






在 Trino 的查询引擎中,并行机制有如下两点:
多机并行:将查询的逻辑算子树按照一定规则拆分成多个 Fragment,将 Fragment 分发到不同机器上运行
单机并行:将 Fragment 进一步拆分成多个 pipeline,多线程并发执行 pipeline。
这篇文章主要尝试描述单机并行时,trino 如何调度 pipeline 任务的执行。
基本流程概述
下图是 Trino 中对划分后的查询任务调度的大致流程,可以把调度的基本单位认为是PrioritizedSplitRunner
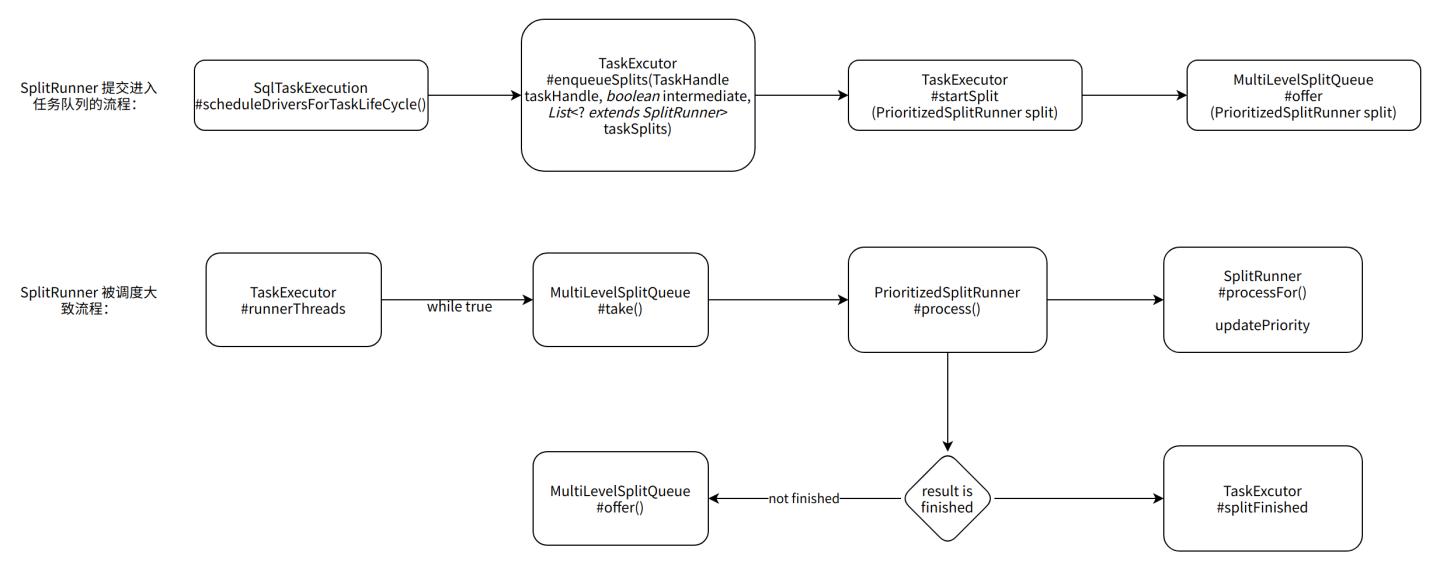
编辑切换为居中
添加图片注释,不超过 140 字(可选)
涉及的主要类为(位于 package io.trino.execution.executor):
SqlTaskExecution:构造方法里有LocalExecutionPlan,入口类
TaskExecutor:持有工作线程资源,内部会维护一个MultilevelSplitQueue,该队列是等待调度的PrioritySplitRunner的队列。
TaskHandle:将多个相关的PrioritizedSplitRunner关联起来(来自同一个SqlTaskExecution),在调度单个PrioritySplitRunner时,其优先级会影响到与其相关的其它PrioritySplitRunner,也会受到与其相关的其它PrioritySplitRunner的影响。
MultiLevelSplitQueue:内置了一个分层级的优先队列,按照level维护了调度的时间和优先级分数。
PrioritizedSplitRunner:为了实现类似操作系统的分片调度的能力,Trino抽象出来一个SplitRunner的接口,在进行调度的时候每次只会调度这个接口的processor一个时间分片,然后重新寻找一个合适的SplitRunner用于下一个分片的执行。
详细说明
TaskExecutor
对应 IoTDB 中的 DriverScheduler
持有工作线程资源,内部会维护一个MultilevelSplitQueue,该队列是等待调度的PrioritySplitRunner的队列。
SqlTaskExecution将其任务提交给TaskExecutor时需要:
创建TaskHandle,并在TaskExecutor中注册该TaskHandle
提交相应的SplitRunner,这些SplitRunner会在TaskExecutor中被封装成PrioritizedSplitRunner,然后加入MultiLevelSplitQueue中等待被调度。(实际上只有intermediateSplits会被立马加入queue中,这里我们只需要考虑intermediateSplits就好)
核心成员变量
核心成员变量如下:
@GuardedBy("this")
private final List<TaskHandle> tasks;
/**
* All splits registered with the task executor.
*/
@GuardedBy("this")
private final Set<PrioritizedSplitRunner> allSplits = new HashSet<>();
/**
* Intermediate splits (i.e. splits that should not be queued).
*/
@GuardedBy("this")
private final Set<PrioritizedSplitRunner> intermediateSplits = new HashSet<>();
/**
* Splits waiting for a runner thread.
*/
private final MultilevelSplitQueue waitingSplits;
/**
* Splits running on a thread.
*/
private final Set<PrioritizedSplitRunner> runningSplits = newConcurrentHashSet();
/**
* Splits blocked by the driver.
*/
private final Map<PrioritizedSplitRunner, Future<Void>> blockedSplits = new ConcurrentHashMap<>();线程工作核心流程
可以参考下图:
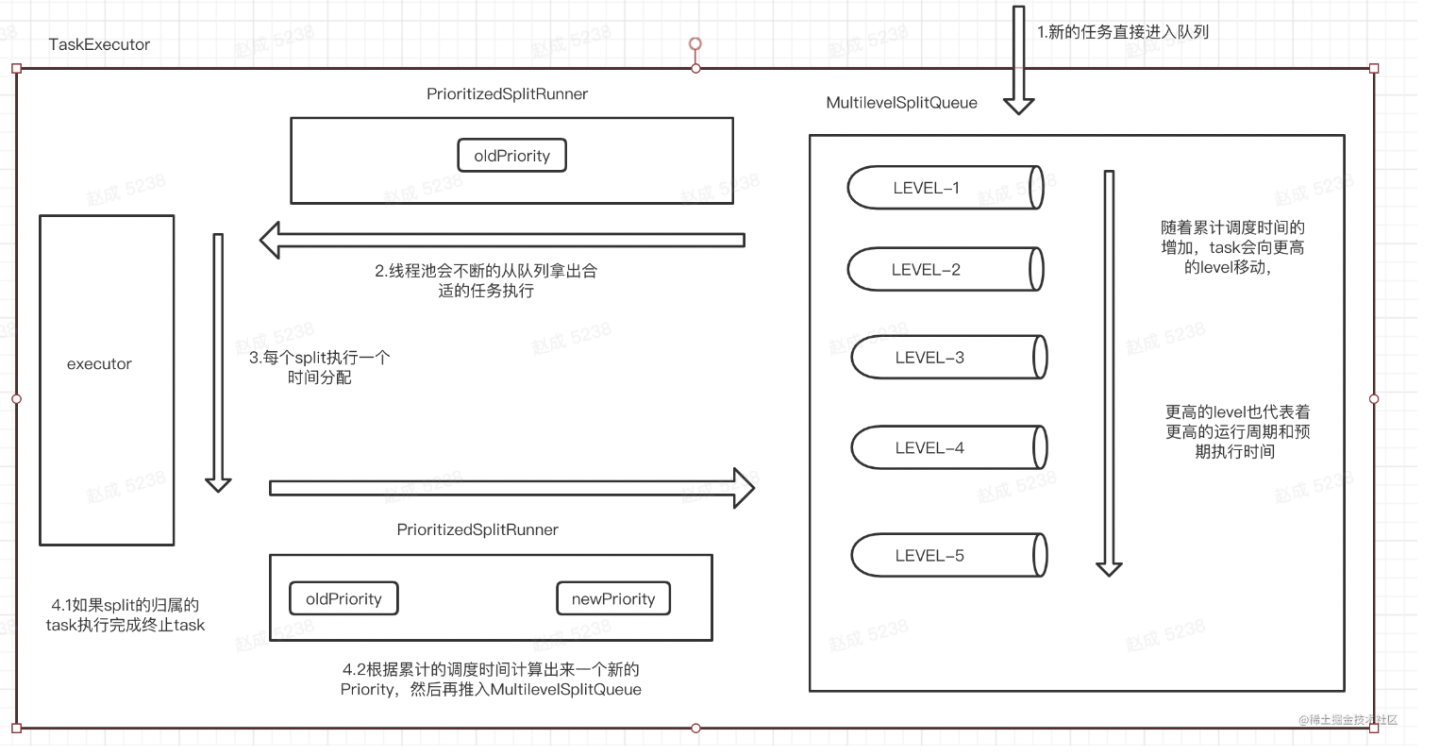
编辑切换为居中
添加图片注释,不超过 140 字(可选)
主要流程:
尝试从waitingSplits(MultiLevelSplitQueue)里面拿到一个PrioritizedSplitRunner:waitingSplits.take()
调用PrioritizedSplitRunner#process,process方法内部会执行一个时间片
如果split已经finish,那么就做相应的finish操作
否则:
如果split没被block住,那么可以直接再推入waitingSplits(MultiLevelSplitQueue)等待被下一次调度,在split被process的时候,优先级信息也被更新了,所以推入MultiLevelSplitQueue的时候可能所在的level会发生变动
如果split被block住,那么就注册回调函数,等block状态解除再放入MultiLevelSplitQueue
run方法的源代码:
@Override
public void run()
{
try (SetThreadName runnerName = new SetThreadName("SplitRunner-%s", runnerId)) {
while (!closed && !Thread.currentThread().isInterrupted()) {
// select next worker
PrioritizedSplitRunner split;
try {
split = waitingSplits.take();
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
return;
}
String threadId = split.getTaskHandle().getTaskId() + "-" + split.getSplitId();
try (SetThreadName splitName = new SetThreadName(threadId)) {
RunningSplitInfo splitInfo = new RunningSplitInfo(ticker.read(), threadId, Thread.currentThread(), split);
runningSplitInfos.add(splitInfo);
runningSplits.add(split);
ListenableFuture<Void> blocked;
try {
blocked = split.process();
}
finally {
runningSplitInfos.remove(splitInfo);
runningSplits.remove(split);
}
if (split.isFinished()) {
log.debug("%s is finished", split.getInfo());
splitFinished(split);
}
else {
if (blocked.isDone()) {
waitingSplits.offer(split);
}
else {
blockedSplits.put(split, blocked);
blocked.addListener(() -> {
blockedSplits.remove(split);
// reset the level priority to prevent previously-blocked splits from starving existing splits
split.resetLevelPriority();
waitingSplits.offer(split);
}, executor);
}
}
}
catch (Throwable t) {
// ignore random errors due to driver thread interruption
if (!split.isDestroyed()) {
if (t instanceof TrinoException) {
TrinoException e = (TrinoException) t;
log.error(t, "Error processing %s: %s: %s", split.getInfo(), e.getErrorCode().getName(), e.getMessage());
}
else {
log.error(t, "Error processing %s", split.getInfo());
}
}
splitFinished(split);
}
}
}
finally {
// unless we have been closed, we need to replace this thread
if (!closed) {
addRunnerThread();
}
}
}TaskHandle
SqlTaskExecution在向TaskExecutor注册时会创建一个TaskHandle,这个TaskHandle会关联该SqlTaskExecution拥有的所有SplitRunner。
TaskHandle也持有一个Priority对象,这个Priority对象可以理解成是其关联的PrioritizedSplitRunner共享的一个cahce。
TaskHandle如何做到调度时统一考虑其关联的所有PrioritizedSplitRunner:
PrioritizedSplitRunner#process方法中,更新Priority的时候会调用TaskHandle#addScheduledNanos
TaskHandle#addScheduledNanos更新TaskHandle的Priority
PrioritizedSplitRunner在从MultiLevelSplitQueue#take中被取出时,会首先判断一下自己的Priority和TaskHandle的Priority是否一致,如果不一致,说明该TaskHandle累计的运行时间已经导致其升级到其它level了,其关联的所有PrioritizedSplitRunner也应该升级,此时将这个出队的PrioritizedSplitRunner重新放入队列,另外选取一个PrioritizedSplitRunner。
PrioritizedSplitRunner
MultilevelSplitQueue的调度单位,与一个TaskHandle关联,维护了一个Priority对象用于计算调度优先级。
核心方法是process,我们只需要关注
12行,processFor消耗一个时间片
18行,进行完一次processFor之后根据调度时间更新优先级
public ListenableFuture<Void> process()
{
try {
long startNanos = ticker.read();
start.compareAndSet(0, startNanos);
lastReady.compareAndSet(0, startNanos);
processCalls.incrementAndGet();
waitNanos.getAndAdd(startNanos - lastReady.get());
CpuTimer timer = new CpuTimer();
ListenableFuture<Void> blocked = split.processFor(SPLIT_RUN_QUANTA);
CpuTimer.CpuDuration elapsed = timer.elapsedTime();
long quantaScheduledNanos = ticker.read() - startNanos;
scheduledNanos.addAndGet(quantaScheduledNanos);
priority.set(taskHandle.addScheduledNanos(quantaScheduledNanos));
lastRun.set(ticker.read());
if (blocked == NOT_BLOCKED) {
unblockedQuantaWallTime.add(elapsed.getWall());
}
else {
blockedQuantaWallTime.add(elapsed.getWall());
}
long quantaCpuNanos = elapsed.getCpu().roundTo(NANOSECONDS);
cpuTimeNanos.addAndGet(quantaCpuNanos);
globalCpuTimeMicros.update(quantaCpuNanos / 1000);
globalScheduledTimeMicros.update(quantaScheduledNanos / 1000);
return blocked;
}
catch (Throwable e) {
finishedFuture.setException(e);
throw e;
}
}MultiLevelSplitQueue
核心成员变量
levelWaitingSplits : 一个size为5的优先队列的2维数组。共5个level,每次take时,通过比对每一level已经消耗的时间,选取一个level,从该level里选取优先级最高的PrioritizedSplitRunner。
levelSchedueTime:一个size为5的调度时间累加器,表示当前level的已用掉的调度时间。PrioritizedSplitRunner在执行完任务的process之后会增加当前level的调度时间。这部分的数据主要用于在poll取PrioritizedSplitRunner数据的时候计算具体从哪个level的队列里面拿。
levelTimeMultiplier:这个字段用于设置不同level之间的cpu时间分配。测试里用的是2,也就是level0-4时间占比为16:8:4:2:1
levelMinPriority:是一个size为5的优先级分数数组,表明当前level的最小的优先级分数,每次从队里成功take出数据之后会更新这个当前level的优先级分数。
LEVEL_THRESHOLD_SECONDS:每个level的阈值,比如LEVEL_THRESHOLD_SECONDS[1] = 1s,也就是说累计运行时间超过1s的任务会被放到level1。
LEVEL_CONTRIBUTION_CAP:一个保护性的值,一次process被计算的上限时间,避免某些任务因为特殊情况被计算了太多值。
static final int[] LEVEL_THRESHOLD_SECONDS = {0, 1, 10, 60, 300};
static final long LEVEL_CONTRIBUTION_CAP = SECONDS.toNanos(30);
@GuardedBy("lock")
private final PriorityQueue<PrioritizedSplitRunner>[] levelWaitingSplits;
private final AtomicLong[] levelScheduledTime;
private final double levelTimeMultiplier;
private final AtomicLong[] levelMinPriority;核心流程
offer
将一个PrioritizedSplitRunner加入对应层级的优先队列,一个PrioritizedSplitRunner初始化的时候默认在level0。
这里遇到空层级的时候,会将空层的运行时间调到预期的运行时间,Trino这样做的原因可能是:
如果不调整,如果这个空的level落后太多,那么之后真的有PrioritizedSplitRunner到达这个level时,这个level的优先级会很高(因为是按照每个层级已经分配到的时间来计算优先级的),可能会导致其它level较长时间得不到调度。
/**
* During periods of time when a level has no waiting splits, it will not accumulate
* scheduled time and will fall behind relative to other levels.
* <p>
* This can cause temporary starvation for other levels when splits do reach the
* previously-empty level.
* <p>
* To prevent this we set the scheduled time for levels which were empty to the expected
* scheduled time.
*/
public void offer(PrioritizedSplitRunner split)
{
checkArgument(split != null, "split is null");
split.setReady();
int level = split.getPriority().getLevel();
lock.lock();
try {
if (levelWaitingSplits[level].isEmpty()) {
// Accesses to levelScheduledTime are not synchronized, so we have a data race
// here - our level time math will be off. However, the staleness is bounded by
// the fact that only running splits that complete during this computation
// can update the level time. Therefore, this is benign.
long level0Time = getLevel0TargetTime();
long levelExpectedTime = (long) (level0Time / Math.pow(levelTimeMultiplier, level));
long delta = levelExpectedTime - levelScheduledTime[level].get();
levelScheduledTime[level].addAndGet(delta);
}
levelWaitingSplits[level].offer(split);
notEmpty.signal();
}
finally {
lock.unlock();
}
}take
pollSplit()方法选取一个合适的PrioritizedSplitRunner
如果result.updateLevelPriority()返回true,说明这个PrioritizedSplitRunner对应的TaskHandle的优先级和PrioritizedSplitRunner的优先级不同,而Trino认为TaskHandle关联的所有PrioritizedSplitRunner的level应当地一致改变,所以将PrioritizedSplitRunner重新放回队列,等待下一次调度。
public PrioritizedSplitRunner take()
throws InterruptedException
{
while (true) {
lock.lockInterruptibly();
try {
PrioritizedSplitRunner result;
while ((result = pollSplit()) == null) {
notEmpty.await();
}
if (result.updateLevelPriority()) {
offer(result);
continue;
}
int selectedLevel = result.getPriority().getLevel();
levelMinPriority[selectedLevel].set(result.getPriority().getLevelPriority());
selectedLevelCounters[selectedLevel].update(1);
return result;
}
finally {
lock.unlock();
}
}
}pollSplit
如何决定选哪个level的优先队列:
level的数量固定是5,Trino假设不同level之间CPU的预期时间分布是确定的,具体实现中使用levelMinPriority的幂次方来决定,比如选择levelMinPriority=2,level0-4的预期CPU时间占比就为16:8:4:2:1
维护了一个levelSchedueTime的数组,标识了各个level已经调度的时间,Trino的选择思路很简单
首先计算出level0的基准时间,注意level0的基准时间是通过getLevel0TargetTime()计算得出的,而不是一个常数
根据levelMinPriority给出的各level时间比例,我们就知道了每一个level的targetScheduledTime
Ratio = targetScheduledTime/实际的调度时间levelScheduledTime[level].get(),ratio结果最大的level就是我们认为最不符合预期比例的level,我们希望给它分配更多的时间,所以选择这个level。
/**
* Trino attempts to give each level a target amount of scheduled time, which is configurable
* using levelTimeMultiplier.
* <p>
* This function selects the level that has the lowest ratio of actual to the target time
* with the objective of minimizing deviation from the target scheduled time. From this level,
* we pick the split with the lowest priority.
*/
@GuardedBy("lock")
private PrioritizedSplitRunner pollSplit()
{
long targetScheduledTime = getLevel0TargetTime();
double worstRatio = 1;
int selectedLevel = -1;
for (int level = 0; level < LEVEL_THRESHOLD_SECONDS.length; level++) {
if (!levelWaitingSplits[level].isEmpty()) {
long levelTime = levelScheduledTime[level].get();
double ratio = levelTime == 0 ? 0 : targetScheduledTime / (1.0 * levelTime);
if (selectedLevel == -1 || ratio > worstRatio) {
worstRatio = ratio;
selectedLevel = level;
}
}
targetScheduledTime /= levelTimeMultiplier;
}
if (selectedLevel == -1) {
return null;
}
PrioritizedSplitRunner result = levelWaitingSplits[selectedLevel].poll();
checkState(result != null, "pollSplit cannot return null");
return result;
}getLevel0TargetTime
pollSplit方法会用到这个基准时间。Trino在计算的时候选择的是所有level经过比例换算之后最大的那个时间。
@GuardedBy("lock")
private long getLevel0TargetTime()
{
long level0TargetTime = levelScheduledTime[0].get();
double currentMultiplier = levelTimeMultiplier;
for (int level = 0; level < LEVEL_THRESHOLD_SECONDS.length; level++) {
currentMultiplier /= levelTimeMultiplier;
long levelTime = levelScheduledTime[level].get();
level0TargetTime = Math.max(level0TargetTime, (long) (levelTime / currentMultiplier));
}
return level0TargetTime;
}updatePriority
PrioritizedSplitRunner#process方法在处理完一次processFor之后,会更新其本身以及TaskHandle的Priority,就会调用到这个updatePriority方法
主体逻辑为:
计算TaskHanlde的累积调度时间是不是要升级到更高的level
逐级更新各level
返回更新后的Priority
/**
* Trino 'charges' the quanta run time to the task <i>and</i> the level it belongs to in
* an effort to maintain the target thread utilization ratios between levels and to
* maintain fairness within a level.
* <p>
* Consider an example split where a read hung for several minutes. This is either a bug
* or a failing dependency. In either case we do not want to charge the task too much,
* and we especially do not want to charge the level too much - i.e. cause other queries
* in this level to starve.
*
* @return the new priority for the task
*/
public Priority updatePriority(Priority oldPriority, long quantaNanos, long scheduledNanos)
{
int oldLevel = oldPriority.getLevel();
int newLevel = computeLevel(scheduledNanos);
long levelContribution = Math.min(quantaNanos, LEVEL_CONTRIBUTION_CAP);
if (oldLevel == newLevel) {
addLevelTime(oldLevel, levelContribution);
return new Priority(oldLevel, oldPriority.getLevelPriority() + quantaNanos);
}
long remainingLevelContribution = levelContribution;
long remainingTaskTime = quantaNanos;
// a task normally slowly accrues scheduled time in a level and then moves to the next, but
// if the split had a particularly long quanta, accrue time to each level as if it had run
// in that level up to the level limit.
for (int currentLevel = oldLevel; currentLevel < newLevel; currentLevel++) {
long timeAccruedToLevel = Math.min(SECONDS.toNanos(LEVEL_THRESHOLD_SECONDS[currentLevel + 1] - LEVEL_THRESHOLD_SECONDS[currentLevel]), remainingLevelContribution);
addLevelTime(currentLevel, timeAccruedToLevel);
remainingLevelContribution -= timeAccruedToLevel;
remainingTaskTime -= timeAccruedToLevel;
}
addLevelTime(newLevel, remainingLevelContribution);
long newLevelMinPriority = getLevelMinPriority(newLevel, scheduledNanos);
return new Priority(newLevel, newLevelMinPriority + remainingTaskTime);
}参考链接
Presto-MultilevelSplitQueue讨论 - 掘金
StarRocks DriverQueue:
https://mp.weixin.qq.com/s/eS5tMjE5O5mBnCmzse0kmQ
https://github.com/StarRocks/starrocks/blob/main/be/src/exec/pipeline/pipeline_driver_queue.cpp















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









