







问题描述
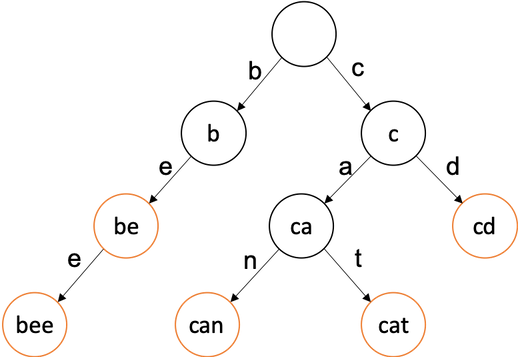
Trie,字典树,又称单词查找树,前缀树,是哈希树的变种。
应用:
- 用于统计,排序和保存大量的字符串(但不仅限于字符串)
- 经常被搜索引擎系统用于文本词频统计,可以快速找到句子中匹配的子串。
优点:
- 利用字符串的公共前缀减少查询时间,最大限度地减少无谓字符串比较,查询效率比哈希树高。
Trie字典树的简单实现查阅文末
安装
本文将使用 Google 编写的 pygtrie ,特性如下:
- 完整的映射实现(类似 dict)
- 支持迭代和删除子trie
- 支持前缀查找、最短前缀查找、最长前缀查找
- 可扩展为任意类型的用户定义键
PrefixSet支持“所有以给定前缀开始的键”逻辑- 可以存储任意值,包括None
pip install pygtrie
初试
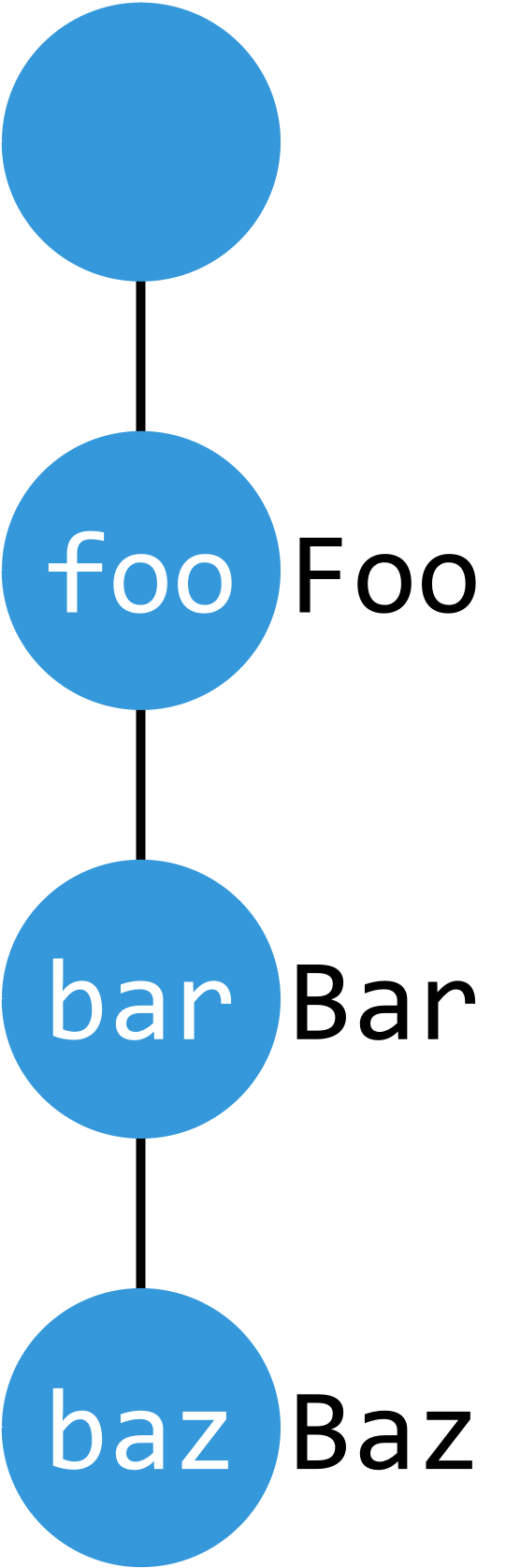
默认分隔符为 /
import pygtrie
t = pygtrie.StringTrie(separator='/')
t['foo'] = 'Foo'
t['foo/bar'] = 'Bar'
t['foo/bar/baz'] = 'Baz'
del t['foo/bar']
print(t.keys()) # ['foo', 'foo/bar/baz']
del t['foo':]
print(t.keys()) # []
取值
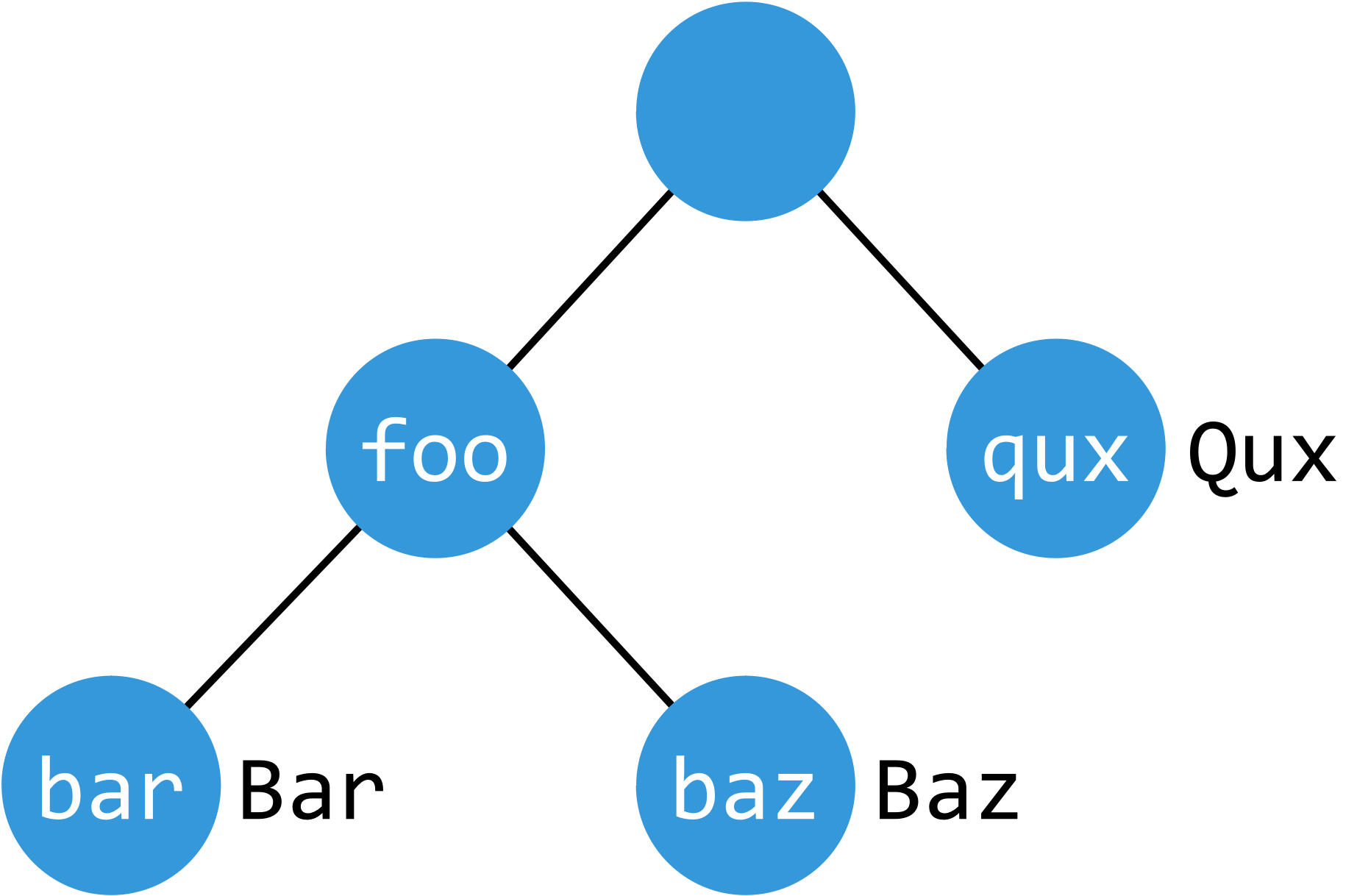
前缀无值取不了
import pygtrie
t = pygtrie.StringTrie()
t['foo/bar'] = 'Bar'
t['foo/baz'] = 'Baz'
t['qux'] = 'Qux'
print(t['foo/bar']) # Bar
print(sorted(t['foo':])) # ['Bar', 'Baz']
# print(t['foo'])
# Traceback (most recent call last):
# pygtrie.ShortKeyError: 'foo'
设值
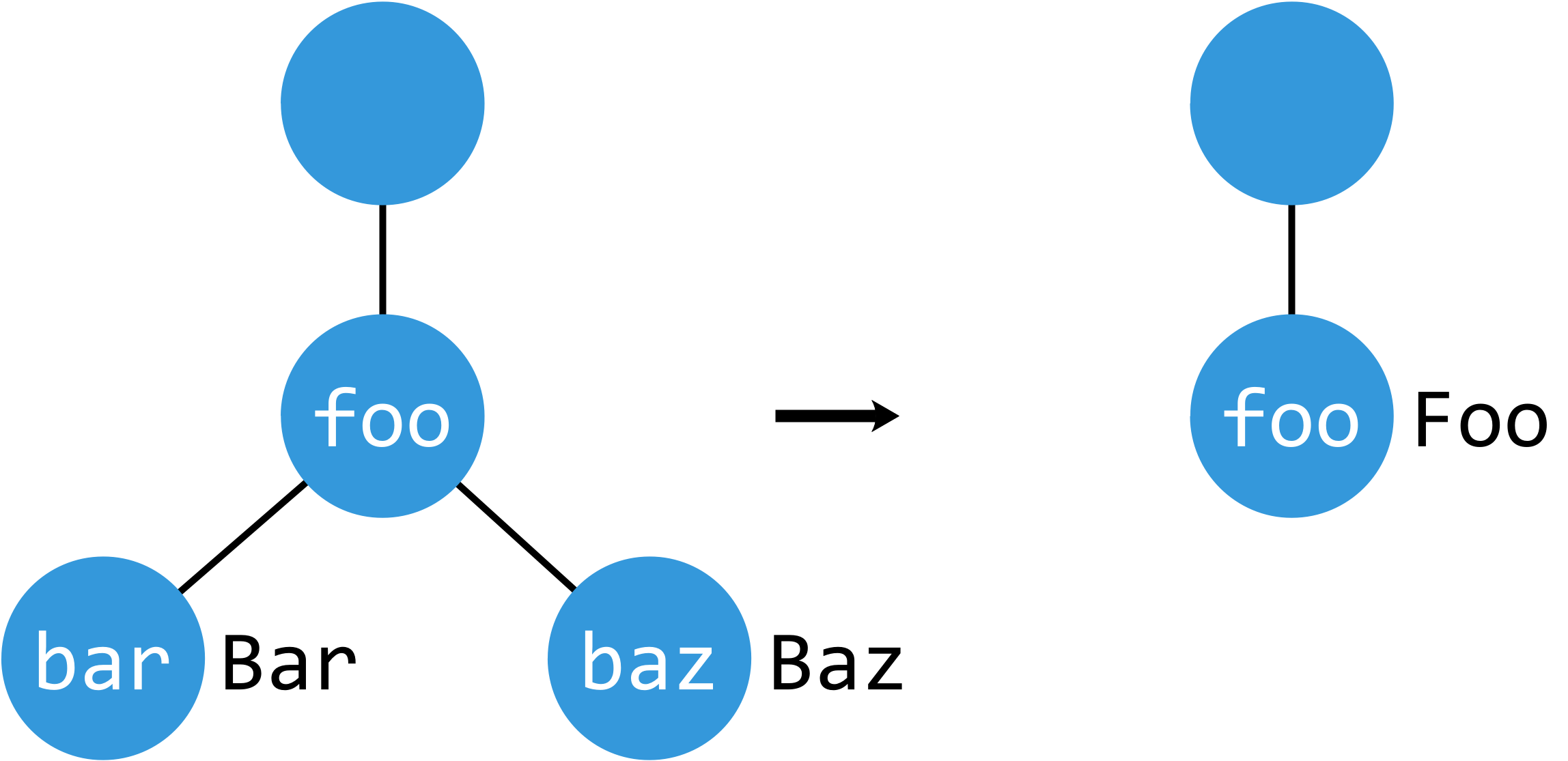
切片将清除条目
import pygtrie
t = pygtrie.StringTrie()
t['foo/bar'] = 'Bar'
t['foo/baz'] = 'Baz'
print(sorted(t.keys()))
# ['foo/bar', 'foo/baz']
t['foo':] = 'Foo'
print(t.keys())
# ['foo']
存在节点或子树
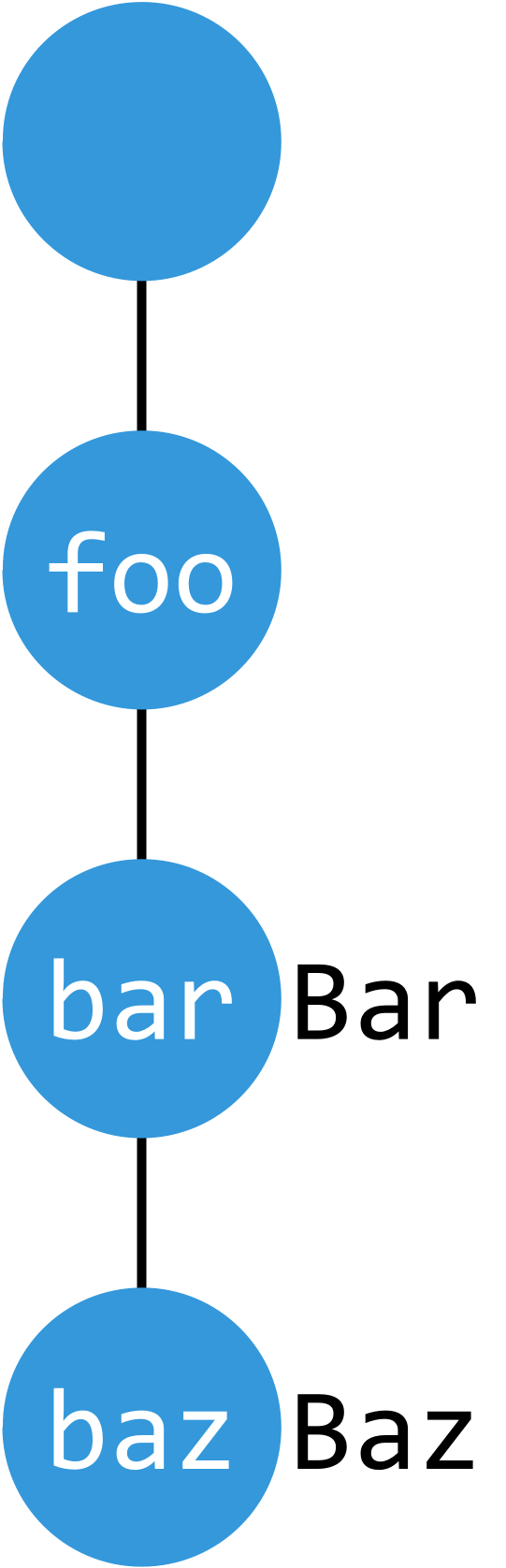
存在节点:has_node(key)
节点有值:HAS_VALUE 或 has_key(key)
节点有子树:HAS_SUBTRIE 或 has_subtrie(key)
import pygtrie
t = pygtrie.StringTrie()
t['foo/bar'] = 'Bar'
t['foo/bar/baz'] = 'Baz'
print(t.has_node('qux') == 0) # 不存在节点qux
print(t.has_node('foo/bar/baz') == pygtrie.Trie.HAS_VALUE) # 节点有值
print(t.has_node('foo') == pygtrie.Trie.HAS_SUBTRIE) # 节点有子树
print(t.has_node('foo/bar') == (pygtrie.Trie.HAS_VALUE | pygtrie.Trie.HAS_SUBTRIE)) # 节点有值或有子树
# True
# True
# True
# True
可直接使用更方便的封装
import pygtrie
t = pygtrie.StringTrie()
t['foo/bar'] = 'Bar'
t['foo/bar/baz'] = 'Baz'
print(t.has_key('qux'), t.has_subtrie('qux')) # False False
print(t.has_key('foo/bar/baz'), t.has_subtrie('foo/bar/baz')) # True False
print(t.has_key('foo'), t.has_subtrie('foo')) # False True
print(t.has_key('foo/bar'), t.has_subtrie('foo/bar')) # True True
遍历
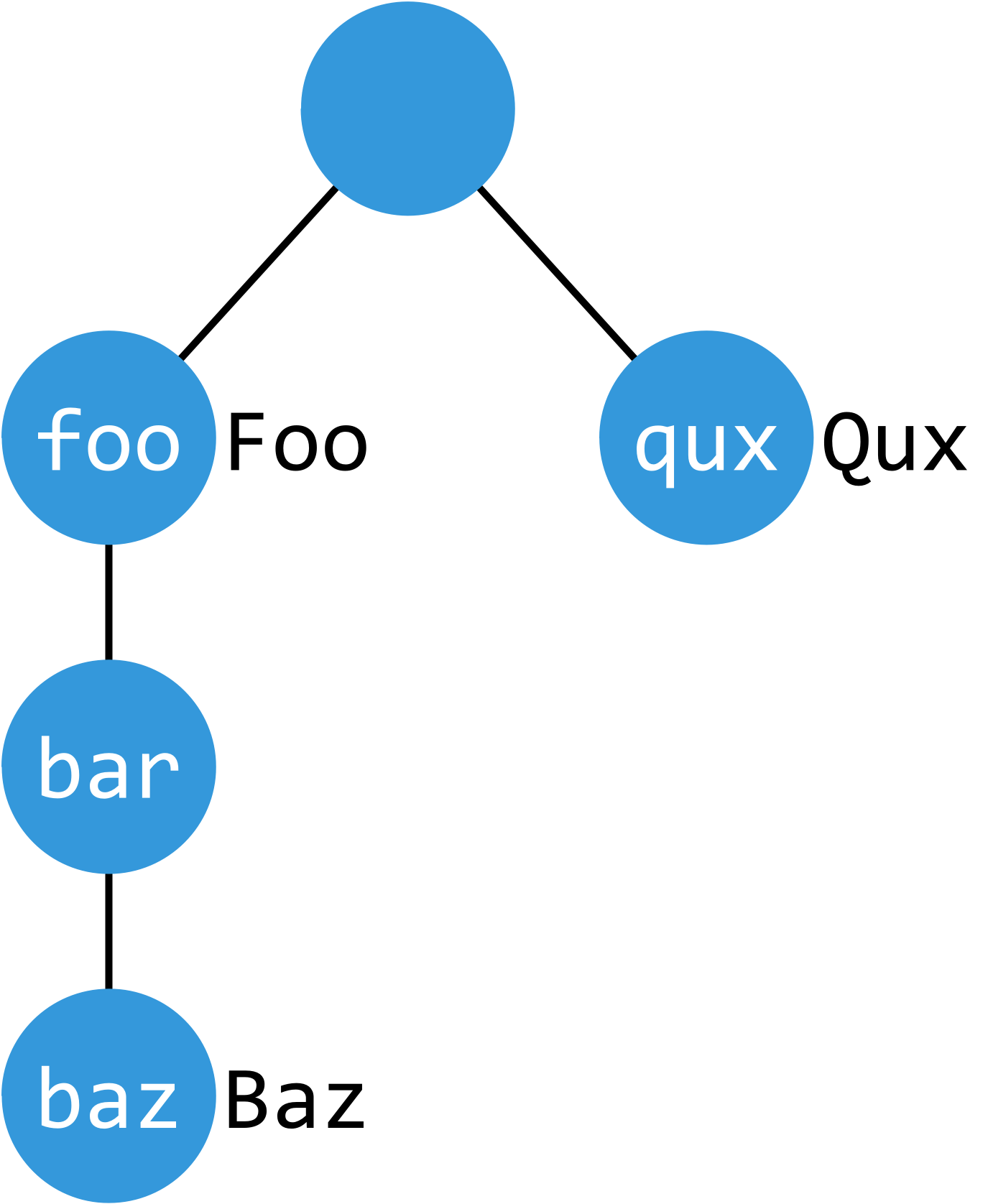
items():只输出有值的节点
iteritems():只输出有值的节点(生成器)
prefix 参数:只生成具有指定前缀的项
shallow 参数:如果一个节点有值,则不遍历子节点
import pygtrie
t = pygtrie.StringTrie()
t['foo'] = 'Foo'
t['foo/bar/baz'] = 'Baz'
t['qux'] = 'Qux'
print(sorted(t.items())) # 只会输出有值的节点
# [('foo', 'Foo'), ('foo/bar/baz', 'Baz'), ('qux', 'Qux')]
print(t.items(prefix='foo')) # 指定前缀
# [('foo', 'Foo'), ('foo/bar/baz', 'Baz')]
print(sorted(t.items(shallow=True)))
# [('foo', 'Foo'), ('qux', 'Qux')]
items 按拓扑顺序生成,兄弟姐妹顺序是不确定的
可以牺牲效率为代价,调用 Trie.enable_sorting() 确保顺序
traverse() 也可以遍历,和 iteritems() 相比有两个优点:
- 基于父节点属性遍历节点列表时,允许完全跳过子节点
- 它直接表示为 trie 结构,易于构造成不同的树
打印当前目录的所有文件,统计HTML文件数,忽略隐藏文件
import os
import pygtrie
t = pygtrie.StringTrie(separator=os.sep)
for root, _, files in os.walk('.'):
for name in files:
t[os.path.join(root, name)] = True
def traverse_callback(path_conv, path, children, is_file=False):
if path and path[-1] != '.' and path[-1][0] == '.':
# 根目录,忽略隐藏文件
return 0
elif is_file:
# 文件
print(path_conv(path))
return int(path[-1].endswith('.html'))
else:
# 目录
return sum(children)
print(t.traverse(traverse_callback))
最长前缀
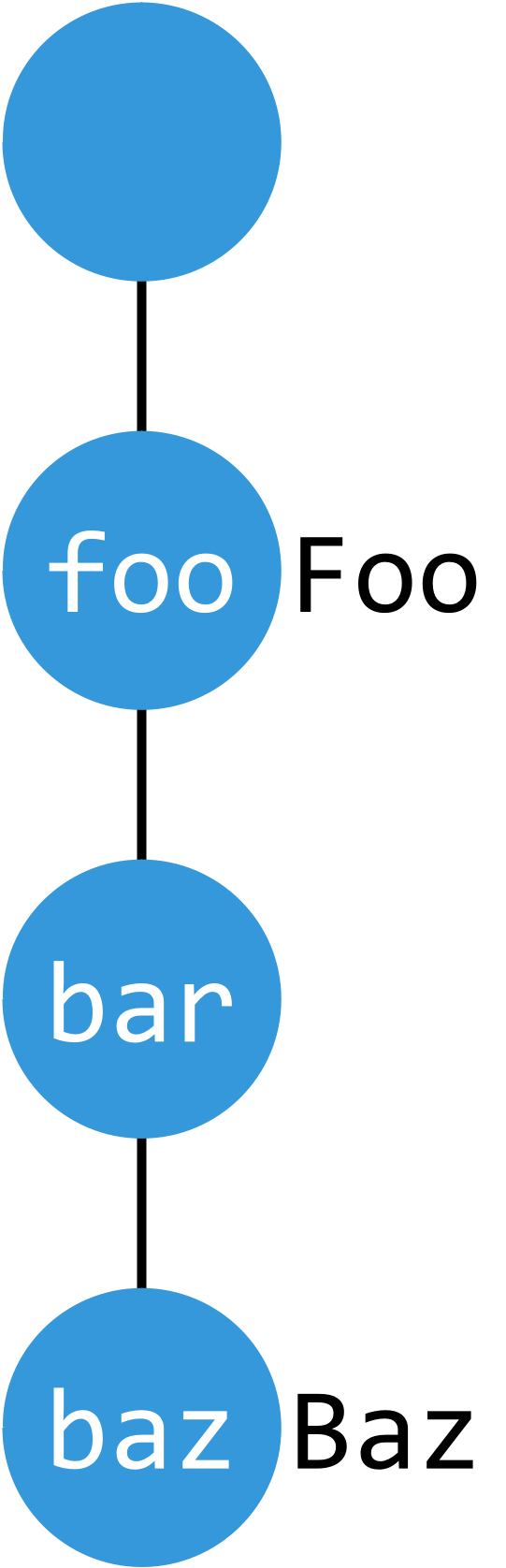
longest_prefix(key)
import pygtrie
t = pygtrie.StringTrie()
t['foo'] = 'Foo'
t['foo/bar/baz'] = 'Baz'
print(t.longest_prefix('foo/bar/baz/qux')) # ('foo/bar/baz': 'Baz')
print(t.longest_prefix('foo/bar/baz/qux').key) # foo/bar/baz
print(t.longest_prefix('foo/bar/baz/qux').value) # Baz
print(t.longest_prefix('does/not/exist')) # (None Step)
print(bool(t.longest_prefix('does/not/exist'))) # False
最短前缀
shortest_prefix(key)
import pygtrie
t = pygtrie.StringTrie()
t['foo'] = 'Foo'
t['foo/bar/baz'] = 'Baz'
print(t.shortest_prefix('foo/bar/baz/qux')) # ('foo': 'Foo')
print(t.shortest_prefix('foo/bar/baz/qux').key) # foo
print(t.shortest_prefix('foo/bar/baz/qux').value) # Foo
print(t.shortest_prefix('does/not/exist')) # (None Step)
print(bool(t.shortest_prefix('does/not/exist'))) # False
所有前缀
prefixes(key)
import pygtrie
t = pygtrie.StringTrie()
t['foo'] = 'Foo'
t['foo/bar/baz'] = 'Baz'
print(list(t.prefixes('foo/bar/baz/qux'))) # [('foo': 'Foo'), ('foo/bar/baz': 'Baz')]
print(list(t.prefixes('does/not/exist'))) # []
单词字典 CharTrie
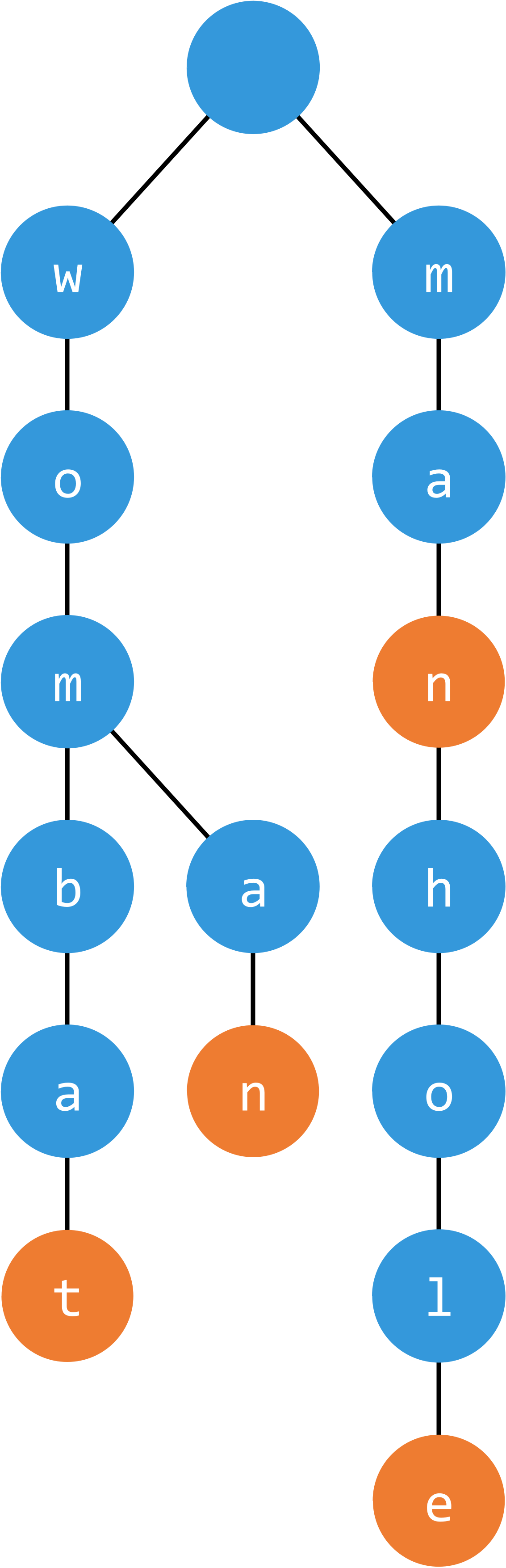
pygtrie.CharTrie 接受字符串作为键,与 pygtrie.Trie 的不同之处在于调用 .keys() 时返回字符串的键
常见例子是自然语言中的单词字典(如图,每个橙色点代表一个单词)
import pygtrie
t = pygtrie.CharTrie()
t['wombat'] = True
t['woman'] = True
t['man'] = True
t['manhole'] = True
print(t) # CharTrie(wombat: True, woman: True, man: True, manhole: True)
print(t.has_subtrie('wo')) # True
print(t.has_key('man')) # True
print(t.has_subtrie('man')) # True
print(t.has_subtrie('manhole')) # False
StringTrie
pygtrie.StringTrie 接受字符串作为分隔符,默认为 /
常见例子是路径映射到一个请求
import pygtrie
def handle_root():
print('root')
def handle_admin():
print('admin')
def handle_admin_images():
print('admin_images')
handlers = pygtrie.StringTrie()
handlers[''] = handle_root
handlers['/admin'] = handle_admin
handlers['/admin/images'] = handle_admin_images
print(handlers.keys())
# ['', '/admin', '/admin/images']
request_path = '/admin/images/foo'
handler = handlers.longest_prefix(request_path).value
handler() # 调用对应的请求处理
# admin_images
简单实现
import collections
class TrieNode:
def __init__(self):
self.children = collections.defaultdict(TrieNode)
self.is_word = False
def __repr__(self):
s = ''
first = True
for k, v in self.children.items():
if first:
if v.is_word:
s += '{} -> {}\n'.format(k, v)
else:
s += '{} -> {}'.format(k, v)
first = False
continue
if v.is_word:
s += '{}\n'.format(k)
else:
s += '{} -> {}'.format(k, v)
return s
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
current = self.root
for letter in word:
current = current.children[letter]
current.is_word = True
def search(self, word):
current = self.root
for letter in word:
current = current.children.get(letter)
if current is None:
return False
return current.is_word
def starts_with(self, prefix):
current = self.root
for letter in prefix:
current = current.children.get(letter)
if current is None:
return False
return True
def __repr__(self):
return repr(self.root).replace('\n\n', '\n').replace('\n\n', '\n')
def find_one(self, word):
'''找到第一个匹配的词
:param word: str
:return: 第一个匹配的词 or None
>>> a = Trie()
>>> a.insert('感冒')
>>> a.find_one('我感冒了好难受怎么办')
'感冒'
'''
for i in range(len(word)):
c = word[i]
node = self.root.children.get(c)
if node:
for j in range(i + 1, len(word)):
_c = word[j]
node = node.children.get(_c)
if node:
if node.is_word:
return word[i:j + 1]
else:
break
return None
if __name__ == '__main__':
a = Trie()
a.insert('张三')
a.insert('张')
a.insert('李四')
a.insert('王五五')
print(a)
print(a)
print(a.find_one('同学有张三、李四'))
# 张 -> 三 ->
# 李 -> 四 ->
# 王 -> 五 -> 五 ->
#
# 张三


















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











