









背景
下推发展过程
trino或者presto早期的数据源主要是hive表(列存),所以计算引擎的下推发力点主要在于project和filter下推,由于parquet等列存主要基于zone map索引(min/max)等来skip数据块(row group),所以filter pushdown的表达式就比较简单,如列的值范围或者值结合:c1 > 100、c1 in (100,200)。
当trino集成了更多数据源之后,比如支持JDBC协议各种DBMS数据库,现有的下推功能就不够用了。这里说一下区别:
- 在hive表数据源,数据源只有存储能力,没有计算能力。所以计算全部放在trino侧。所以只需要存储方面的下推能力即可。
- 而对应JDBC数据源,后端的数据库既有存储能力、又有计算能力。对于trino引擎来说已经无法感知存储的物理结构,所以更需要是计算的下推。
对于JDBC数据源,没有触发计算下推的性能影响:
- 对于trino引擎来说无法感知JDBC数据源表存储的物理结构,那么就无法像hive表一样对JDBC表数据进行input split切片。即TableScan算子的执行并行度只能是1,无法提升并行度来提供表扫描性能。
- 目前几乎99%的数据库客户端driver与server端数据传输是非常低效的。(Don't Hold My Data Hostage: A Case for Client Protocol Redesign, in VLDB, 2017)
- 近10几年来新型数据库都选择复用老型主流数据源的客户端协议,这样的好处可以免费的享受已有driver客户端的生态和工具。被复用最多的三种协议:mysql协议、PostgreSQL协议和redis协议。而这些协议都不是为了传输大数据量而设计的,所以非常低效。
- 低效的原因主要包括下面几个方面:序列化反序列化、行存读写设计、压缩和二进制通信传输协议设计。
总结来说,读jdbc数据源相比直接读hive表的吞吐性能会至少相差一个数量级(比如查询同样大小的tpch表,select * from LINEITEM)。
基于jdbc数据源存在如此低效的TableScan算子的情况,查询的计算下推就显得非常重要,它带来的性能提升可能是一两个数量集。
trino现状
这里再看一下目前trino的计算下推的现状,哪些可以下推,哪些不可以下推。
下推成功的场景
下面是各个可以触发下推的SQL场景,当查询SQL对于当前下推实现机制属于比较“干净”的情况,基本是可以触发下推。
-- 比较Operator如等于、大于、小于、大于等于、小于等于都支持fliter下推,但比较值必须是常量
select * from t1 where c1 = 1;
select * from t1 where c1 > 1;
-- project 下推
select c1, c2 from t1;
-- limit 下推
select * from t1 limit 10;
-- 通用聚合函数支持下推, 如min/max/count/sum
select c1,min(c2) from t1 group by c1;
-- 也支持join下推
select * from t1 join t2 on t1.c1 = t2.c2 where c1 = 1 ;下推失败的场景
下面是下推失败的场景,也就是说查询SQL不是太“干净”的情况。这个的不太“干净”指的是在SQL使用了不支持的Operator、标量函数或者类型转换等。
-- 比较值是非常量,无法fliter下推
select * from t1 where c1 > c2;
-- 算术operator无法fliter下推
select * from t1 where c1 % 10 = 1;
-- scalar函数不支持下推
select * from t1 where c3 like '%trino%';
select * from t1 where date_trunc('day', c4) > TIMESTAMP '2023-06-20 00:00:00';
-- 当c2为非bigint时,aggregate下推失败。
-- 因为“sum(c2)” 会转换为sum( cast(c2 as bigint)), 而scalar函数cast不支持下推。
select c1,sum(c2) from t1 group by c1;作为最重要的fliter下推,从目前支持的表达式场景来看更多是考虑早期的hive数据源(基于列存的min-max过滤),没有太多的去考虑本身有计算能力的DBMS数据源。
下面是一个真实的sql,用trino查询ck和直连查询的性能对比。由于sql使用了函数。导致无法触发计算下推,从而trino需要大量扫描ck数据到trino计算,从而查询性能非常糟糕。
| 场景 | 耗时 |
| ck客户端查询 | 2.2s |
| 使用trino查询ck | 25.62s |
with node_50__StoreOrder__storeCost as (select Store.s_store_name s_store_name,
StoreOrder.cost StoreOrder__cost,
StoreOrder.orderDate StoreOrder__orderDate
from (
select ss_wholesale_cost cost,
d_date orderDate,
ss_store_sk storeId
from ck.tpc_ds.store_sales
) StoreOrder
left join (
select s_store_name s_store_name,
s_store_sk id
from ck.tpc_ds.store
) Store on StoreOrder.storeId = Store.id),
node_50__storeCost__agg as (select date_day,
s_store_name,
sum(aggcol_storeCost) storeCost
from (
select s_store_name,
date_trunc('day', StoreOrder__orderDate) date_day,
(StoreOrder__cost) aggcol_storeCost
from node_50__StoreOrder__storeCost base_model
where (
base_model.StoreOrder__orderDate >= TIMESTAMP '2020-06-01 00:00:00'
and base_model.StoreOrder__orderDate <= TIMESTAMP '2020-07-01 00:00:00'
)
and (StoreOrder__orderDate IS NOT NULL)
) base_query
group by date_day, s_store_name)
select date_day,
s_store_name,
storeCost
from node_50__storeCost__agg
where (
date_day >= TIMESTAMP '2020-06-01 00:00:00'
and date_day <= TIMESTAMP '2020-07-01 23:59:59'
)
order by date_day ASC
limit 100;现有实现
Optional<LimitApplicationResult<TableHandle>> applyLimit(Session session, TableHandle table, long limit);
Optional<ConstraintApplicationResult<TableHandle>> applyFilter(Session session, TableHandle table, Constraint constraint);
Optional<ProjectionApplicationResult<TableHandle>> applyProjection(Session session, TableHandle table, List<ConnectorExpression> projections, Map<String, ColumnHandle> assignments);
Optional<AggregationApplicationResult<TableHandle>> applyAggregation(
Session session,
TableHandle table,
List<AggregateFunction> aggregations,
Map<String, ColumnHandle> assignments,
List<List<ColumnHandle>> groupingSets);
Optional<JoinApplicationResult<TableHandle>> applyJoin(
Session session,
JoinType joinType,
TableHandle left,
TableHandle right,
ConnectorExpression joinCondition,
Map<String, ColumnHandle> leftAssignments,
Map<String, ColumnHandle> rightAssignments,
JoinStatistics statistics);
Optional<TopNApplicationResult<TableHandle>> applyTopN(
Session session,
TableHandle handle,
long topNCount,
List<SortItem> sortItems,
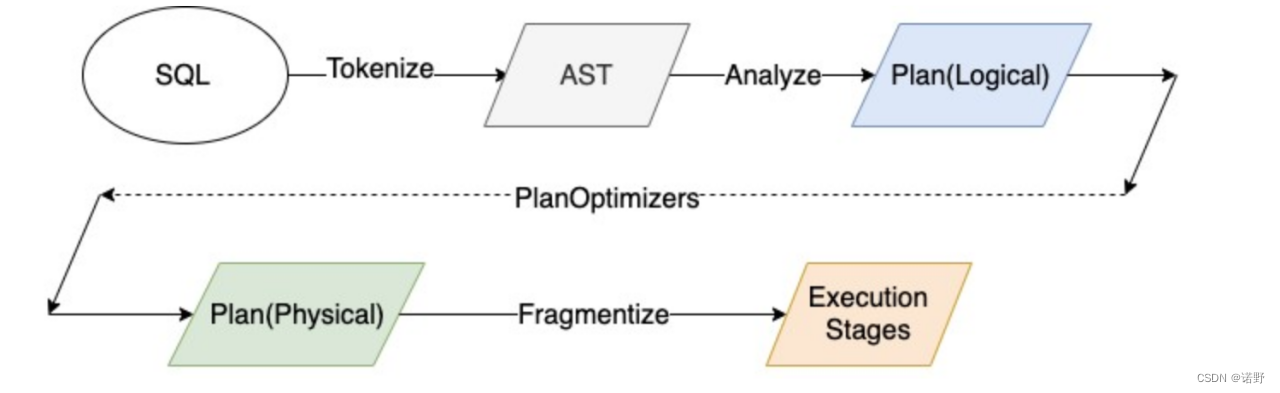
Map<String, ColumnHandle> assignments);trino定义了一个connector API,允许trino查询具有connector实现的任何数据源。现有的connector API提供了各自下推的接口实现。
目前trino针对connector支持下推的各个大方向的场景都有涉及到,比如Projection、Filter、Limit、Aggregation和Join等。目前的实现是每一种场景的下推都会有对应的优化规则来处理,比如PushPredicateIntoTableScan、PushProjectionIntoTableScan等。
从上面的下推接口来看,透传给各个connector的信息比较少,通用的下推优化规则只能让connector做简单的下推转换,而一些更复杂点或者connector特有的转换都无法得到满足。
这里通过谓词下推这个接口来说明目前存在的问题:
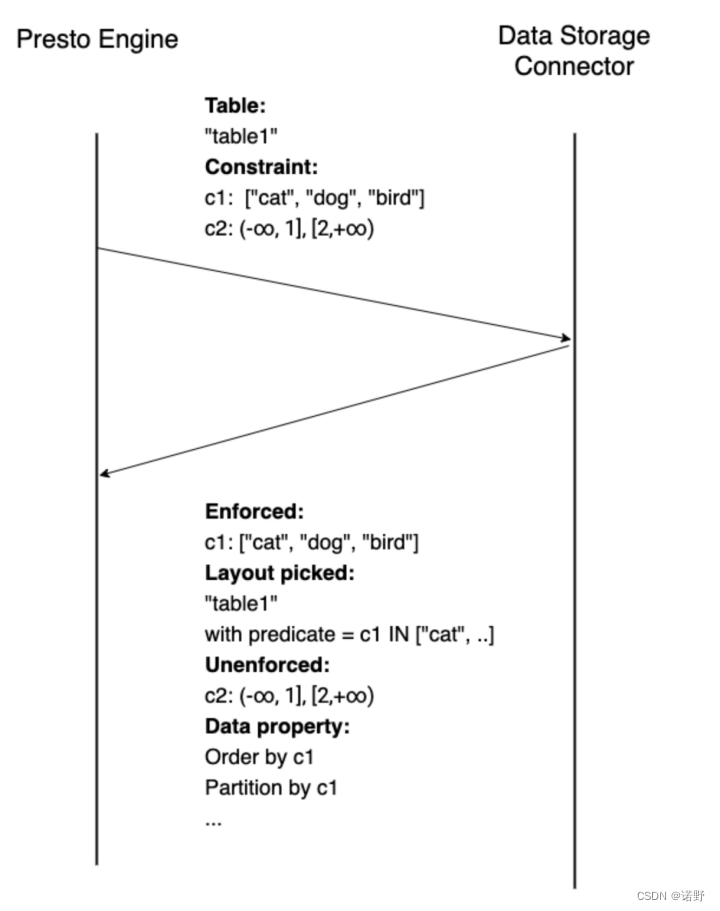
谓词下推用于允许connector在底层数据源上执行过滤。然而,现有的谓词下推功能存在一定的限制,限制了connector的功能。可以下推的表达能力有限,connector无法改变计划的结构。
以上图展示了planner优化器和connector谓词下推交互的一个情况:
- planner优化器分析出可以下推的Constraint给connector,
- 每个connector分析哪些可以下推,能下推的做TableScanNode转换,最后把剩余不能下推的表达式返回。
- planner优化器如果发现Constraint没有完整下推,那么就会保留FilterNode做剩余filter过滤。
问题总结
- 目前trino虽然对各个下推的大方向场景都有支持,但是对于查询SQL使用的RowExpression有比较大约束。一旦用户使用的SQL中采用的RowExpression稍微复杂一点如使用标量函数、cast转换、使用数组等,就会导致下推失败;而正常SQL基本都会带有一些稍微复杂的RowExpression,如使用时间函数、cast类型隐式转换。
- child的PlanNode下推失败,会导致parent的PlanNode无法继续下推。比如下面这个案例原先可以完整下推,但是如果将t1.c3 = 'trino'改为 lower(t1.c3) = 'trino',那么就会导致FilterNode下推失败,从而导致原先可以下推的JoinNode、AggregationNode、LimitNode都无法下推。最终只有Project可以下推,整体的下推效果就变的非常差。
select t1.c1, t2.c2 from t1 join t2 on t1.c1 = t2.c1 where t1.c3 = 'trino' limit 3; -- 生成的PlanNode Tree TableScan ProjectNode FilterNode JoinNode AggregationNode LimitNode - 现有的下推接口比较通用,只能做一些简单通用的下推转换。在connector无法获取到足够的上下文信息时,无法做一些满足复杂的转换,同时扩展性也比较差。
新框架
我们希望通过实现一套新的算子下推框架来解决目前实现很多表达式无法下推的情况,使DBMS数据源可以覆盖更多的下推场景和更好的下推效果。
技术思路
为了能让各个connector实现可以灵活的应用下推能力,我们设计了一套ConnectorPlanOptimizer设计,每一个connector都可以提供自己的ConnectorPlanOptimizer实现(可以是多个)。而planner优化器会分析哪些PlanNode属于同一个connector实例,然后把属于同一个connector实例的PlanNode子树传递给ConnectorPlanOptimizer,由connector来改写PlanNode。由于connector可以获取到整个逻辑计划树,拿到的信息更多更全,那么就有能力做更多场景的下推转换。
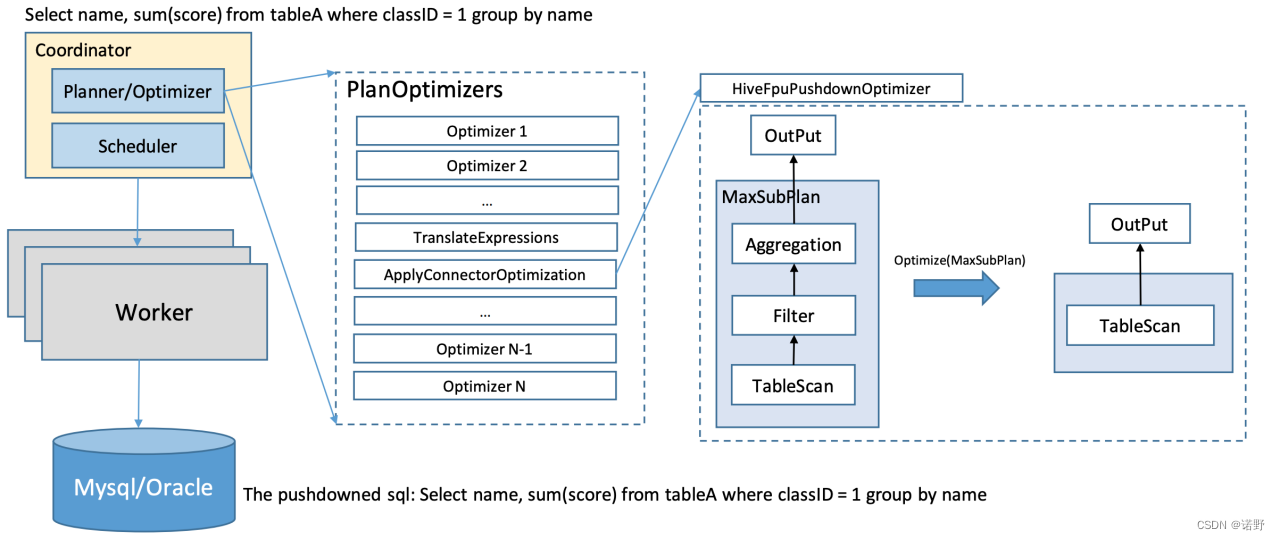
下面是一个SQL的下推优化流程:
- 新增一个新优化器规则ApplyConnectorOptimization。
- ApplyConnectorOptimization会基于逻辑计划树分析出属于同一个connector的最大逻辑计划树 maxSubplan。
- ApplyConnectorOptimization获取connector的ConnectorPlanOptimizer优化规则,然后应用maxSubplan去改写,并返回最终改写的逻辑计划。
- connector如何可以做到完整下推,那么最终返回的就只有一个TableScanNode;然后也可以返回部分下推的逻辑计划树。
而ConnectorPlanOptimizer定义如下:
/**
* Given a PlanNode, return a transformed PlanNode.
* <p/>
* The given {@param maxSubplan} is a highest PlanNode in the query plan, such that
* (1) it is a PlanNode implementation in SPI (i.e., not an internal PlanNode), and
* (2) all the TableScanNodes that are reachable from {@param maxSubplan} are from the current connector.
* <p/>
* There could be multiple PlanNodes satisfying the above conditions.
* All of them will be processed with the given implementation of ConnectorPlanOptimizer.
* Each optimization is processed exactly once at the end of logical planning (i.e. right before AddExchanges).
*/
public interface ConnectorPlanOptimizer
{
PlanNode optimize(
PlanNode maxSubplan,
ConnectorSession session,
VariableAllocator variableAllocator,
PlanNodeIdAllocator idAllocator);
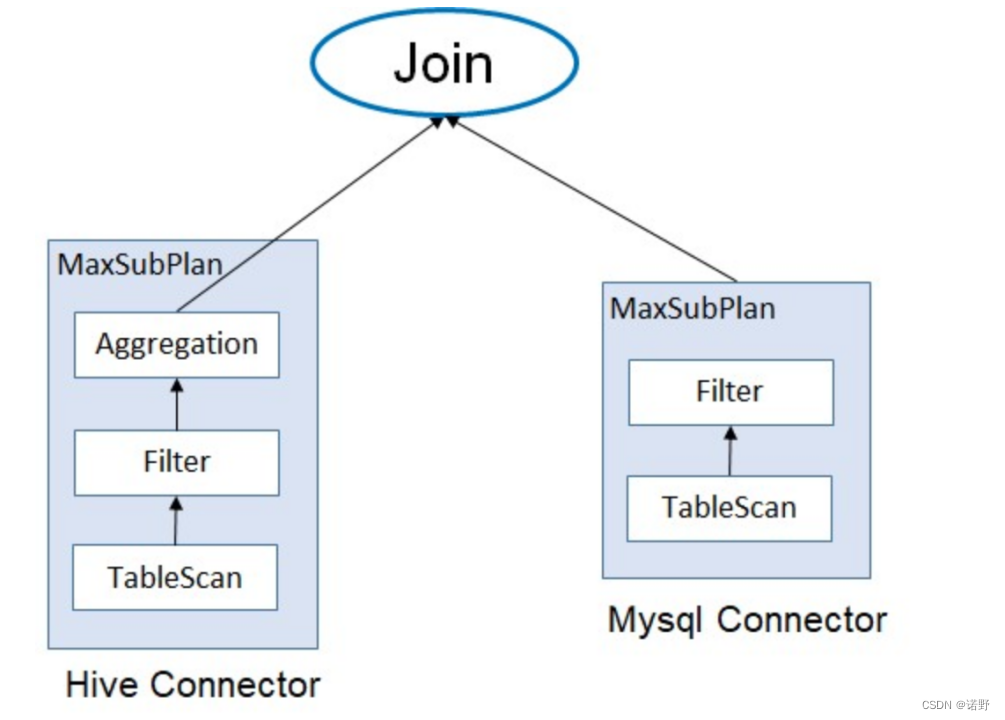
}当SQL使用多个connector,每一个connector分别各自优化://比如下面的场景是两个数据源进行join
- 当JoinNode两边是不同的connector,JoinNode就无法作为maxSubplan。
- 当JoinNode两边是同一个connector,JoinNode就可以作为maxSubplan传递给connector去做join的下推优化。
JDBC通用转换
由于jdbc的DBMS数据源是本次重点解决的场景,同时jdbc数据源都是SQL。而各种jdbc数据源的SQL语法大体上基于标准sql来扩展,通用性比较大,主要的差异可能在类型、函数上等差异,所以我们开发一个通用的下推优化规则。
每一个jdbc connector只需要配置一个映射转换规则配置文件而不需要开发代码即可完成一个新数据源的下推转换。而这个规则配置需要配置比如类型转换、函数转换、可以及一些复杂表达式的转换等。
下面是一个clickhouse数据源的下推转换配置案例(不全)://一般一个数据源的配置内容会比较多,特别是涉及到几百个函数的转换配置。
{
"syntax":{
"identifierQuote":"\"",
"nameCaseInsensitive":true
},
"dataTypes":{
"mappings":[
{
"trino":"boolean",
"source":"UInt8",
"jdbcTypeId": 16,
"rewriteToTrinoType":"smallint"
},
{
"trino":"tinyint",
"source":"Int8",
"jdbcTypeId": -6
},
{
"trino":"integer",
"source":"Int32",
"jdbcTypeId": 4
},
{
"trino":"bigint",
"source":"Int64",
"jdbcTypeId": -5
},
{
"trino":"double",
"source":"Float64",
"jdbcTypeId": 8
},
{
"trino":"real",
"source":"Float32",
"jdbcTypeId": 7
},
{
"trino":"varchar",
"source":"String",
"jdbcTypeId": 12
},
{
"trino":"date",
"source":"Date",
"jdbcTypeId": 91
},
{
"trino":"timestamp",
"source":"DateTime",
"jdbcTypeId": 93
}
]
},
"relationalAlgebra":{
"aggregation":{
"enable":true,
"functions":[
{
"name":[
"count"
],
"signatures":[
{
"args":[],
"return":"bigint"
},
{
"args":[
"bigint"
],
"return":"bigint"
}
]
},
{
"name":[
"min","max"
],
"signatures":[
{
"args":[
"tinyint"
],
"return":"tinyint"
},
{
"args":[
"integer"
],
"return":"integer"
},
{
"args":[
"bigint"
],
"return":"bigint"
},
{
"args":[
"real"
],
"return":"real"
},
{
"args":[
"double"
],
"return":"double"
}
]
},
{
"name":[
"sum"
],
"signatures":[
{
"args":[
"bigint"
],
"return":"bigint"
},
{
"args":[
"double"
],
"return":"double"
},
{
"args":[
"real"
],
"return":"real"
}
]
},
{
"name":[
"avg"
],
"signatures":[
{
"args":[
"bigint"
],
"return":"double"
},
{
"args":[
"real"
],
"return":"real"
},
{
"args":[
"double"
],
"return":"double"
}
]
}
]
},
"join":{
"enable":true,
"supportedJoinOnCondition":false
}
},
"expression":{
"constant":{
"timestamp": {
"dateTimeFormatter": "yyyy-MM-dd HH:mm:ss"
},
"boolean": {
"disable":"true"
}
},
"operators":[
{
"name":[
"like"
],
"signatures":[
{
"args":[
"varchar",
"varchar"
],
"return":"boolean"
}
]
},
{
"name":[
"+","-","*","/","%"
],
"signatures":[
{
"args":[
"tinyint",
"tinyint"
],
"return":"tinyint"
},
{
"args":[
"integer",
"integer"
],
"return":"integer"
},
{
"args":[
"bigint",
"bigint"
],
"return":"bigint"
},
{
"args":[
"real",
"real"
],
"return":"real"
},
{
"args":[
"double",
"double"
],
"return":"double"
}
]
},
{
"name":[
"=","<","<="
],
"signatures":[
{
"args":[
"tinyint",
"tinyint"
],
"return":"boolean"
},
{
"args":[
"integer",
"integer"
],
"return":"boolean"
},
{
"args":[
"bigint",
"bigint"
],
"return":"boolean"
},
{
"args":[
"real",
"real"
],
"return":"boolean"
},
{
"args":[
"double",
"double"
],
"return":"boolean"
},
{
"args":[
"timestamp",
"timestamp"
],
"return":"boolean"
},
{
"args":[
"date",
"date"
],
"return":"boolean"
},
{
"args":[
"varchar",
"varchar"
],
"return":"boolean"
}
]
},
{
"name":[
"CAST"
],
"signatures":[
{
"args":[
"integer"
],
"return":"double",
"rewrite": "CAST({0} as Float64)"
},
{
"args":[
"integer"
],
"return":"bigint",
"rewrite": "CAST({0} as Int64)"
},
{
"args":[
"bigint"
],
"return":"double",
"rewrite": "CAST({0} as Float64)"
}
]
}
],
"scalarFunctions":[
{
"name":[
"not"
],
"signatures":[
{
"args":[
"boolean"
],
"return":"boolean"
}
]
},
{
"name":[
"abs"
],
"signatures":[
{
"args":[
"int"
],
"return":"int"
},
{
"args":[
"bigint"
],
"return":"bigint"
}
]
},
{
"name":[
"date_trunc"
],
"signatures":[
{
"args":[
"varchar",
"date"
],
"return":"date",
"rewrite": "date_trunc({0}, {1})"
},
{
"args":[
"varchar",
"timestamp"
],
"return":"timestamp",
"rewrite": "date_trunc({0}, {1})"
}
]
},
{
"name":[
"year"
],
"signatures":[
{
"args":[
"date"
],
"return":"bigint",
"rewrite": "cast(toYear({0}) as Int64)"
}
]
},
{
"name":[
"substr","substring"
],
"signatures":[
{
"args":[
"varchar",
"bigint",
"bigint"
],
"return":"varchar"
},
{
"args":[
"varchar",
"bigint"
],
"return":"varchar"
}
]
}
],
"windowFunctions":[
{
"name":[
"rank"
],
"signatures":[
{
"args":[],
"return":"bigint"
}
]
}
]
}
}
函数转换案例
// clickhouse数据源的一个函数转换案例,下图是year函数的转换规则。
原始SQL:select * from t1 where year(c1) = 2023
转换后: select * from t1 where cast(toYear(c1) as Int64) = 2023

下推效果


上面是一个基于clickhouse数据源,使用tpch的一个复杂query来验证下推效果。在增加使用了clickhouse数据源的JDCB转换配置,开启新下推框架的能力,通过explain上面的sql,我们可以看到整个query优化后只剩下了TableScan和Output的物理计划,说明做到了完整的下推(目前22个tpch query绝大部分可以做到完整下推)。
总结
鉴于trino老的下推实现只能做一些简单表达式的下推,在真实业务的复杂SQL场景下,下推的效果很不理想。下推的效果对性能的影响非常大,特别是JDBC数据源。所以我们实现了新的算子下推框架去解决,每一个数据源connector可以更深入的参与优化。同时针对JDBC数据源,我们开发了一套通用优化规则,接入一个新数据源支持定制迭代相关的转换规则配置文件即可,而不需要开发代码。
总结一下目前框架的能力主要有:
- 支持函数下推,包括标量函数、聚合函数和窗口函数。
- 支持算术Operator、case when等复杂表达式的下推转换。
- 支持下推的PlanNode种类达到15+,未来还会继续增加,用于覆盖更多的场景。
- 通用的JBDC数据源下推优化规则,下推表达式可配置化。
- 触发下推后,避免了大数据量低效的扫描,从而性能提升1到2个数量级。

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









