rowid方法:
1. 首先子查询用group by把重复的数据分到一组
2. 然后用max或者min找出其中的一行
3. 最后主查询用rowid not in把其他行删除,任务完成
delete from stu where rowid not in (select max(rowid)from stu t group by t.no, t.name, t.sex);















 2451
2451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









