










3. 常用STL的使用
3.1. string
(1)string类的实现(使用strlen、strcpy、strcat、strcmp等,注意判NULL)。
(2)C++字符串和C字符串的转换:data()以字符形式返回字符串内容,但不添加’\0\;c_str()返回一个以’\0’结尾的字符数组;copy()把字符串内容复制或写入既有的c_string或字符数组内。
(3)string和int互转:snprintf()、strtol/strtoll/strtoull.
(4)常用成员函数:capacity()、max_size()、size()、length()、empty()、resize()
3.2. vector
(1)容器大小size()指元素个数,容量capacity()指分配的内存大小
(2)遍历:for(int i=0;i<a.size();++i、for(iter=ivector.begin();iter!=ivector.end();iter++)、for_each
(3)查找find()、删除erase()/pop_back()、增加insert()/push_front(),注意for 循环遍历删除时的坑:for语句条件里删除元素时,返回值指向已删除元素的下一个位置,不是删除元素时则直接++
(4)reserve()提前设定容量大小;swap()强行释放vector所占内存
3.3. map
(1)map内部自建一颗红黑树,具有对数据自动排序的功能。须回顾二叉树、红黑树。。。
(2)插入pair数据、数组方式插入、数据方式覆盖插入
(3)遍历:利用前向迭代器、利用反向迭代器、数组方式
(4)查找find()、删除erase()、排序less/greater
3.5. set
(1)创建、插入元素、删除元素、查找元素等。。
4.编译
4.1.编译与链接
(1)过程:预处理(prepressing),编译(compilation),汇编(assembly),链接(linking)

(2)预处理:主要处理那些源代码文件只能够的以”#”开始的预编译指令。比如“#include”、“#define”,过滤所有注释,添加行号,保留#pragma编译器指令等
(3)编译:扫描(词法分析)、语法分析、语义分析、源代码优化、代码生成和目标代码优化

(4)链接:把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确的衔接。
原理:把一些指令对其他符号地址的引用加以修正。链接过程主要包括了地址和空间分配、符号决议和重定位等

(5)静态链接库和动态链接库
1.动态链接库有利于进程间资源共享;
2.动态链接库升级容易,用静态库则需要重新编译;
3.许多进程或应用程序可在磁盘上共享动态库的一个副本,可节省内存和减少交换操作,节省磁盘空间;
4.静态链接库在编译的时候将库函数装载到程序中,执行速度更快。
(6)g++和gcc
1.后缀为.c的,gcc将其当作C程序,而g++当作是C++程序;后缀为.cpp的,两者都认为是C++程序;
2.编译阶段,g++会自动调用gcc,两者等价;但因为gcc不能自动和C++程序使用的库链接,所以通常用g++来完成链接,所以通常直接用g++编译、链接;
3.extern”C”与gcc/g++并无关系。
4.2.makefile的撰写
(1)书写规则,第一部分为依赖关系,第二部分为生成目标的方法:
target : prerequisites
<tab>command
<tab>commandtarget也就是一个目标文件,可以是.o文件,也可以是执行文件,还可以是一个标签(Label)。
prerequisites就是,要生成那个target所需要的文件或是目标。
command也就是make需要执行的命令(任意的Shell命令)。这里要注意的是在命令前面要加上一个tab键,不是空格,是按一个tab键按出来的空格。
(2)make clean用于清除编译产生的二进制文件,保留源文件:
clean:
@echo "cleaning project"
-rm main *.o
@echo "clean completed"在rm命令前面加了一个小减号的意思就是,也许某些文件出现问题,但不要管,继续做后面的事
(3)变量,用$(objects)的方式来使用
(4)$@扩展成当前规则的目的文件名;$<扩展成依靠列表中的第一个依靠文件;$^ 扩展成整个依靠列表(除掉重复文件名)
4.3.目标文件
(1)目标文件:源代码编译后但是没有进行链接的那些中间文件,比如win下的.obj文件、linux下的.o文件,与可执行文件的内容以及格式很类似。
目标文件中的内容至少有编译后的机器指令代码、数据。还包括连接时所需要的一些信息,比如符号表、调试信息、字符串等。一般,目标文件会将这些信息按照不同的属性进行分段(其实就是多个一定长度的区域)。


(2)ELF文件主要由文件头(ELF header)、代码段(.text)、数据段(.data)、.bss段、只读数据段(.rodata)、段表(section table)、符号表(.symtab)、字符串表(.strtab)、重定位表(.rel.text)如下图所示:

(3)代码段与数据段分开的原因:
1.权限分别管理。对进程来说,数据段是可读写的,指令段是只读的。这样可以防止程序指令被改写。
2.指令区与数据区的分离有助于提高程序的局部性,有助于对CPU缓存命中率的提高。
3.当系统运行多个改程序的副本的时候,他们对应的指令都是一样的,此时内存只需要保留一份改程序的指令即可。当然,每个副本进程的数据区域是不一样的,他们是进程私有的

(4)阅读ELF文件的工具readelf;获得二进制文件里符号的工具nm;减少目标文件大小的工具strip
5.调试
5.1.strace
(1)通过跟踪系统调用观察程序在后台所做的事情
(2)跟踪信号传递
(3)统计系统调用
5.2.gdb
(1)常用调试命令
| 命令 | 描述 |
|---|---|
| backtrace(或bt) | 查看各级函数调用及参数 |
| finish | 连续运行到当前函数返回为止,然后停下来等待命令 |
| frame(或f) 帧编号 | 选择栈帧 |
| info(或i) locals | 查看当前栈帧局部变量的值 |
| list(或l) | 列出源代码,接着上次的位置往下列,每次列10行 |
| list 行号 | 列出从第几行开始的源代码 |
| list 函数名 | 列出某个函数的源代码 |
| b 行号 | 在第几行设置断点 |
| b 函数名 | 在函数处设置断点 |
| next(或n) | 执行下一行语句 |
| print(或p) | 打印表达式的值,通过表达式可以修改变量的值或者调用函数 |
| quit(或q) | 退出gdb调试环境 |
| set var | 修改变量的值 |
| start | 开始执行程序,停在main函数第一行语句前面等待命令 |
| step(或s) | 执行下一行语句,如果有函数调用则进入到函数中 |
(2)用gdb分析、定位coredump文件
5.3.top
实时显示系统中各个进程的资源占用状况

使用参考
5.4.ps
列出刚刚那一时刻正在运行的进程快照
| 参数 | 功能 |
|---|---|
| a | 显示所有进程 |
| -a | 显示同一终端下的所有程序 |
| -A | 显示所有进程 |
| c | 显示进程的真实名称 |
| -N | 反向选择 |
| -e | 等于“-A” |
| e | 显示环境变量 |
| f | 显示程序间的关系 |
| -H | 显示树状结构 |
| r | 显示当前终端的进程 |
| T | 显示当前终端的所有程序 |
| u | 指定用户的所有进程 |
| -au | 显示较详细的资讯 |
| -aux | 显示所有包含其他使用者的行程 |
| -C<命令> | 列出指定命令的状况 |
| –lines<行数> | 每页显示的行数 |
| –width<字符数> | 每页显示的字符数 |
| –help | 显示帮助信息 |
| –version | 显示版本显示 |
5.5.Valgrind
(1)Valgrind包括如下工具:
1.Memcheck。这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。这也是本文将重点介绍的部分。
2.Callgrind。它主要用来检查程序中函数调用过程中出现的问题。
3.Cachegrind。它主要用来检查程序中缓存使用出现的问题。
4.Helgrind。它主要用来检查多线程程序中出现的竞争问题。
5.Massif。它主要用来检查程序中堆栈使用中出现的问题。
6.Extension。可以利用core提供的功能,自己编写特定的内存调试工具
(2)linux下典型C程序内存空间布局:
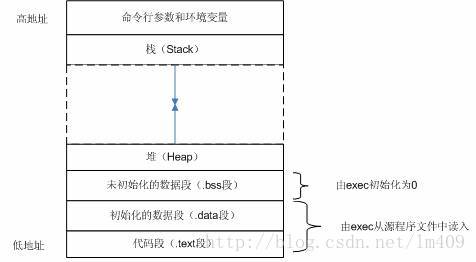
(3)堆/栈的区别
1)申请方式: 栈区内存由系统自动分配,函数结束时释放;堆区内存由程序员自己申请,并指明大小,用户忘释放时,会造成内存泄露,不过进程结束时会由系统回收。
2)申请后系统的响应: 只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出;堆区,空闲链表,分配与回收机制,会产生碎片问题(外部碎片)–>(固定分区存在内部碎片(分配大于实际),可变分区存在外部碎片(太碎无法分配))。
3)申请大小的限制:栈是1或者2M,可以自己改,但是最大不超过8M;堆,看主机是多少位的,如果是32位,就是4G
4)申请效率:栈由系统自动分配,速度较快,程序员无法控制;堆是由new分配的内存,一般速度较慢,而且容易导致内存碎片,但是用起来方便!
5)存储内容:栈,函数调用(返回值,各个参数,局部变量(静态变量不入栈));堆,一般在堆的头部用一个字节存放堆的大小,堆中的具体内容由程序员安排。
6)存取效率的比较:栈比堆快,Eg :char c[] = /”1234567890/”;char *p =/”1234567890/”;读取c[1]和p[1],c[1]读取时直接吧字符串中的元素读到寄存器cl中,而p[1]先把指针值读到edx中,再根据edx读取字符,多一次操作。
7)管理方式不同:栈,数据结构中的栈;堆,链表
8)生长方向:栈,高到低;堆,低到高
(4)Valgrind安装/使用
使用参考
《后台开发核心技术与应用实践》(一)
《后台开发核心技术与应用实践》(二)
《后台开发核心技术与应用实践》(三)
《后台开发核心技术与应用实践》(四)















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









