







ES相关学习
初识Elasticsearch
ES是一个开源的分布式全文检索和分析引擎,它可以进行实时快速检索、搜索、分析海量的数据。
Elasticsearch和MySQL比较

Mysql
1.关系型数据库,顾名思义,适用于结构化数据(数据与数据之间存在强关联)的存储和查询;
2.适用于复杂的业务逻辑控制、频繁数据更改这样的场景使用;
3.需要保证数据的原子性,可认为保证多个数据同时成功存储(不存在部分存储成功,部分数据存储失败的情况)
1.需要使用者清楚的知道自己所需要查找的数据在哪个表格,并且对内部的字段参数有所了解;
2.全表全字段检索效率较低,性能消耗大;
ES(Elastic Search)
1.非关系型数据库,全文检索引擎首选,适用于数据与数据之间关联相对独立且数据基本只增加不修改的情况;
2.适用于查询所有表格的所有字段,可认为使用者只需要知道查询的关键字,但不需要知道自己需要查询的表格和字段;
1.多数据存储时,无法保证数据的原子性;
2.数据修改效率低于MYSQL,且不支持联表查询;
————————————————
版权声明:本文为CSDN博主「饿饿好饿」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_67401417/article/details/124319855
Elasticsearch安装和部署
- 官网下载
https://www.elastic.co/cn/
本次追求稳定下载的7.1.0版本的
2. 解压安装包,运行elasticsearch.bat文件
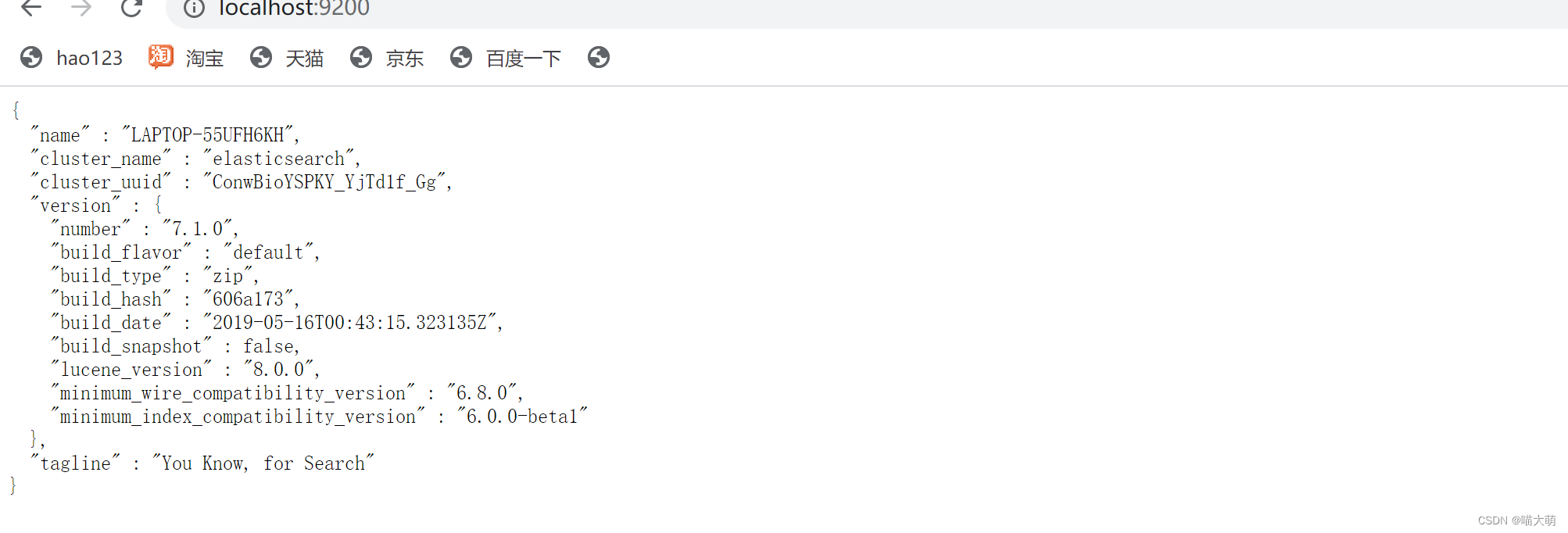
- 在浏览器输入
localhost:9200出现如下界面,则安装成功
- 安装postman和kibana
kibana是开发和设计平台,与elasticsearch一起协同开发工作,使数据检索和可视化变得更加容易

- kibana下载(尽量和elasticsearch版本保持一致)
https://www.elastic.co/cn/downloads/kibana
- 下载解压之后双击运行
kibana.bat(前提是已经运行elasticsearch)
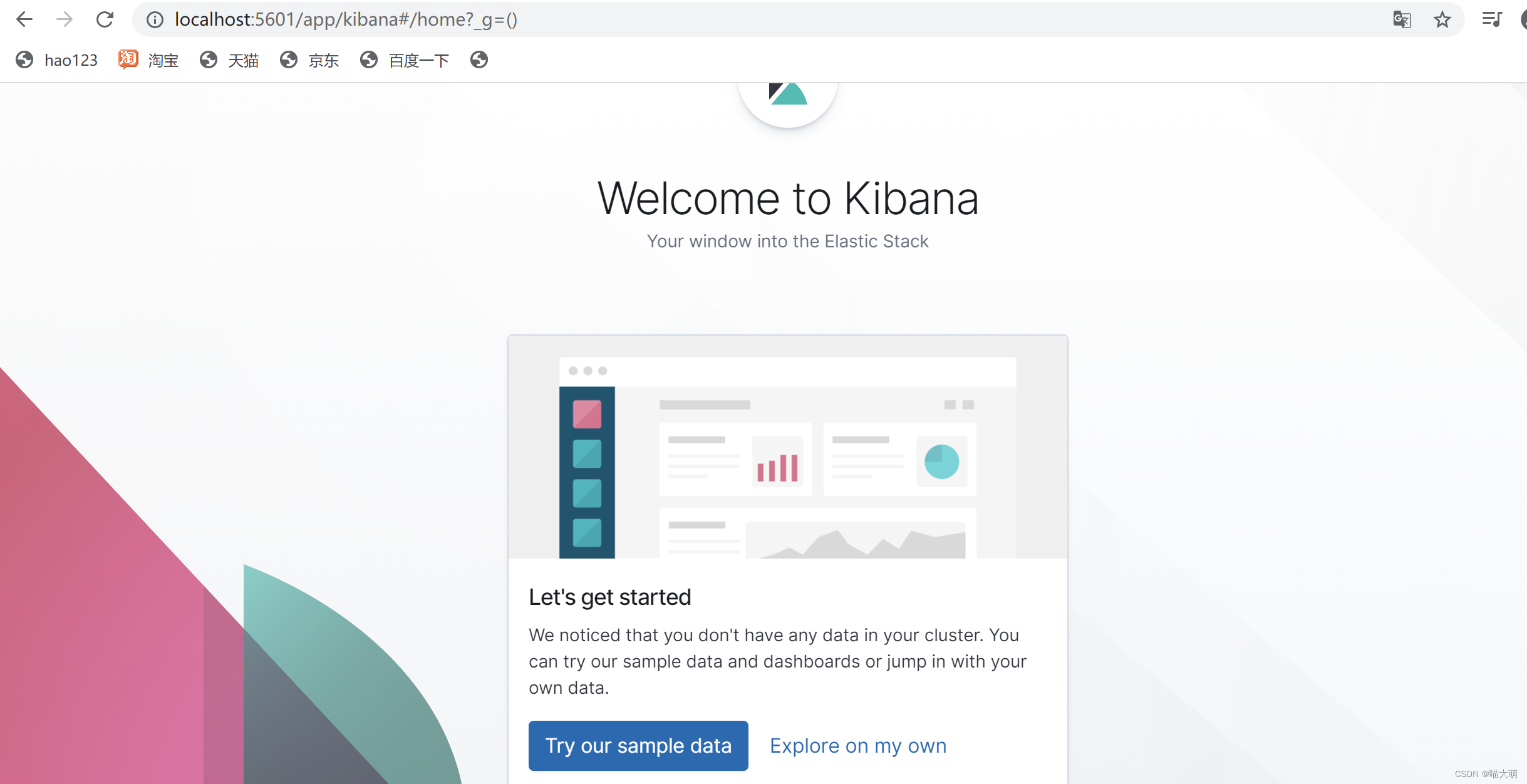
运行成功后在浏览器输入localhost:5601出现如下界面则运行成功
Elasticsearch和postman以及kibana结合使用
Elasticsearch和postman
查看所有索引
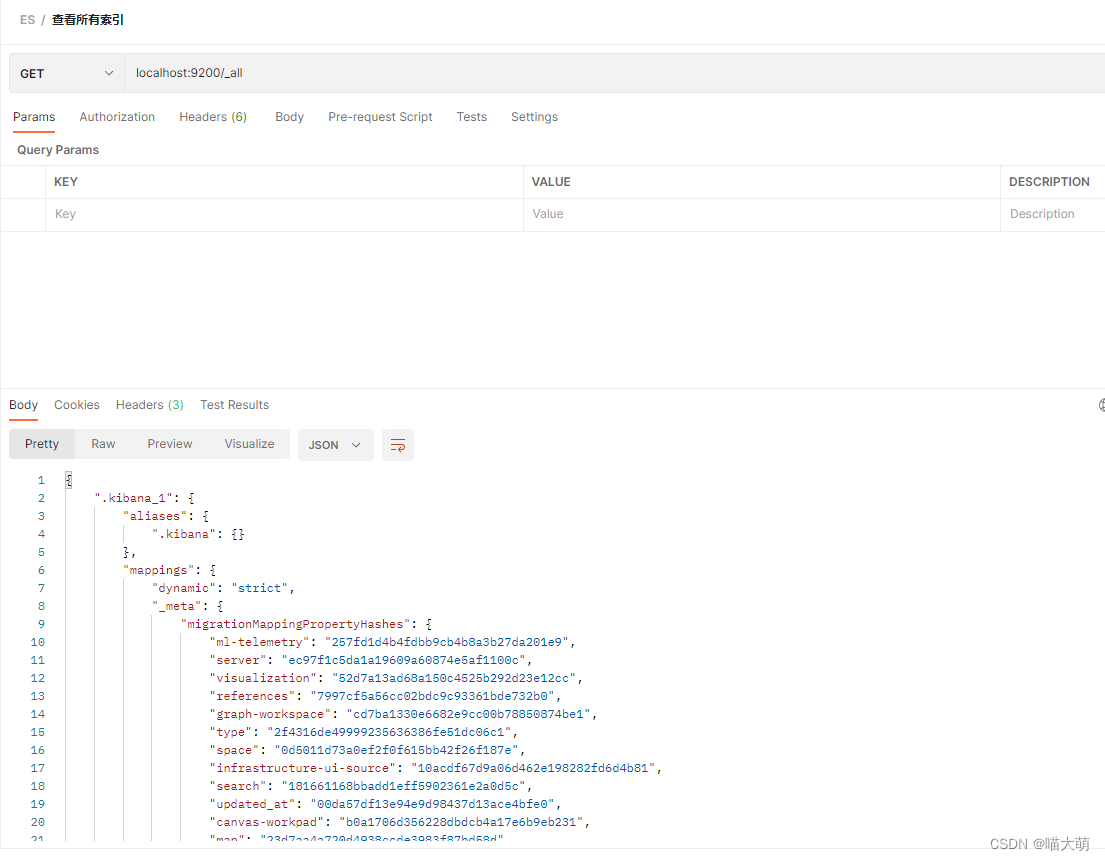
创建索引
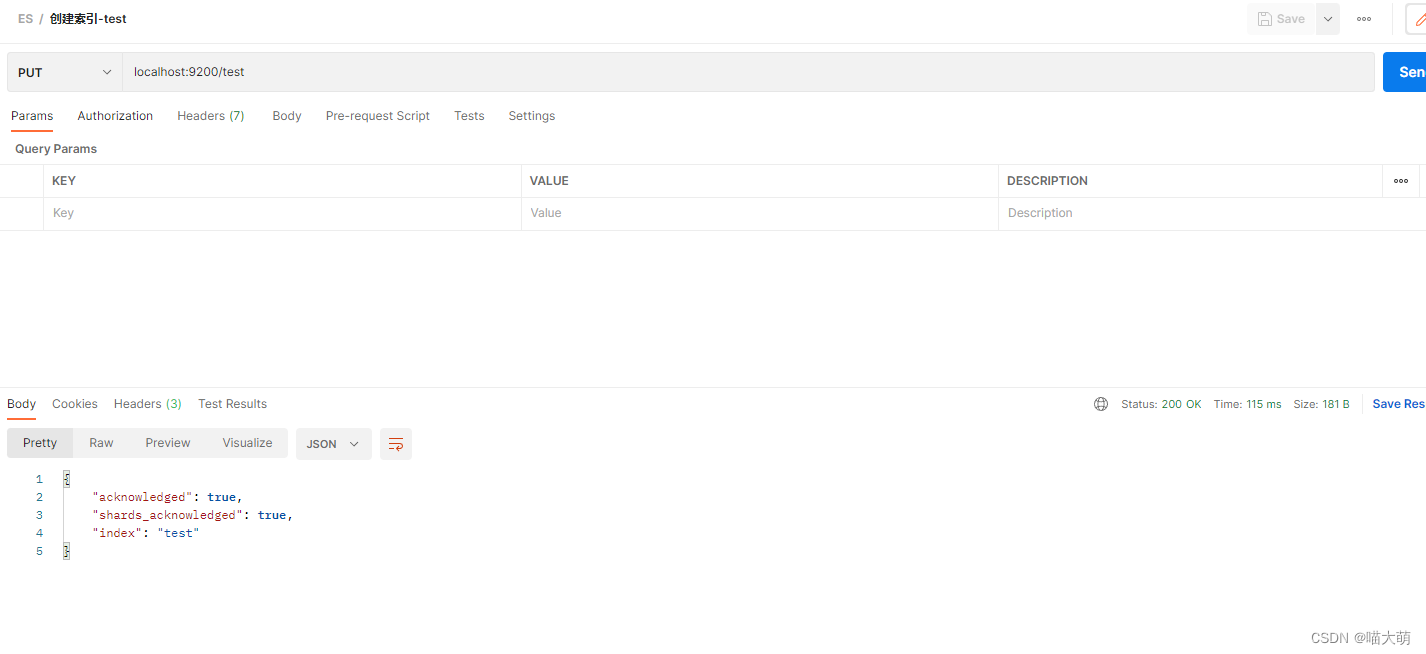
删除索引
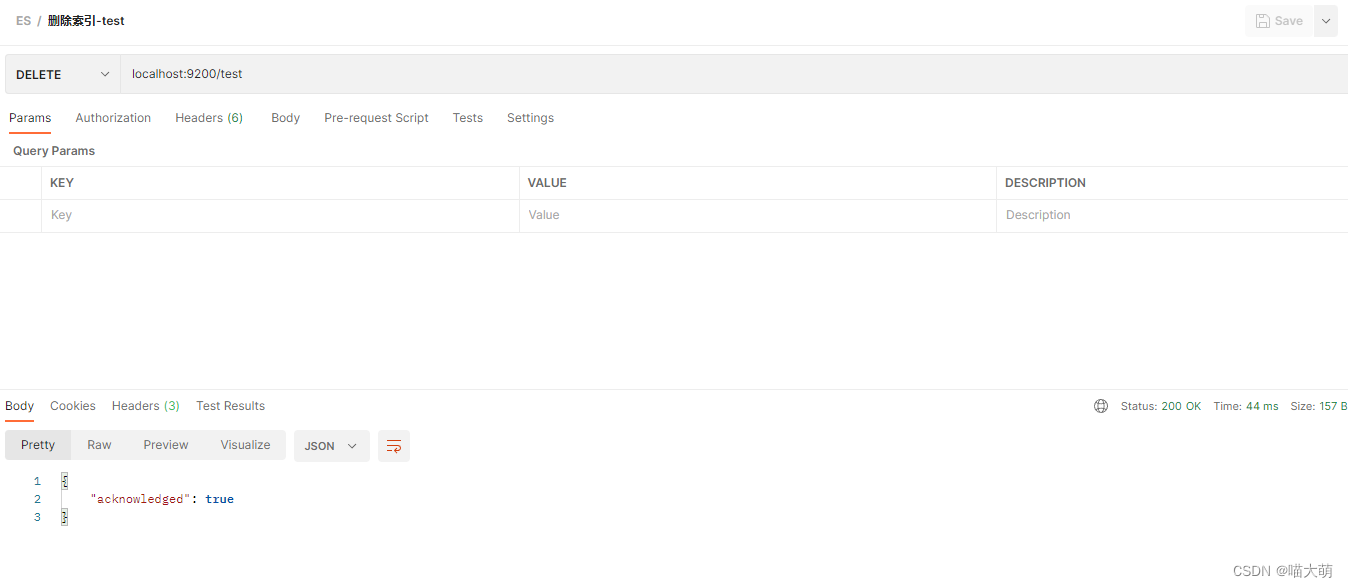
创建person索引
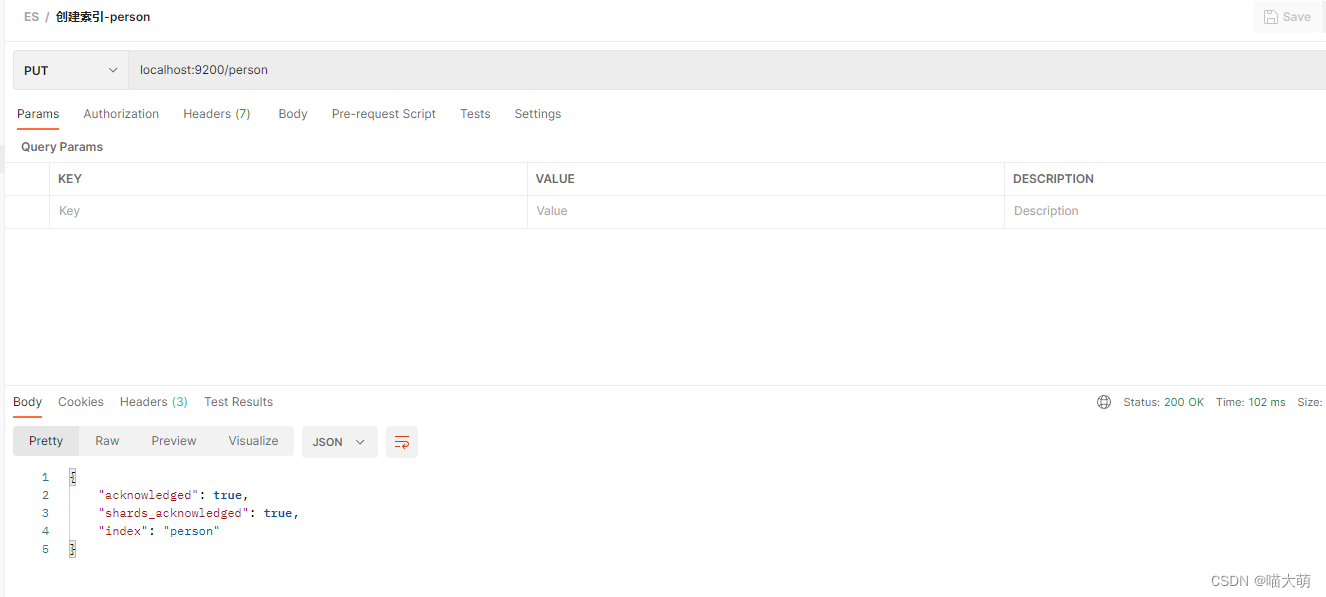
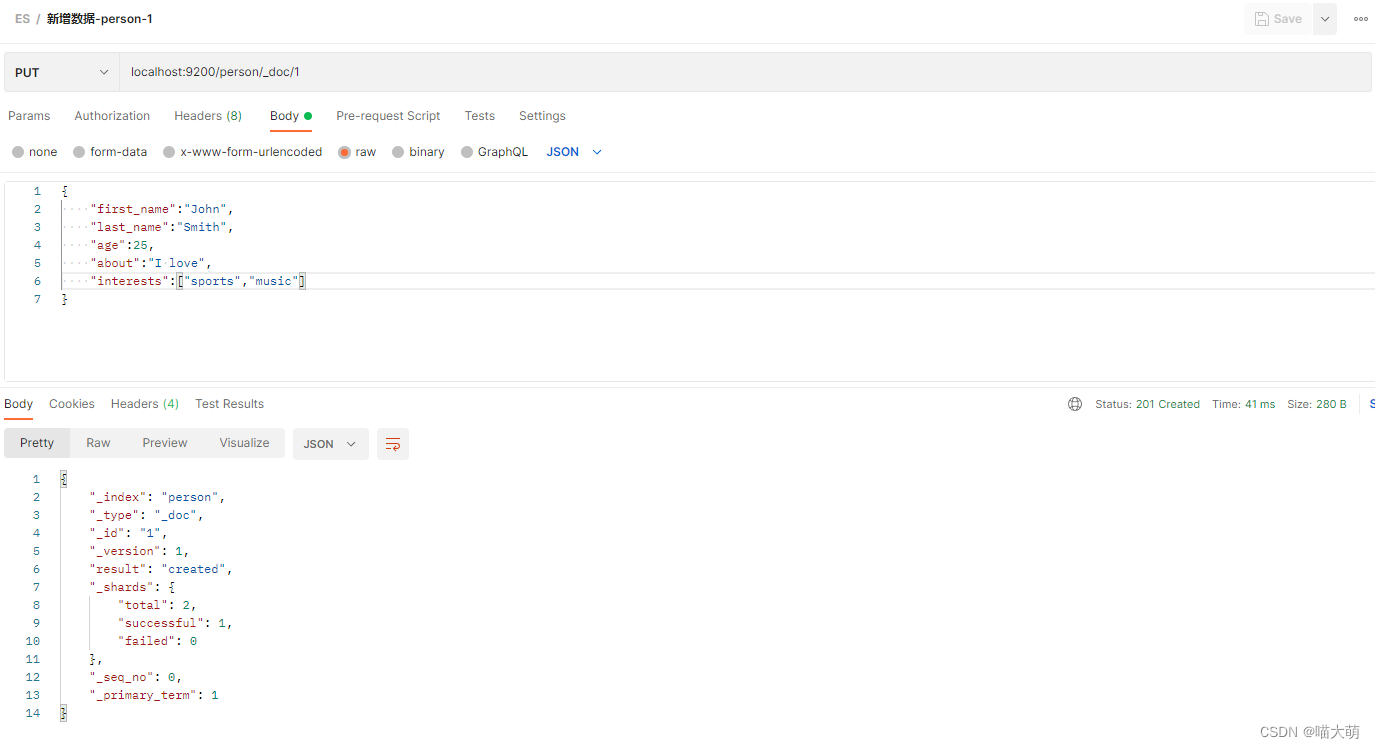
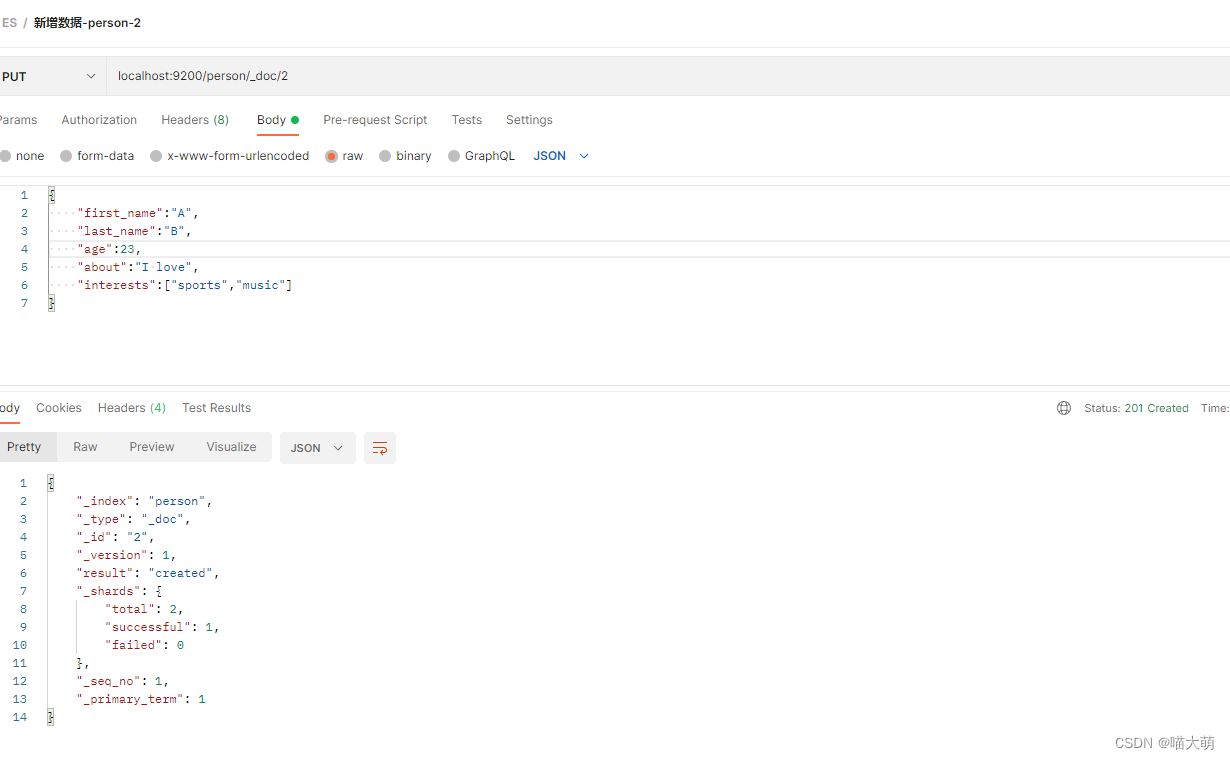
在person索引新增数据
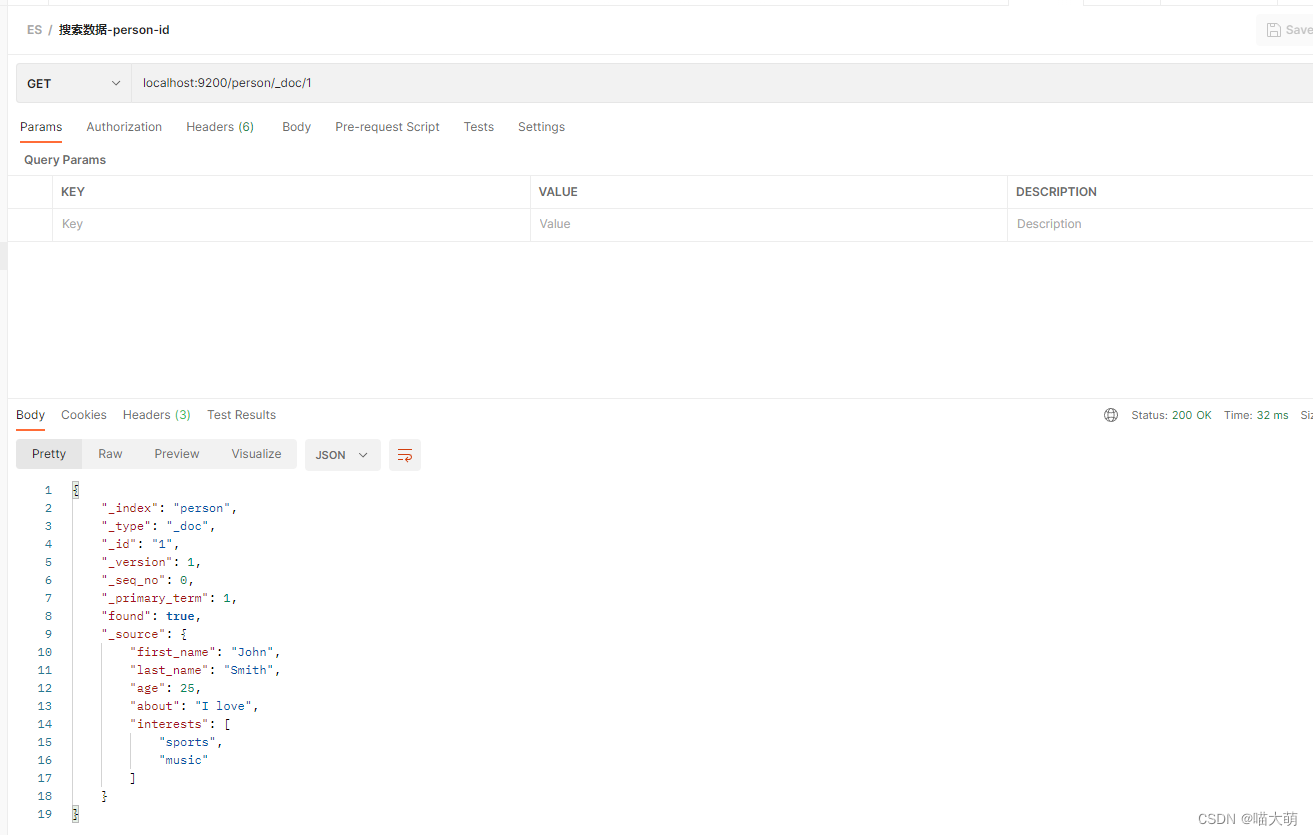
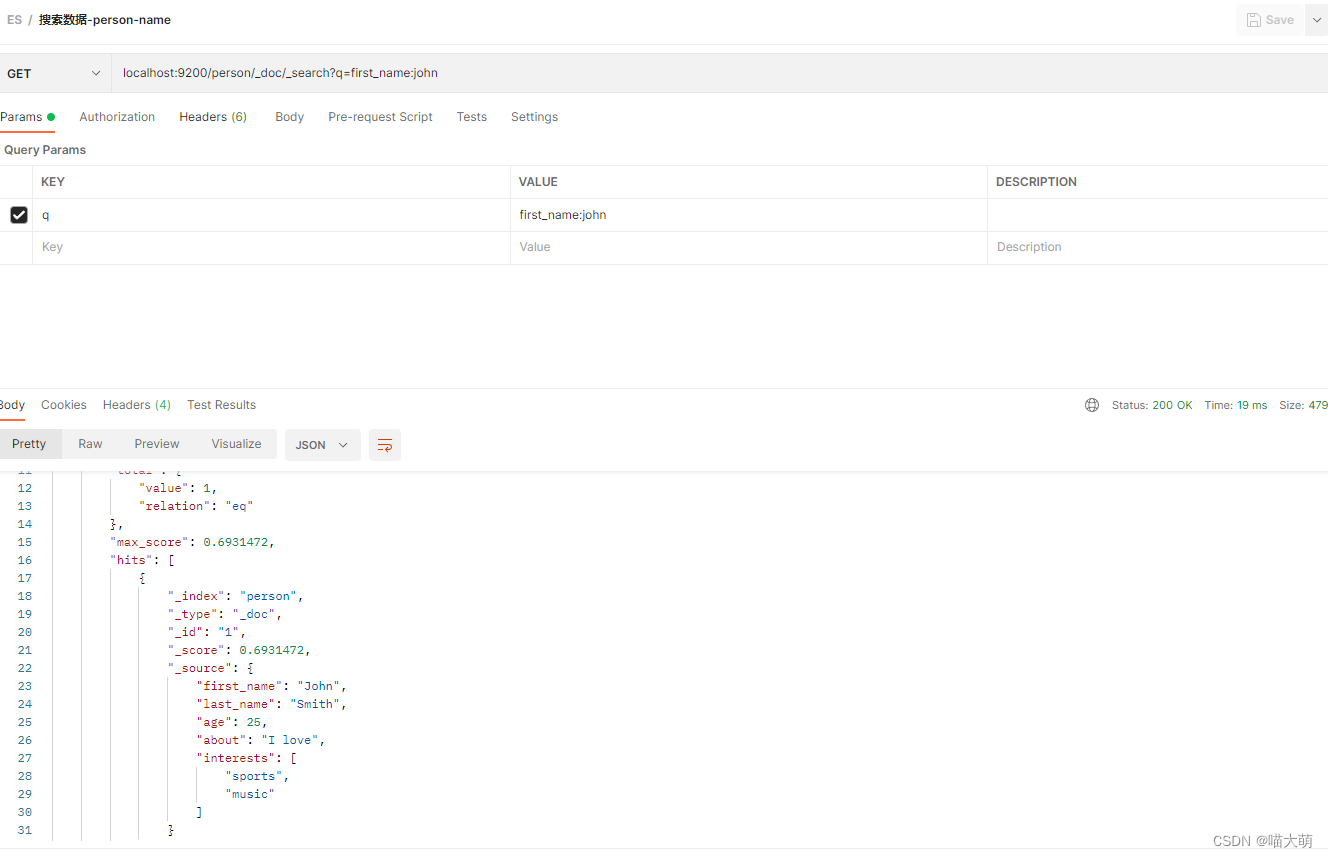
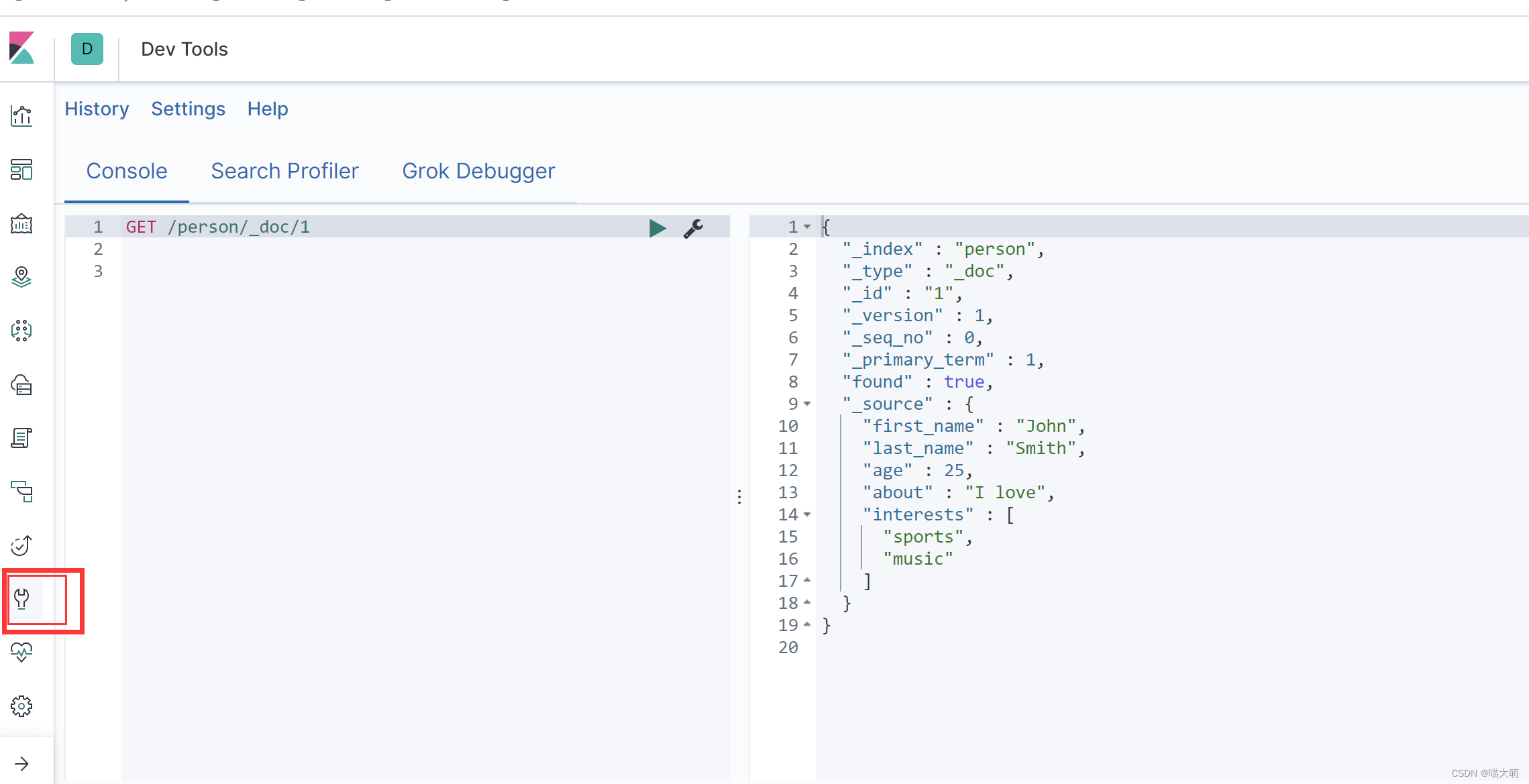
搜索数据(根据id和name)
Elasticsearch和kibana
搜索数据
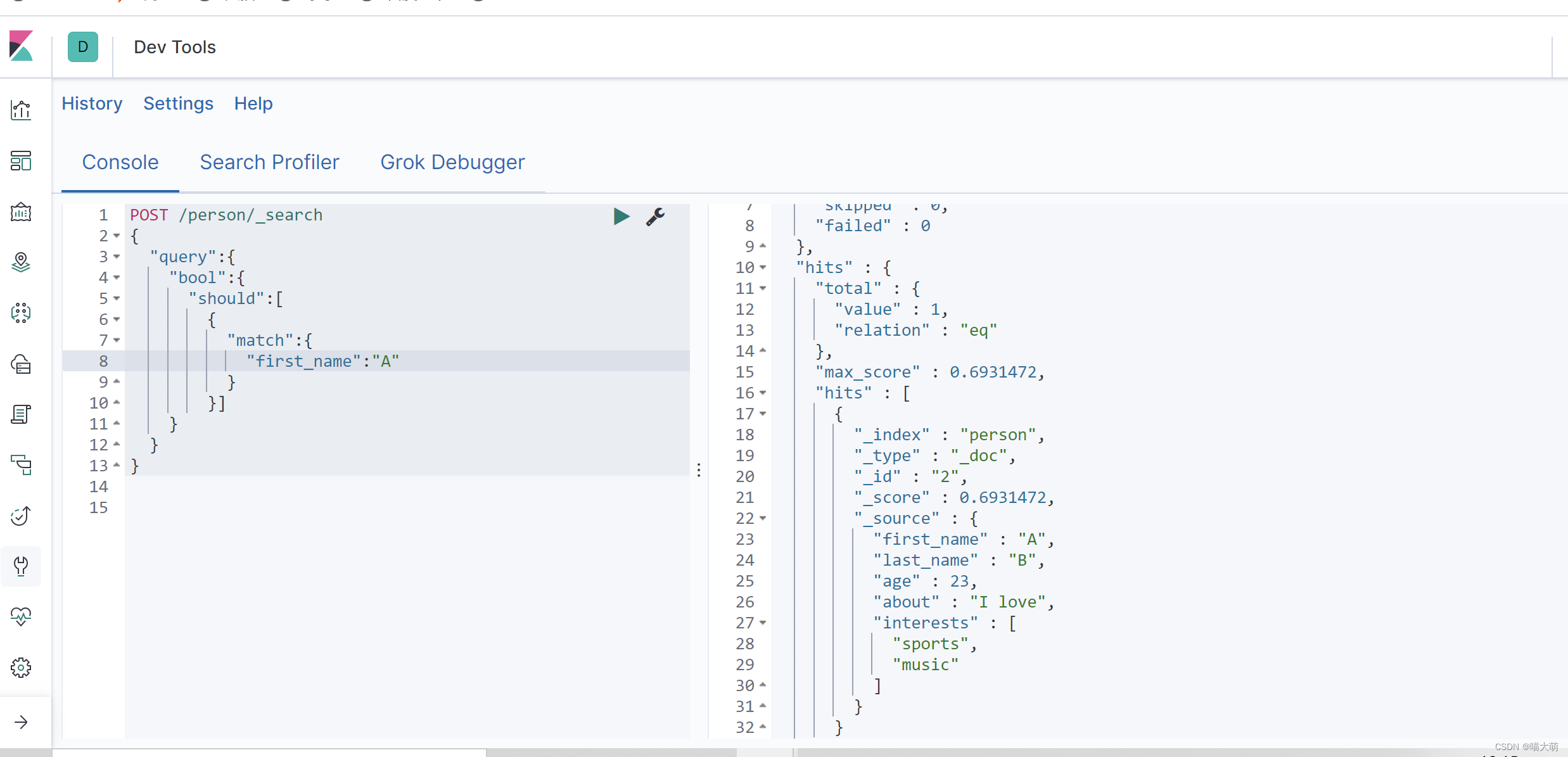
其中should类似于mysql中的条件查询语句
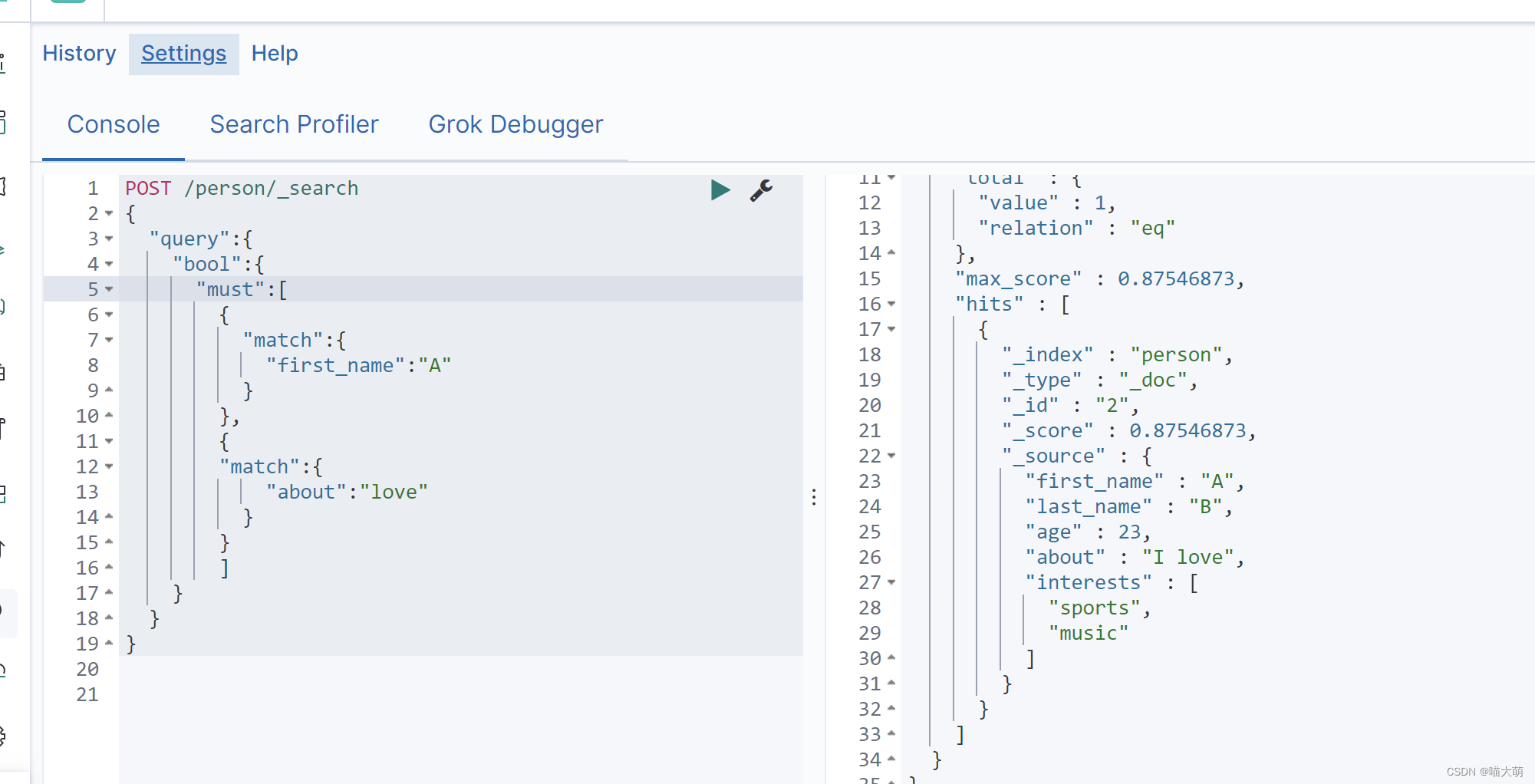
其中条件查询的话,should类似于or连接符,我们可以使用must进行拼接,类似and连接符
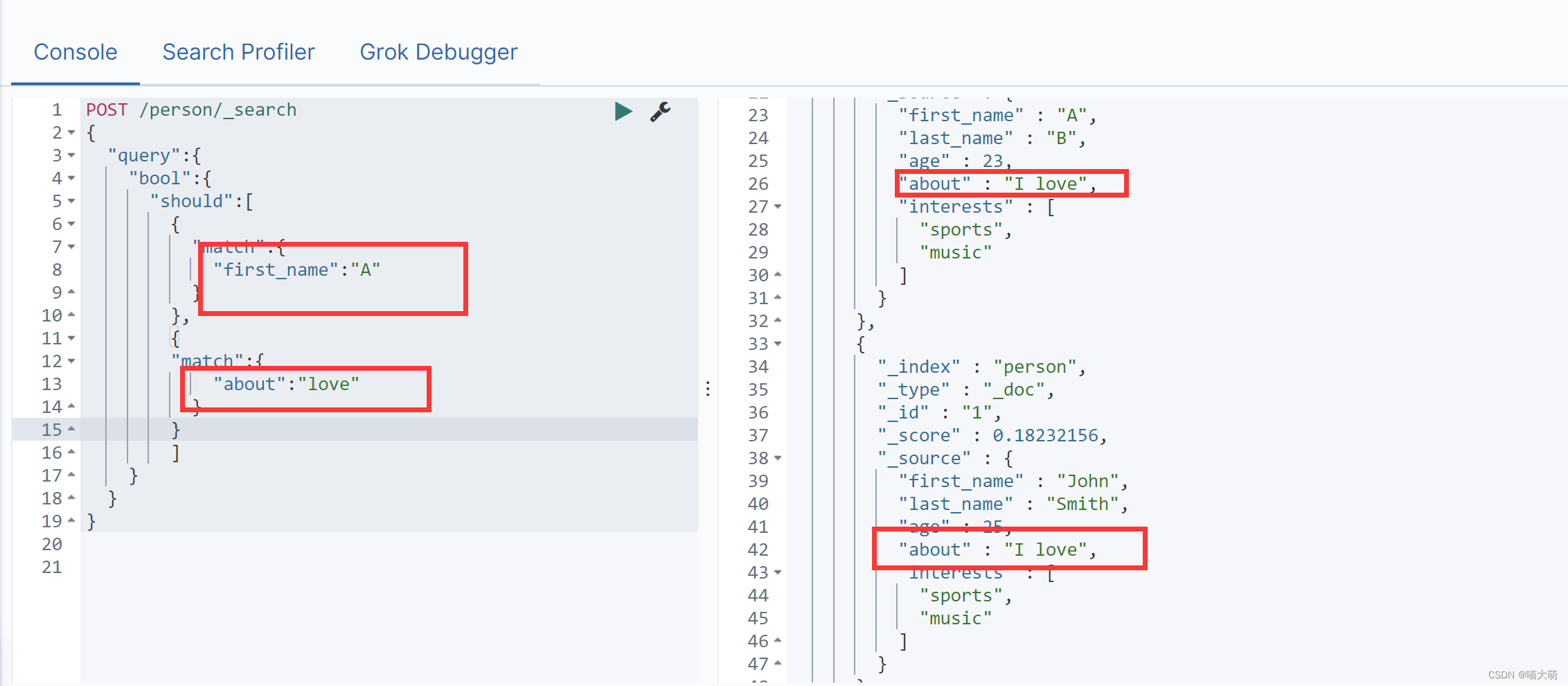
使用must拼接:
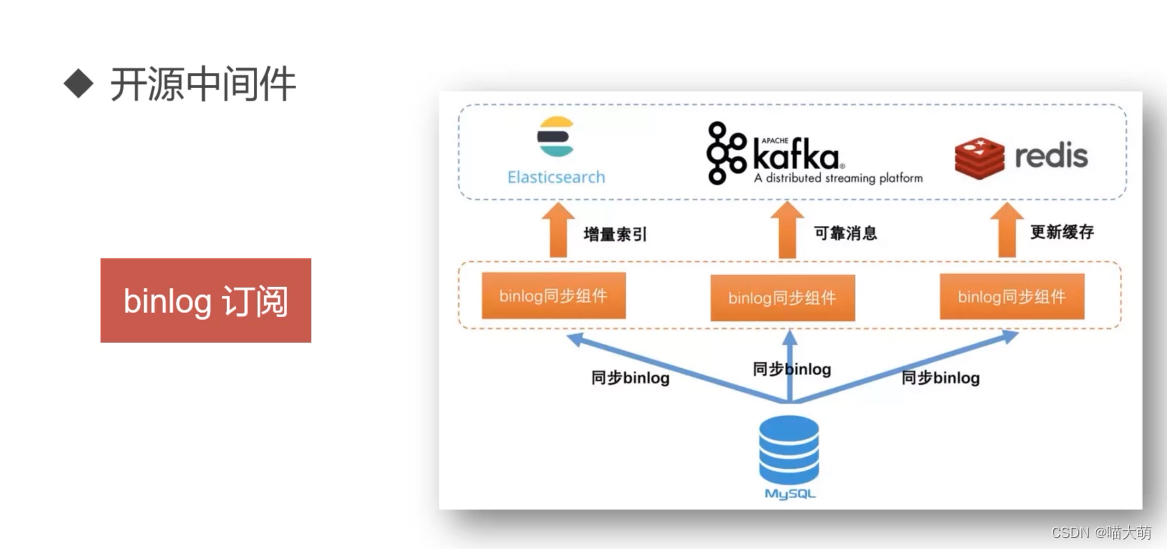
MySQL、Elasticsearch同步
全量、增量
建立完Elasticsearch索引之后,将MySQL的数据一次性全部打包发送过去称为全量。
MySQL新加入的数据成为增量。比如MySQL新加入的或者更新的。
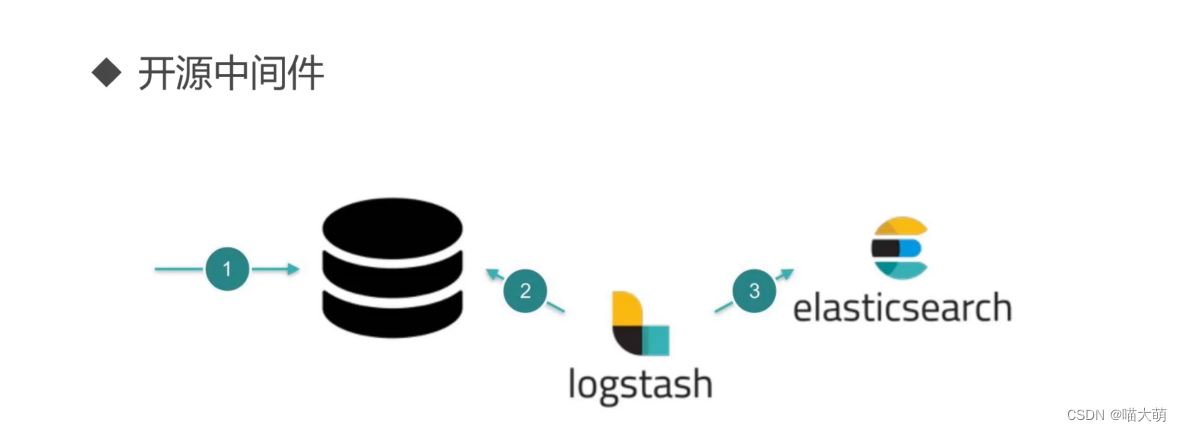
logstash全量增量解决方案
- 下载
logstash,尽量和Elasticsearch、kibana保持一个版本
https://www.elastic.co/cn/downloads/logstash
- 下载解压之后在根目录下传入本地
mysql的jar包
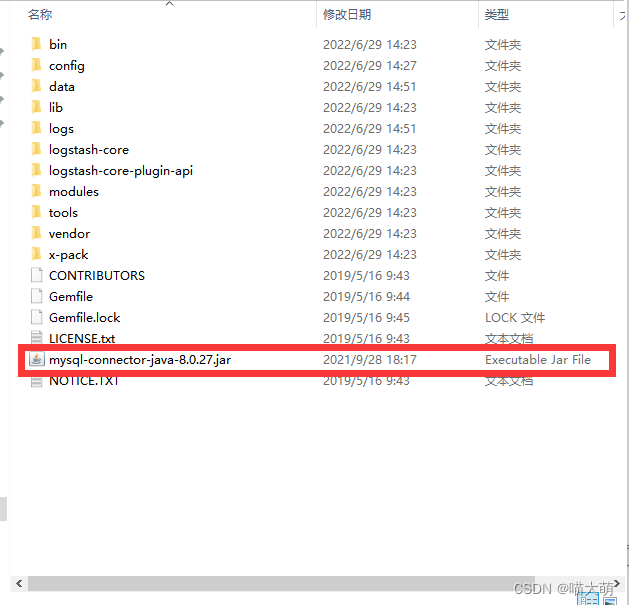
- 在
config中创建mysql.conf文件
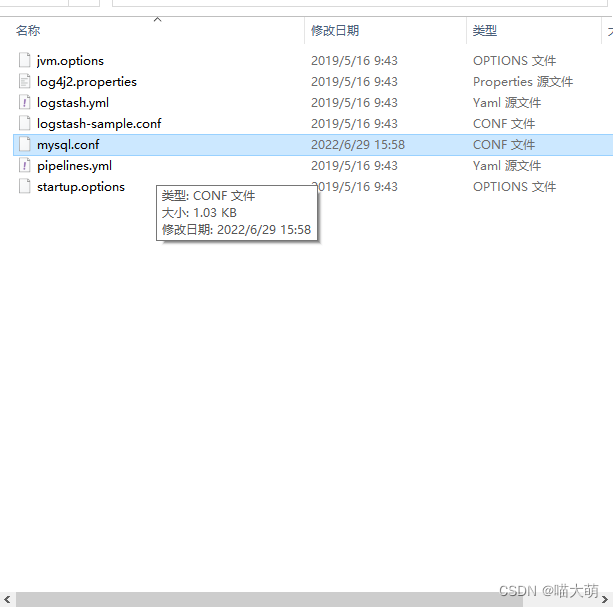
mysql.conf文件配置内容如下,注意jdbc_driver_library
路径需与logbash引入的mysql的jar包对应
input{
jdbc{
# jdbc驱动包位置
jdbc_driver_library => "C:\ES\log\logstash-7.1.0\mysql-connector-java-8.0.27.jar"
# 要使用的驱动包类
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库的连接信息
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/blog"
# mysql用户
jdbc_user => "root"
# mysql密码
jdbc_password => "root"
# 定时任务,多久执行一次查询,默认一分钟,如果想要没有延迟,可以使用 schedule => "* * * * * *"
schedule => "* * * * *"
# 清空上传的sql_last_value记录
clean_run => true
# 你要执行的语句
statement => "select * FROM t_blog WHERE update_time > :sql_last_value AND update_time < NOW() ORDER BY update_time desc"
}
}
output {
elasticsearch{
# es host : port
hosts => ["127.0.0.1:9200"]
# 索引
index => "blog"
# _id
document_id => "%{id}"
}
}
- blog建表语句,可随便插入数据
/*
Navicat Premium Data Transfer
Source Server : localhost_3306
Source Server Type : MySQL
Source Server Version : 80027
Source Host : localhost:3306
Source Schema : blog
Target Server Type : MySQL
Target Server Version : 80027
File Encoding : 65001
Date: 29/06/2022 16:30:03
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_blog
-- ----------------------------
DROP TABLE IF EXISTS `t_blog`;
CREATE TABLE `t_blog` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '自增id',
`title` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '博客标题',
`author` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '博客作者',
`content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL COMMENT '博客内容',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_blog
-- ----------------------------
INSERT INTO `t_blog` VALUES (1, 'Springboot 为什么这', 'bywind', '没错 Springboot ', '2021-12-08 01:44:29', '2021-12-19 01:44:34');
INSERT INTO `t_blog` VALUES (3, 'Springboot 中 Redis', 'bywind', 'Spring Boot', '2021-12-09 01:44:29', '2021-12-20 01:44:29');
INSERT INTO `t_blog` VALUES (4, 'Springboot 中如何优化', 'bywind', '12', '2021-12-10 01:44:29', '2021-12-21 01:44:29');
INSERT INTO `t_blog` VALUES (5, 'Springboot 消息队列', 'bywind', '12', '2021-12-11 01:44:29', '2021-12-22 01:44:29');
INSERT INTO `t_blog` VALUES (6, 'Docker Compose + Springboot', 'bywind', '12', '2021-12-12 01:44:29', '2021-12-23 01:44:29');
SET FOREIGN_KEY_CHECKS = 1;
- 运行
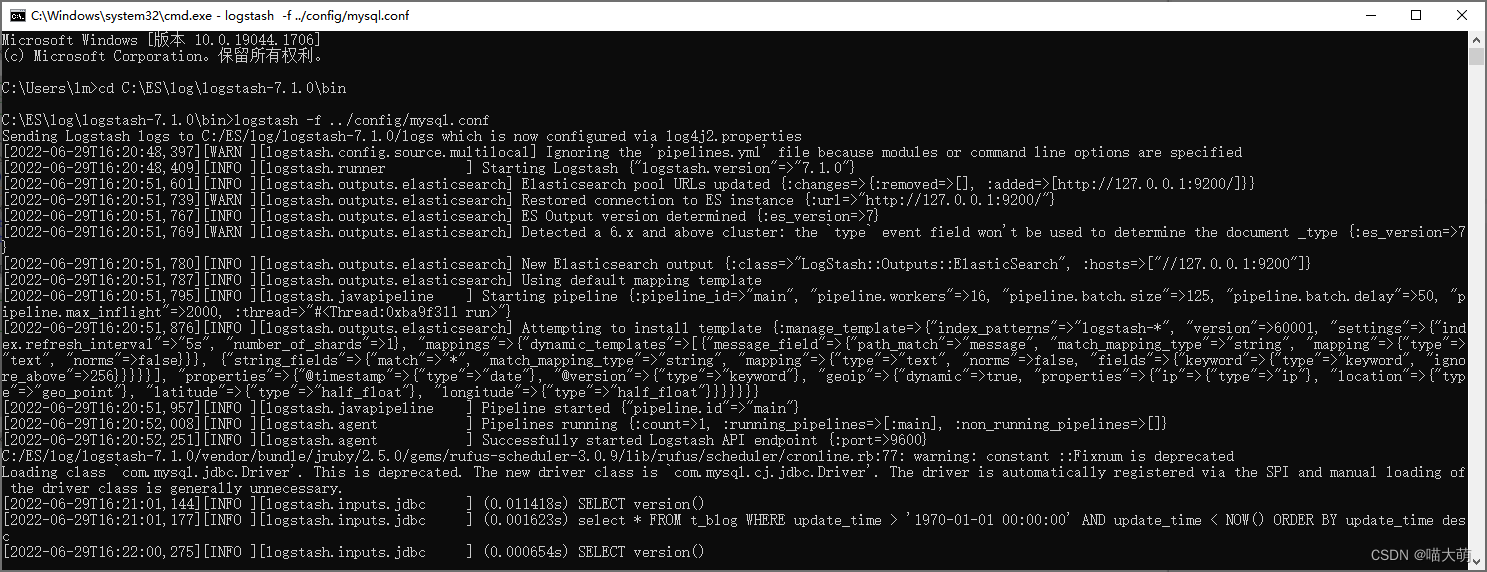
- 在kibana查看运行结果
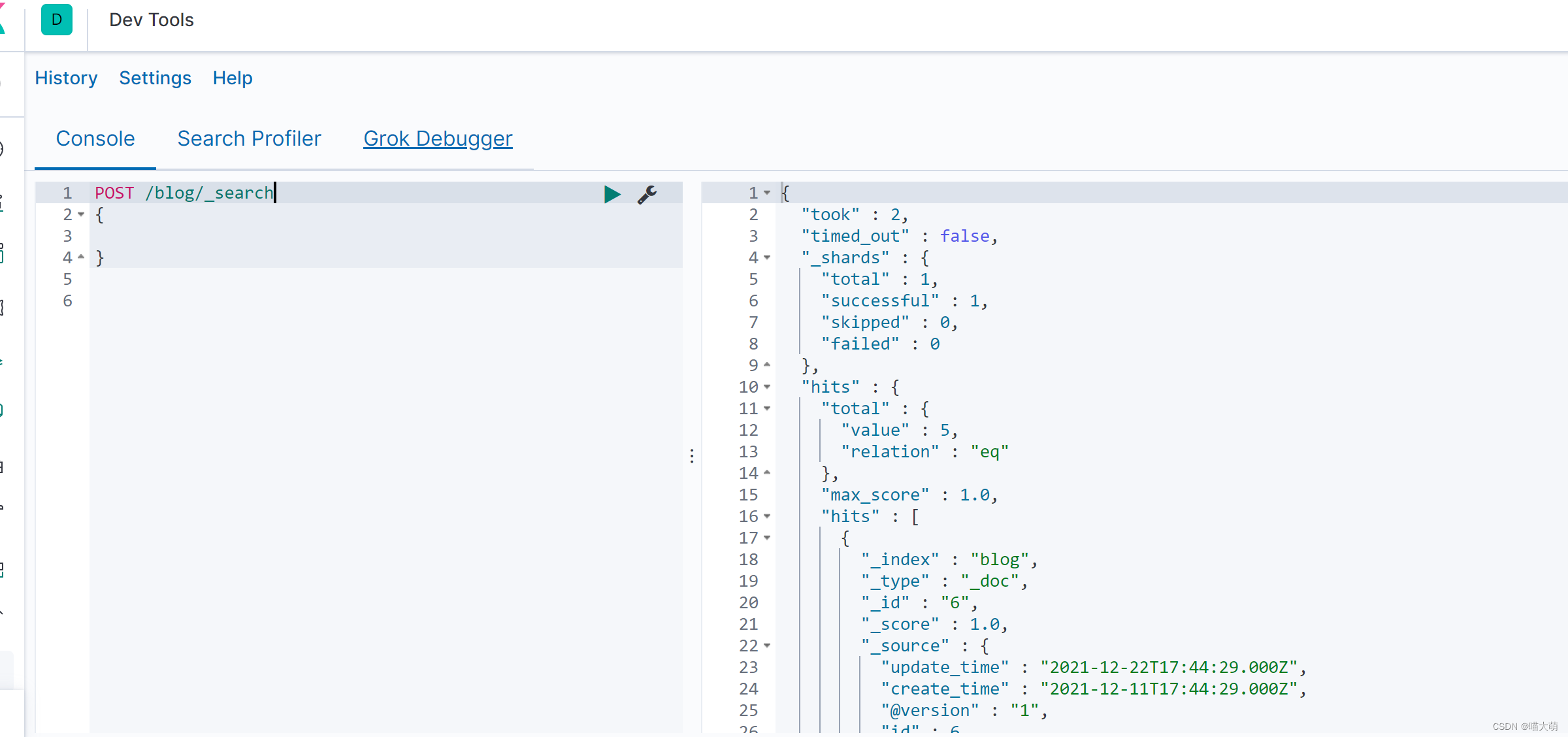
GET /blog/_stats
GET /blog/_search
ES中文分词器

IK分词器的安装和使用
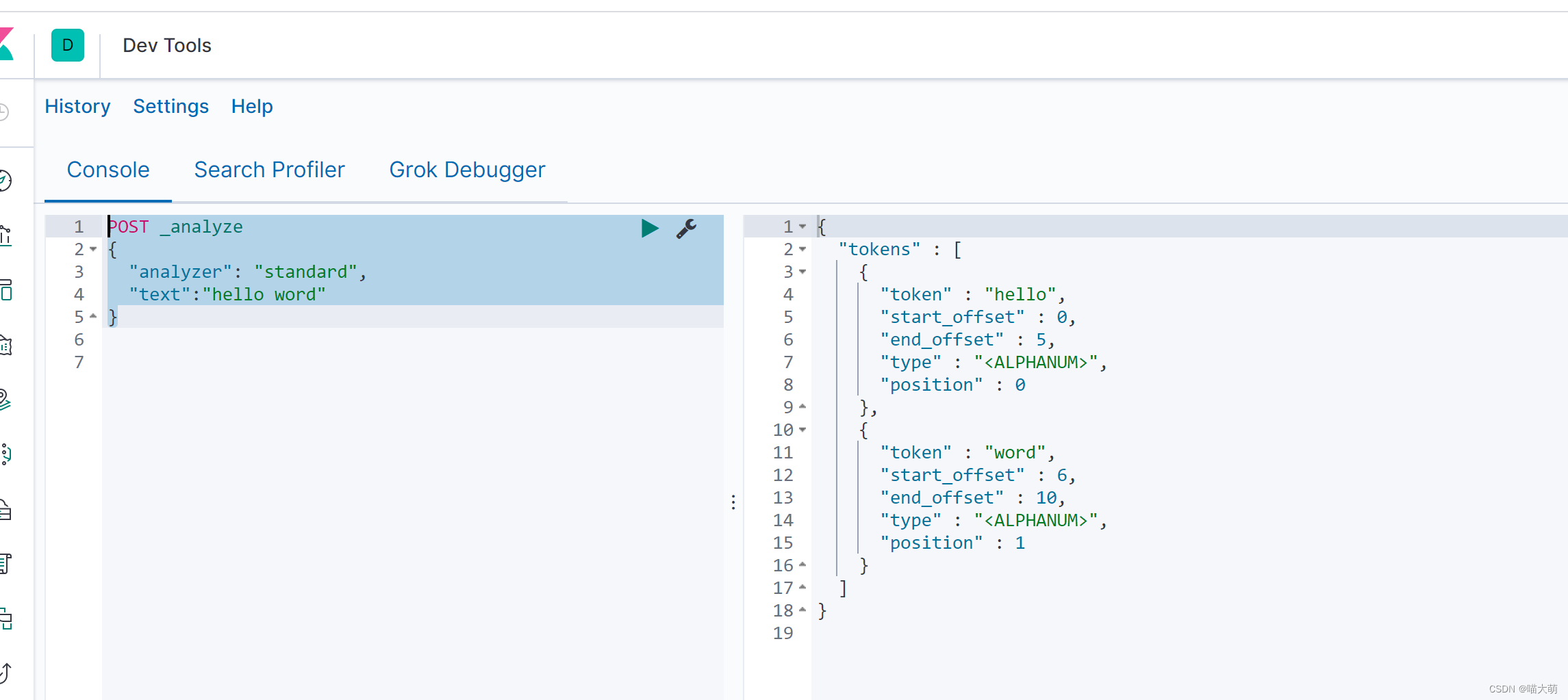
analyzer表示使用的哪种分词器,text为文本内容
POST _analyze
{
"analyzer": "standard",
"text":"hello word"
}
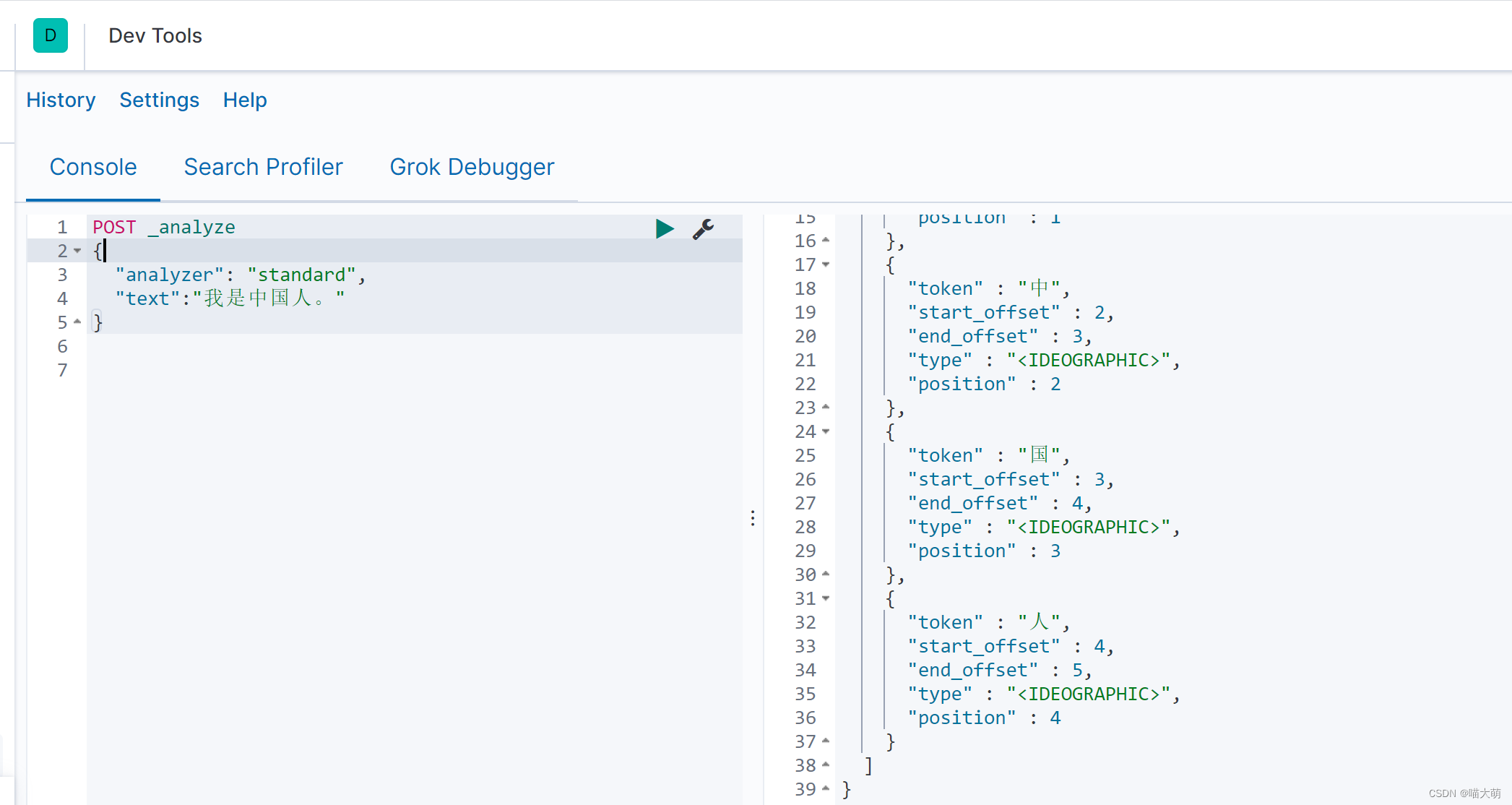
POST _analyze
{
"analyzer": "standard",
"text":"我是中国人"
}
IK分词器的下载
https://github.com/medcl/elasticsearch-analysis-ik/releases
IK分词器的安装
- 在
elasticsearch的plugins目录下创建ik文件夹 - 下载完成之后将解压目录复制到
ik文件夹下
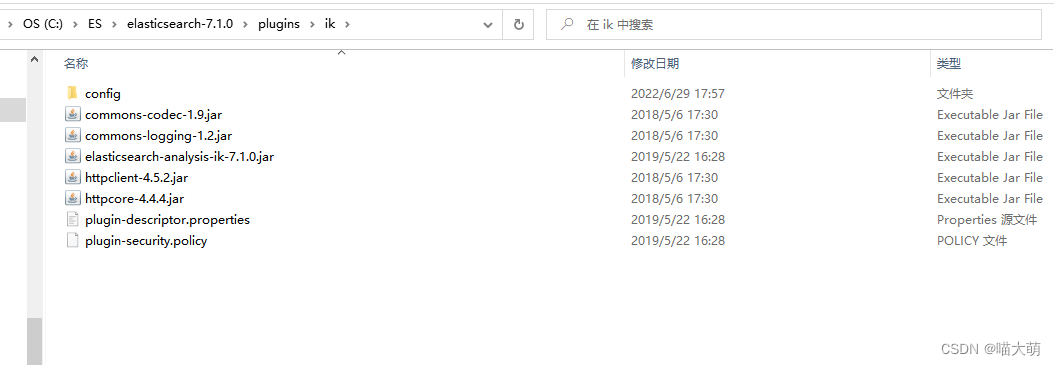
- 重启
elasticsearc和kibana,则可以识别中文汉字分词
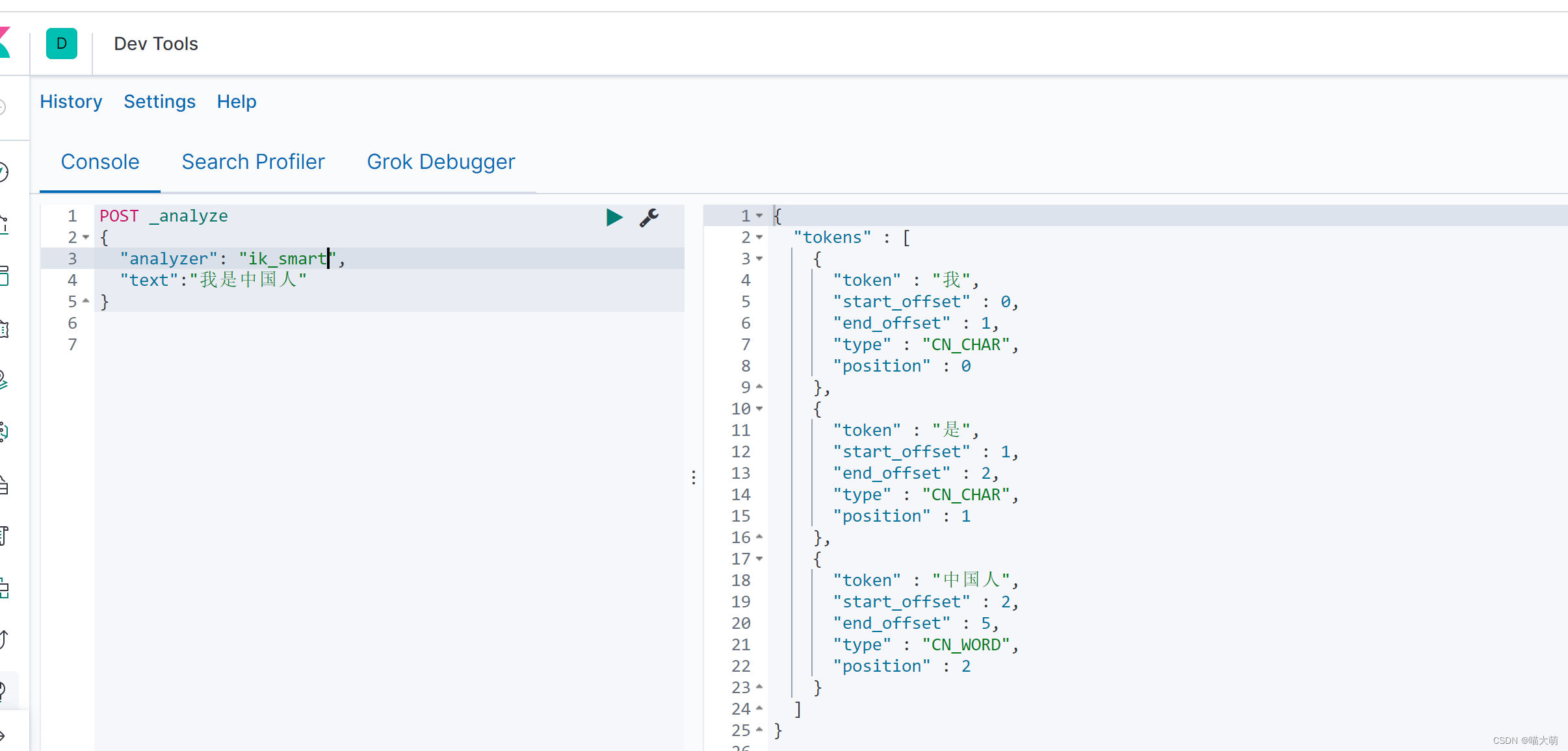
POST _analyze
{
"analyzer": "ik_smart",
"text":"我是中国人"
}
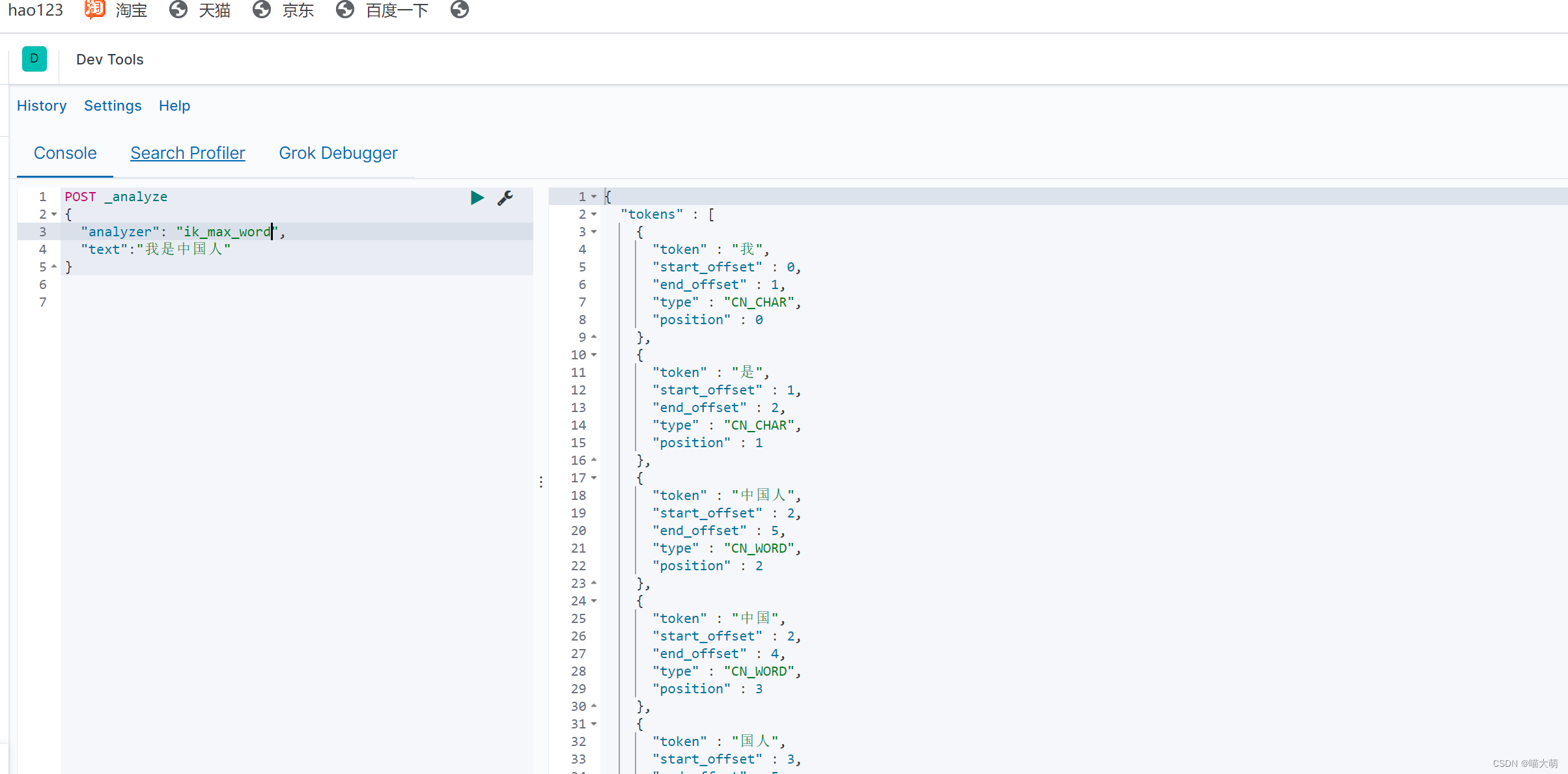
POST _analyze
{
"analyzer": "ik_max_word",
"text":"我是中国人"
}
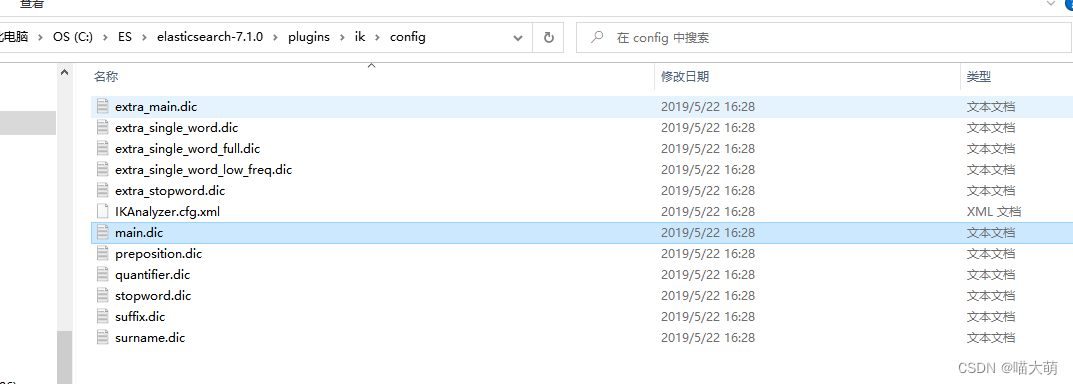
4. 其中config的main.dic为数据字典,如果发现不可分词,在数据字典加入相应词语即可。
SpringBoot集成ES
- 引入依赖
<!--spring data 操作es-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- SpringBoot中集成ES,ES需要根据MySQL实体类定义自己的实体类,例如
MySQL实体类
@Data
@Table(name = "t_blog")
@Entity
public class MysqlBlog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String title;
private String author;
@Column(columnDefinition = "mediumtext")
private String content;
private Date createTime;
private Date updateTime;
}
ES要定义与之对应的实体类
@Data
/**
* indexName对应的是数据库的database,即数据库名
* type默认_doc
* useServerConfiguration = true 使用线上的配置,当Spring创建索引时,Spring不会在创建的索引中设置以下设置:shards,replicas,refreshInterval和indexStoreType.这些设置将是Elasticsearch默认值(服务器配置)
* createIndex 在项目启动的时候不要创建索引,通常在 kibana 中已经配置过了
*
*/
@Document(indexName = "blog", type = "_doc", useServerConfiguration = true, createIndex = false)
public class EsBlog {
@Id
private Integer id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String author;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private Date createTime;
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private Date updateTime;
}
- 查询时,
MySQL通过调用dao层实现要查询的结果
List<MysqlBlog> mysqlBlogs = mysqlBlogRepository.queryBlog(param.getKeyword());
map.put("list", mysqlBlogs);
ES则具有自己的查询方法
BoolQueryBuilder builder = QueryBuilders.boolQuery();
builder.should(QueryBuilders.matchPhraseQuery("title", param.getKeyword()));
builder.should(QueryBuilders.matchPhraseQuery("content", param.getKeyword()));
String s = builder.toString();
log.info("s={}", s);
Page<EsBlog> search = (Page<EsBlog>) esBlogRepository.search(builder);
List<EsBlog> content = search.getContent();
map.put("list", content);
注意:BoolQueryBuilder 用于字符串构造,类似StringBuilder
title和content均为数据库字段,详见上面EsBlog
在kibana中查询如下,ES在代码中的查询可参考kibana查询语法。
POST /blog/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": "springboot"
}
},
{
"match_phrase": {
"content": "springboot"
}
}
]
}
}
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









