





Abstract(摘要)
\qquad
在为分类问题训练深度神经网络时,交叉熵损失(cross-entropy loss)和焦点损失(focal loss)是最常见的选择。然而,一般来说,一个好的损失函数可以采取更灵活的形式,并且应该为不同的任务和数据集量身定做。受函数如何通过泰勒扩展进行近似的启发,我们提出了一个简单的框架,名为PolyLoss,将损失函数看作是多项式函数的线性组合来设计。我们的PolyLoss允许根据目标任务和数据集轻松调整不同多项式的重要性,同时自然地将上述交叉熵损失和焦点损失作为特例。广泛的实验结果表明,PolyLoss中的最佳选择确实取决于任务和数据集。仅仅通过引入一个额外的超参数并增加一行代码,我们的Poly-1表述就在2D图像分类、实例分割、物体检测和3D物体检测任务上优于交叉熵损失和焦点损失,有时还能获得很大的优势。
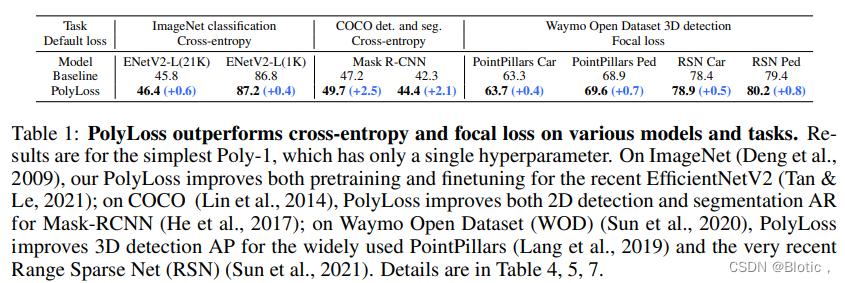
表1:PolyLoss在各种模型和任务上都优于交叉熵和焦点损失。结果是针对最简单的Poly-1,它只有一个超参数。在ImageNet(Deng等人,2009)上,我们的PolyLoss改善了最近的EfficientNetV2(Tan &Le,2021)的预训练和微调;在COCO(Lin等人,2014)上,PolyLoss改善了Mask-RCNN(He等人,2017)的2D检测和分割AR;在Waymo开放数据集(WOD)上(Sun等人,2020),PolyLoss 改善了广泛使用的PointPillars(Lang等人,2019)和最近的Range Sparse Net(RSN)(Sun等人,2021)的3D检测AP。详情见表4、5、7
1 Introduction(引言)
\qquad
损失函数在训练神经网络过程中很重要。原则上,损失函数可以是将预测和标签映射到标量的任何(可微分)函数。因此,由于其设计空间大的问题,设计一个好的损失函数通常是具有挑战性的,并且设计一个适用于不同任务和数据集的通用损失函数则更具挑战性,比如:L1/L2损失函数通常用于回归任务,但很少用于分类任务;focal loss通常用来缓解交叉熵函数在不平衡的目标检测数据集中产生过拟合问题,但它并没有应用到其他任务。最近的研究中还通过元学习、集成或合成来探索不同新的损失函数(Hajiabadi et al., 2017; Xu et al., 2018; Gonzalez & Miikkulainen, 2020b;a; Li et al., 2019)。
\qquad
在本文中,我们提出了 PolyLoss:一种用于理解和设计损失函数的新框架。我们的主要见解是将常用的分类损失函数 (例如交叉损失和焦点损失) 分解为一系列加权多项式基。他们分解的形式是
∑
j
=
1
∞
α
j
(
1
−
P
t
)
j
{\textstyle \sum_{j=1}^{\infty }} \alpha _{j}(1-P_{t} ) ^{j}
∑j=1∞αj(1−Pt)j,其中
α
j
∈
R
+
\alpha _{j}\in R^{+}
αj∈R+是多项式系数,
P
t
P_{t}
Pt是目标类标签的预测概率。每个多项式基数
(
1
−
P
t
)
j
(1-P_{t} ) ^{j}
(1−Pt)j由相应的多项式系数
α
j
\alpha _{j}
αj加权,这使我们能够轻松地针对不同的应用调整不同基数的重要性。当所有
α
j
=
1
j
\alpha _{j}=\frac{1}{j}
αj=j1时,我们的PolyLoss等效于常用的交叉熵损失,但是此系数分配可能不是最佳的。
\qquad
我们的研究表明,为了获得更好的结果,有必要针对不同的任务和数据集调整多项式系数
α
j
\alpha _{j}
αj。由于不可能调整无限多的
α
j
\alpha _{j}
αj,我们探索了具有小自由度的各种策略。令人惊讶的是,我们观察到简单地调整前几个多项式的单个多项式系数,我们表示为
L
P
o
l
y
−
1
L_{Poly-1}
LPoly−1,就足以实现对常用的交叉熵损失和焦点损失的明显改进。总的来说,我们的贡献可以总结为:
- Insights on common losses(对常见损失的见解): 我们重新考虑和重新设计损失函数并提出一个统一的框架,名为PolyLoss。该框架有助于将交叉熵损失和焦点损失解释为 PolyLoss 系列的两个特例(通过水平移动多项式系数),这在以前是不被公认的。这一新发现促使我们研究垂直调整多项式系数的新损失函数。如图1所示。
- New loss formulation(新的损失函数): 我们评估了垂直操纵多项式系数的不同方法,以简化超参数搜索空间。我们提出了一个简单有效的Poly-1损失公式,它只引入一个超参数和一行代码。
- New findings(新发现): 我们发现,尽管focal loss对许多检测任务有效,但对于不平衡的ImageNet-21K数据集而言是次优的。我们发现前几个多项式在训练过程中贡献了很大一部分梯度,并且其系数与预测置信度 P t P_{t} Pt相关。此外,我们还提供了一个直观的解释:说明如何利用这种相关性来设计出适合不平衡数据集的Polyloss。
- Extensive experiments(广泛的实验): 我们在不同的任务、模型和数据集上评估我们的PolyLoss。结果表明,PolyLoss在所有方面都始终如一地提高了性能,总结在表1中,其中包括最先进的分类EfficientNetV2和检测器RSN。
2 RELATED WORK(相关工作)
\qquad
交叉熵损失用于流行和当前最先进的模型,用于感知任务,例如分类,检测和语义分割(Tan & Le, 2021; He et al., 2017; Zoph et al.,
2020; Tao et al., 2020)。并提出了各种损失来改善交叉熵损失。与先前的工作不同,本文的目标是提供一个统一的框架,用于系统地设计更好的分类损失函数。
- 类别不平衡的损失 由于类别不平衡问题,在训练检测模型,尤其是单级检测器时会很困难。通常的方法例如困难样本挖掘和重新加权的方法来解决类别不平衡问题(Sung, 1996; Viola & Jones, 2001; Felzenszwalb et al., 2010; Shrivastava et al., 2016; Liu et al., 2016; Bulo et al., 2017)。focal loss作为其中一种方法,旨在通过关注困难样本来缓解类别不平衡问题,并用于训练最先进的 2D 和 3D 检测器(Lin et al., 2017; Tan et al., 2020; Du et al., 2020; Shi et al., 2020; Sun et al., 2021)。在我们的工作过程中,我们发现对于不平衡的ImageNet-21K数据集来说focal loss是次优的。使用 PolyLoss 框架,我们发现了一个更好的损失函数,它的作用与focal loss相反。我们进一步直观地理解了为什么使用 PolyLoss 框架给不同的、不平衡数据集设计不同的损失函数很重要。
- 标签噪声的鲁棒损失 另一个研究方向是设计对标签噪声具有鲁棒性的损失函数(Ghosh et al., 2015; 2017; Zhang & Sabuncu, 2018; Wang et al., 2019; Oksuz et al., 2020; Menon et al., 2019)。一种常用的方法是将噪声鲁棒损失函数 (例如平均绝对误差 (MAE)) 合并到交叉熵损失中。特别是,提出了泰勒交叉熵损失,通过扩展交叉熵损失中的 ( 1 − P t ) j (1 -P^{_{t}})^{j} (1−Pt)j多项式基来统一MAE和交叉熵损失(Feng et al., 2020)。通过截断高阶多项式,它们表明截断的交叉熵损失函数更接近MAE,这对于具有合成标签噪声的数据集上的标签噪声更具鲁棒性。相比之下,我们的PolyLoss提供了一个更通用的框架,通过操纵多项式系数为不同数据集设计损失函数,其中包括删除Feng et al. (2020)中提出的高阶多项式。我们在 4.1 小节中的实验显示了 Feng 等人提出的损失在干净的 ImageNet 数据集上的表现比交叉熵损失差。
- 学习损失函数 最近的几项研究展示了通过梯度下降或元学习在训练期间学习损失函数(Hajiabadi et al., 2017; Xu et al., 2018; Gonzalez & Miikkulainen, 2020a; Li et al., 2019; 2020)。值得注意的是,TaylorGLO利用cma-es优化了训练过程中损失函数的多元泰勒参数化和学习率时间表(Hansen& Ostermeier, 1996; Gonzalez & Miikkulainen, 2020b)。由于具有多项式阶的搜索空间尺度,本文证明了使用三阶参数化(8 个参数),学习到的损失函数表在10类分类问题上优于交叉熵损失。另一方面,我们的论文(图2a)显示,对于1000个类别分类任务,需要数百个多项式。这导致搜索空间过大。 我们提出的 Poly-1 公式减轻了大型搜索空间的问题,并且不依赖于先进的黑盒优化算法。 相反,我们展示了对一个超参数的简单网格搜索可以显著改善我们研究的所有任务。
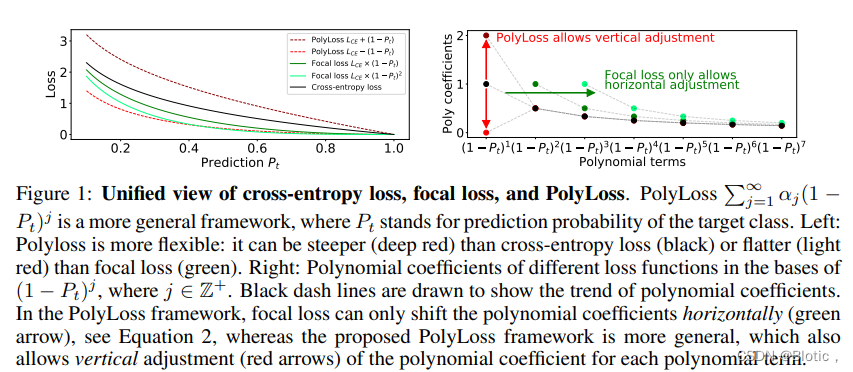
Figure 1:交叉熵损失、焦点损失和多损失的统一视图。Polyloss ∑ j = 1 ∞ α j ( 1 − P t ) j {\textstyle \sum_{j=1}^{\infty }} \alpha _{j}(1-P_{t} ) ^{j} ∑j=1∞αj(1−Pt)j是一个更概括的框架,其中 P t P_{t} Pt代表目标类的预测概率。左图:Polyloss更灵活:它可以比交叉熵损失(黑色)更陡峭(深红色)或比焦点损失(绿色)更平坦(浅红色)。右图:不同损失函数的多项式系数,其基数为 ( 1 − P t ) j (1-P_{t} ) ^{j} (1−Pt)j,其中 j ∈ Z + j\in Z ^{+} j∈Z+。绘制黑色虚线是为了显示多项式系数的趋势。在PolyLoss框架中,focal loss只能水平移动多项式系数(绿色箭头),见公式2,而提出的PolyLoss框架更为普遍,它还允许对每个多项式项的多项式系数进行垂直调整(红色箭头)。
3 POLYLOSS
\qquad
PolyLoss提供了一个框架,用于理解和改进常用的交叉熵损失和焦点损失,如图1所示。它的灵感来自以
(
1
−
P
t
)
j
(1 -P^{t})^{j}
(1−Pt)j为基础的交叉熵损失 (等式1) 和focal loss (等式2) 的泰勒展开:
L
C
E
=
−
l
o
g
(
P
t
)
=
∑
j
=
1
∞
1
j
(
1
−
P
t
)
j
=
(
1
−
P
t
)
+
1
2
(
1
−
P
t
)
2
.
.
.
(
1
)
L_{CE}=-log(P_t)=\sum_{j=1}^{\infty}\frac{1}{j}(1-P_t)^{j}=(1-P_t)+\frac{1}{2}(1-P_t)^{2}... \qquad(1)
LCE=−log(Pt)=j=1∑∞j1(1−Pt)j=(1−Pt)+21(1−Pt)2...(1)
L
F
L
=
−
(
1
−
P
t
)
γ
l
o
g
(
P
t
)
=
∑
j
=
1
∞
1
j
(
1
−
P
t
)
j
+
γ
=
(
1
−
P
t
)
1
+
γ
+
1
2
(
1
−
P
t
)
2
+
γ
(
2
)
L_{FL}=-(1-P_t)^{\gamma}log(P_t)=\sum_{j=1}^{\infty}\frac{1}{j}(1-P_t)^{j+\gamma }=(1-P_t)^{1+\gamma }+\frac{1}{2}(1-P_t)^{2+\gamma }\qquad(2)
LFL=−(1−Pt)γlog(Pt)=j=1∑∞j1(1−Pt)j+γ=(1−Pt)1+γ+21(1−Pt)2+γ(2)
其中,
P
t
P_t
Pt是对目标是真实类别的模型预测概率。
Cross-entropy loss as PolyLoss(作为PolyLoss的交叉熵损失) 使用梯度下降法来优化交叉熵损失,需要取得关于
P
t
P_{t}
Pt的梯度。在 PolyLoss 框架中,一个有趣的现象,系数
1
/
j
1/j
1/j 正好抵消了多项式基的
j
j
j 次方,见公式 1。因此,交叉熵损失的梯度只是多项式
(
1
−
P
t
)
j
\small(1 -P^{_{t}})^{j}
(1−Pt)j 的总和 ,如公式 3 所示。
−
d
L
C
E
d
P
t
=
∑
j
=
1
∞
(
1
−
P
t
)
j
−
1
=
1
+
(
1
−
P
t
)
+
(
1
−
P
t
)
2
.
.
.
(
3
)
-\frac{dL_{CE}}{dP_t}=\sum_{j=1}^{\infty }(1-P_t)^{j-1}=1+(1-P_t)+(1-P_t)^{2}...\qquad (3)
−dPtdLCE=j=1∑∞(1−Pt)j−1=1+(1−Pt)+(1−Pt)2...(3)
梯度展开式中的多项式项对
P
t
P_t
Pt具有不同的灵敏度。前导梯度项为1,它提供了恒定的梯度,而与
P
t
P_{t}
Pt的值无关。相反,当
j
≫
1
j\gg1
j≫1时,当
P
t
P_t
Pt接近1时,第
j
j
j个梯度项被强烈抑制。
Focal loss as PolyLoss(作为PolyLoss的焦点损失) 在PolyLoss框架中,公式2中,很明显,focalloss只是简单地将
j
j
j次幂移动调制因子
γ
\gamma
γ次幂。这相当于将所有多项式系数水平移动
γ
\gamma
γ,如图1所示。为了从梯度角度理解focalloss,我们采用焦点损失(等式 2)相对于
P
t
P_t
Pt 的梯度:
−
d
L
F
L
d
P
t
=
∑
j
=
1
∞
(
1
+
γ
j
)
(
1
−
P
t
)
j
+
γ
−
1
=
(
1
+
γ
)
(
1
−
P
t
)
γ
+
(
1
+
γ
2
)
(
1
−
P
t
)
1
+
γ
.
.
.
(
4
)
-\frac{dL_{FL}}{dP_t}=\sum_{j=1}^{\infty }(1+\frac{\gamma }{j} )(1-P_t)^{j+\gamma -1}=(1+\gamma )(1-P_t)^\gamma +(1+\frac{\gamma}{2} )(1-P_t)^{1+\gamma }...\qquad (4)
−dPtdLFL=j=1∑∞(1+jγ)(1−Pt)j+γ−1=(1+γ)(1−Pt)γ+(1+2γ)(1−Pt)1+γ...(4)
对于正值
γ
\gamma
γ,焦点损失的梯度删除了交叉熵损失中的恒定的前导梯度项1,见公式3。如上一段所述,这个恒定的梯度项使模型强调大多数类,因为它的梯度只是每个类的样本总数。通过将所有多项式项的幂移位
γ
\gamma
γ,第一项变为
(
1
−
P
t
)
γ
\small(1-P_{t})^{\gamma }
(1−Pt)γ,它被
γ
\gamma
γ的幂抑制,以避免过度拟合到已经自信的 (意味着
P
t
P_{t}
Pt接近1) 多数类。
Connection to regression and general form(与回归和一般形式的联系) 在 PolyLoss 框架中损失函数体现了与回归的直观联系。对于分类任务,
y
=
1
y=1
y=1是真实标签的有效概率,多项式基
(
1
−
P
t
)
j
\small (1 -Pt)^{j}
(1−Pt)j可以表示为
(
y
−
P
t
)
j
\small (y -Pt)^{j}
(y−Pt)j。因此,交叉熵损失和焦点损失都可以解释为预测和标签到第j次方之间距离的加权集合。然而,这些损失中的一个基本问题是:回归项前面的系数是最优的吗?
\qquad
一般来说,PolyLoss是
[
0
,
1
]
[0, 1]
[0,1]上的单调递减函数(为了简单起见,我们在本文中只考虑所有
α
j
≥
0
α_j≥0
αj≥0的情况。在
[
0
,
1
]
\small [0,1]
[0,1]上存在单调递减的函数,其中一些
α
j
α_j
αj为负数,例如
s
i
n
(
1
−
P
t
)
=
∑
j
=
0
∞
(
−
1
)
j
/
(
2
j
+
1
)
!
(
1
−
P
t
)
2
j
+
1
\small sin(1-P_t)=\sum_{j=0}^{\infty}(-1)^{j}/(2j+1)!(1-P_t)^{2j+1}
sin(1−Pt)=∑j=0∞(−1)j/(2j+1)!(1−Pt)2j+1) ,可以表示为
∑
j
=
1
α
j
(
1
−
P
t
)
j
\small \sum_{j=1}\alpha _{j}(1-P_{t})^{j}
∑j=1αj(1−Pt)j,并提供了一个灵活的框架来调整每个系数(为了确保序列收敛,我们要求
1
/
l
i
m
s
u
p
j
→
∞
∣
α
j
∣
j
≥
1
1/lim sup_{j\to \infty}\sqrt[j]{|\alpha_j|} \ge 1
1/limsupj→∞j∣αj∣≥1中
P
t
P_t
Pt在
(
0
,
1
]
(0,1]
(0,1]。对于
P
t
=
0
P_t=0
Pt=0,我们不要求逐点收敛;事实上,交叉熵和焦点损失都会达到
+
∞
+\infty
+∞。) 。PolyLoss可以推广到非整数
j
j
j,但为简单起见,本文仅关注整数幂
(
j
∈
Z
+
)
(j ∈ Z^{+})
(j∈Z+)。在下一节中,我们将研究通过操纵
α
j
\alpha_{j}
αj在 PolyLoss 框架中设计更好的损失函数的几种策略。

表2:比较 PolyLoss 框架中的不同损失。之前的工作中提出的放弃高阶多项式,截断了所有的高阶 ( N + 1 → ∞ ) (N + 1 → ∞) (N+1→∞)多项式项。我们提出了Poly-N损失,它扰乱了前N个多项式系数。Poly-1是最终的损失表述,它进一步简化了Poly-N,只需要对一个超参数进行简单的网格搜索。与交叉熵损失相比,其差异以红色标出。
4 UNDERSTANDING THE EFFECT OF POLYNOMIAL COEFFICIENTS(了解多项式系数的影响)
\qquad
在上一节中,我们建立了PolyLoss框架,并证明了交叉熵损失和焦点损失只是对应于不同的多项式系数,其中焦点损失水平移动了交叉熵损失的多项式系数。
\qquad
在本节中,我们提出了制定的最终损失函数—Poly-1。如图1所示我们深入研究了垂直调整多项式系数如何影响训练。具体来说,我们探讨了分配多项式系数的三种不同策略:放弃高阶项;调整多个主导多项式系数;调整第一个多项式系数,如上表2所示。我们发现,调整第一多项式系数(Poly-1公式)可以获得最大增益,同时需要最小的代码更改和超参数调整。
\qquad
在这些探索中,我们尝试了1000类ImageNet(Deng et al., 2009) 分类。我们将其缩写为ImageNet-1K,以区别于包含21K类的完整版本。我们使用ResNet-50(He et al., 2016)及其训练超参数,不做修改。
4.1 LDrop: REVISITING DROPPING HIGHER-ORDER POLYNOMIAL TERMS(LDrop:重新审视丢弃高阶多项式的问题)
\qquad 以前的研究(Feng et al., 2020; Gonzalez & Miikkulainen, 2020b) 已经表明,删除高阶多项式并调整主导多项式可以提高模型的鲁棒性和性能。我们采用Feng et al. (2020)中提到的相同的损失公式 L D r o p = ∑ j = 1 N 1 / j ( 1 − P t ) j \small L_{Drop} =\sum_{j=1}^{N}1/j(1-P_{t})^{j} LDrop=∑j=1N1/j(1−Pt)j,并将它们的性能与 ImageNet-1K 上的基础交叉熵损失进行比较。如图2a所示,我们需要总结 600 多个多项式项来匹配交叉熵损失的准确性。值得注意的是,去除高阶多项式不能简单地解释为调整学习率。为了验证这一点,图 2b 比较了不同学习率和不同截止值的性能:无论我们将学习率从原来的0.1增加或减少,准确性都会变差。其他的超参数调整在section 9中显示。
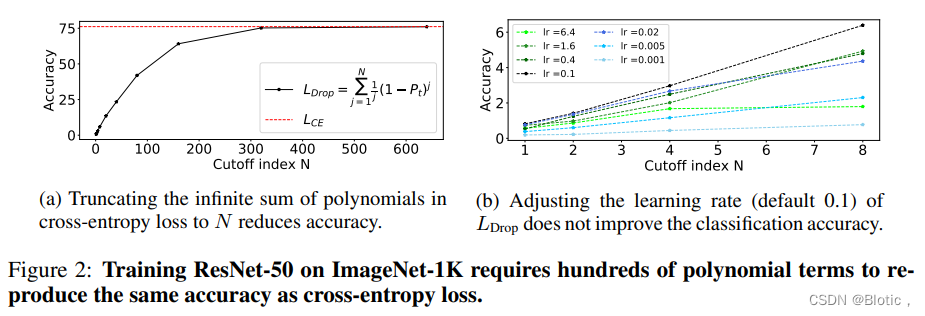
(a) 将交叉熵损失中的多项式的无限之和截断至N,可降低精度(b)调整LDrop的学习率(默认为0.1)并不能提高分类精度。
\qquad 为了理解为什么高阶项很重要,我们考虑从交叉熵损失中去除前N个多项式项后的残差和: R N = L C E − L D r o p = ∑ j = N + 1 ∞ 1 / j ( 1 − P t ) j \small R_{N}=L_{CE}-L_{Drop}=\sum_{j=N+1}^{\infty}1/j(1-P_{t})^{j} RN=LCE−LDrop=∑j=N+1∞1/j(1−Pt)j
定理1. 对于任何小的
ζ
>
0
,
δ
>
0
\zeta > 0,\delta >0
ζ>0,δ>0,如果
N
>
log
1
−
δ
(
ζ
⋅
δ
)
N>\log_{1-\delta }{(\zeta\cdot \delta)}
N>log1−δ(ζ⋅δ),那么对于任意
p
∈
[
δ
,
1
]
p\in[\delta ,1]
p∈[δ,1],
∣
R
N
(
p
)
∣
<
ζ
|R_N(p)|<\zeta
∣RN(p)∣<ζ和
∣
R
N
′
(
p
)
∣
<
ζ
|R'_N(p)|<\zeta
∣RN′(p)∣<ζ 。(证明见第7节)
\qquad
因此,从
[
δ
,
1
]
上
的
[\delta,1]上的
[δ,1]上的损失和损失导数的角度来看,需要取一个大的 N 以确保
L
D
r
o
p
\small L _{Drop}
LDrop 一致地接近(uniformly close)
L
C
E
\small L _{CE}
LCE。对于固定的
ζ
\small \zeta
ζ,随着
δ
\small\delta
δ接近 0,
N
\small N
N 迅速增长。 我们的实验结果与定理一致。 高阶
(
j
>
N
+
1
)
(j > N + 1)
(j>N+1) 多项式在训练的早期阶段发挥重要作用,此时
P
t
\small P_t
Pt 通常接近于零。例如,当
P
t
∼
0.001
\small P_t ∼ 0.001
Pt∼0.001 时,根据公式3,第 500 项的梯度系数为 0.999499 ∼ 0.6,这是相当大的。 与上述先前的工作不同,我们的结果表明,我们不能通过排除高阶多项式来轻易减少多项式系数
α
j
\small \alpha_j
αj 的数量。
\qquad
在 PolyLoss 框架,丢弃高阶多项式相当于将所有高阶
(
j
>
N
+
1
)
\small (j > N+1)
(j>N+1) 多项式系数
α
j
\small \alpha_j
αj 垂直推至零。 由于简单地将系数设置为零对于训练 ImageNet-1K 不是最理想的,因此在下面的章节中,我们将研究如何在 PolyLoss 框架中除了将多项式系数设置为零之外,还能对其进行操作。 特别是,我们的目标是提出一个简单有效的损失函数,需要最少的调整。
4.2 L P O L Y − N L_{POLY-N} LPOLY−N: PERTURBING LEADING POLYNOMIAL COEFFICIENTS(扰乱主导多项式系数)
\qquad
在本文中,我们提出了一种在 PolyLoss 框架中设计新损失函数的替代方法,其中我们调整了每个多项式的系数。 一般来说,有无数个多项式系数
α
j
\alpha_j
αj需要调整。 因此,优化最一般的损失是不可行的:
L
P
o
l
y
=
α
(
1
−
P
t
)
+
α
2
(
1
−
P
t
)
2
+
.
.
.
+
α
N
(
1
−
P
t
)
N
+
.
.
.
=
∑
j
=
1
∞
α
j
(
1
−
P
t
)
j
(
5
)
L_{Poly}=\alpha (1-P_t)+\alpha_2(1-P_t)^{2}+...+\alpha_N(1-P_t)^{N}+...=\sum_{j=1}^{\infty}\alpha _j(1-P_t)^{j} \qquad(5)
LPoly=α(1−Pt)+α2(1−Pt)2+...+αN(1−Pt)N+...=j=1∑∞αj(1−Pt)j(5)
\qquad
上一节(第4.1小节)表明,在训练中需要数百个多项式才能在ImageNet-1K分类等任务中表现出色。如果我们天真地将公式5中的无穷和截断为前几百个项,那么调整这么多多项式的系数仍然会导致极大的搜索空间。此外,集体调整许多系数也不会优于交叉熵损失,详情见section 10。
\qquad
为了应对这一挑战,我们建议扰乱(perturb)交叉熵损失中的主导多项式系数,同时保持其余部分不变。我们将所提出的损失公式表示为 Poly-N,其中 N 代表将被调整的主导系数的数量。
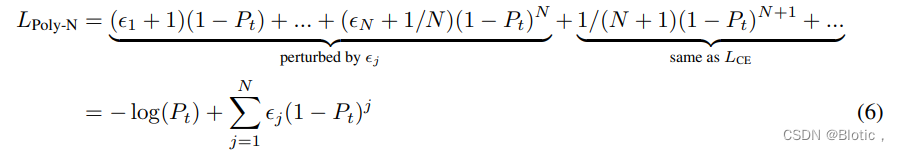
\qquad
在这里,我们将交叉损失的第j个多项式系数
1
/
j
\small 1/j
1/j替换为
1
/
j
+
ϵ
j
1/j+\epsilon _j
1/j+ϵj,其中
ϵ
j
∈
[
−
1
/
j
,
∞
]
\small \epsilon _j\in [-1/j,\infty]
ϵj∈[−1/j,∞]是扰动项(perturbation term)。这使我们可以精确定位前
N
\small N
N个多项式,而无需担心无限多个高阶
(
j
>
N
+
1
)
\small (j > N +1)
(j>N+1) 系数,如公式5所示。
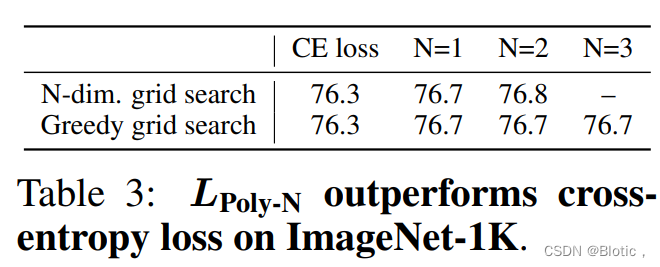
表3显示
L
P
o
l
y
−
N
L_{Poly-N}
LPoly−N优于基础交叉熵损失精度。我们在
L
P
o
l
y
−
N
L_{Poly-N}
LPoly−N中探索了
j
j
j的
N
\small N
N维网格搜索和贪婪的网格搜索,最高可达
N
=
3
\small N=3
N=3,并发现简单地调整第一个多项式的系数
(
N
=
1
)
\small (N=1)
(N=1)可获得更好的分类精度。进行二维网格搜索
(
N
=
2
)
\small (N=2)
(N=2)可以进一步提高准确性。然而,与只调整第一个多项式(+0.4)相比,额外的收益很小(+0.1)。
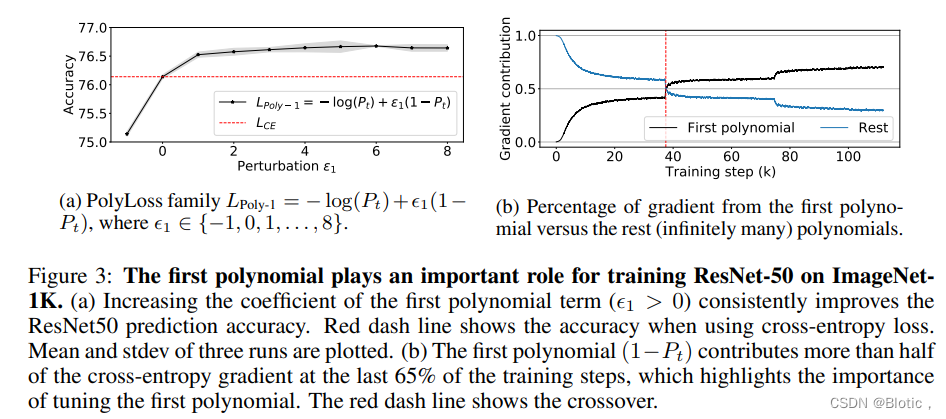
图3:第一个多项式对于在ImageNet-1K上训练ResNet-50起着重要的作用。(a)增加第一个多项式项的系数 ( ϵ j > 0 ) (\epsilon _j>0) (ϵj>0)可以持续提高ResNet50的预测准确率。红色虚线表示使用交叉熵损失时的准确性。绘制出三次运行的平均值和stdev。(b) 第一个多项式 ( 1 − P t ) (1-P_t) (1−Pt)在最后65%的训练步骤中贡献了一半以上的交叉熵梯度,这突出了调整第一个多项式的重要性。红色虚线表示交叉处。
4.3 L P o l y − 1 L_{Poly-1} LPoly−1: SIMPLE AND EFFECTIVE( L P o l y − 1 L_{Poly-1} LPoly−1:简单有效)
\qquad
如上一节所示,我们发现调整第一个多项式项会导致最显著的增益。在本节中,我们将进一步简化 Poly-N 公式并重点评估 Poly-1,其中仅修改了交叉熵损失中的第一个多项式系数。
L
P
o
l
y
−
1
=
(
1
+
ϵ
1
)
(
1
−
P
t
)
+
1
/
2
(
1
−
P
t
)
2
+
.
.
.
=
−
l
o
g
(
P
t
)
+
ϵ
1
(
1
−
P
t
)
(
7
)
L_{Poly-1}=(1+\epsilon _1)(1-P_t)+1/2(1-P_t)^{2}+...=-log(P_t)+\epsilon _1(1-P_t)\qquad (7)
LPoly−1=(1+ϵ1)(1−Pt)+1/2(1−Pt)2+...=−log(Pt)+ϵ1(1−Pt)(7)
\qquad
我们研究了不同的第一项缩放对精度的影响,并观察到增加第一个多项式系数可以系统地提高 ResNet-50 的精度,如图 3a 所示。该结果表明,就多项式系数值而言,交叉熵损失是次优的,并且增加第一个多项式系数会导致持续改进,这与其他训练技术相当。(section 11)
\qquad
图3b示出了在大部分时间内,主导多项式在训练期间贡献了超过一半的交叉熵梯度,这突出了第一多项式项
(
1
−
P
t
)
(1 − P_t)
(1−Pt) 与其余无限多项相比的重要性。因此,在本文的其余部分中,我们采用
L
P
o
l
y
−
1
L_{Poly-1}
LPoly−1的形式,主要侧重于调整主导多项式系数(leading polynomial
coefficient)。从公式7中可以明显看出,它仅通过一行代码 (在交叉熵损失之上添加
ϵ
1
(
1
−
P
t
)
\epsilon _{1}(1-P_t)
ϵ1(1−Pt)项) 来修改原始损失实现。
\qquad
请注意,所有训练超参数都针对交叉熵损失进行了优化。即使这样,对Poly-1公式中的第一个多项式系数进行简单的网格搜索也可以显著提高分类精度。我们发现为
L
P
o
l
y
−
1
L_{Poly-1}
LPoly−1优化其他超参数会导致更高的准确性,并在section 8中展示更多细节。
5 EXPERIMENTAL RESULTS(实验结果)
\qquad
在本节中,我们将我们的PolyLoss与常用的交叉熵损失和焦距
在各种任务、模型和数据集上进行比较。在下面的实验中,我们采用公共资源库中默认的训练超参数,不做任何调整。然而,Poly-1 公式以简单的网格搜索为代价,导致了优于默认损失函数的一致优势。
5.1 L P O L Y − 1 L_{POLY-1} LPOLY−1 IMPROVES 2D IMAGE CLASSIFICATION ON IMAGENET( L P o l y − 1 L_{Poly-1} LPoly−1改善了imagenet上的2维图像分类)
\qquad
图像分类是计算机视觉中的一个基本问题,并且图像分类的进展带动了许多相关计算机视觉任务的进展。在网络结构方面,除了section 4已经使用的ResNet-50之外,我们使用最先进的EfficientNetV2(Tan & Le, 2021)进行试验。除了用我们的PolyLoss LPoly-1代替原来的交叉熵损失,我们使用了(Tan & Le, 2021)中的ImageNet设置,并取不同的
ϵ
1
\epsilon _1
ϵ1值。在数据集方面,除了第4节已经使用的ImageNet-1K数据集外,我们还考虑了ImageNet-21K,它有大约1300万张训练图像和21841个类。我们将同时研究ImageNet-21K的预训练结果和ImageNet-1K的微调结果。
\qquad
在ImageNet-21K上预训练EfficientNetV2-L,然后在ImageNet-1K上进行微调,可以提高分类精度(Tan & Le, 2021)。在这里,我们遵循Tan & Le (2021)报告的相同的预训练和微调计划,不做任何修改,但用
L
P
o
l
y
−
1
=
−
l
o
g
(
P
t
)
+
ϵ
1
(
1
−
P
t
)
L_{Poly-1}=-log(P_t)+\epsilon _1(1-P_t)
LPoly−1=−log(Pt)+ϵ1(1−Pt)取代交叉熵损失。我们从训练集中保留25,000张图像作为最小值(minival)来寻找最佳的
ϵ
1
\epsilon _1
ϵ1。
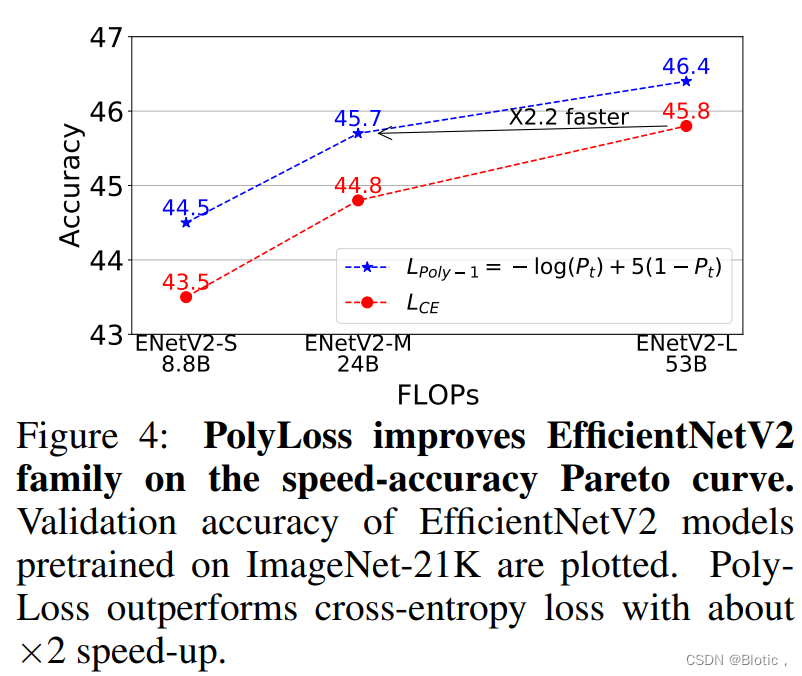
图4:PolyLoss在速度-精度Pareto曲线上改善了EfficientNetV2系列。图中显示了在ImageNet-21K上预训练的EfficientNetV2模型的验证精度。PolyLoss比交叉熵损失有大约 ×2的速度提升。
\qquad
Pretraining on ImageNet-21K(对ImageNet-21K的预训练) 图4突出了在ImageNet21K数据集上进行模型预训练时,使用定制的损失函数的重要性。在不改变其他默认超参数的情况下,在
L
P
o
l
y
−
1
L_{Poly-1}
LPoly−1中对
ϵ
1
∈
{
0
,
1
,
2
,
.
.
.
7
}
\epsilon _1\in \{0,1,2,...7\}
ϵ1∈{0,1,2,...7}进行简单的网格搜索,可以使所有不同规模的SOTA EfficientNetV2模型的准确率提高1%左右。使用更好的损失函数所带来的精度提高几乎与扩大模型结构(S到M和M到L)所带来的提高相匹配。
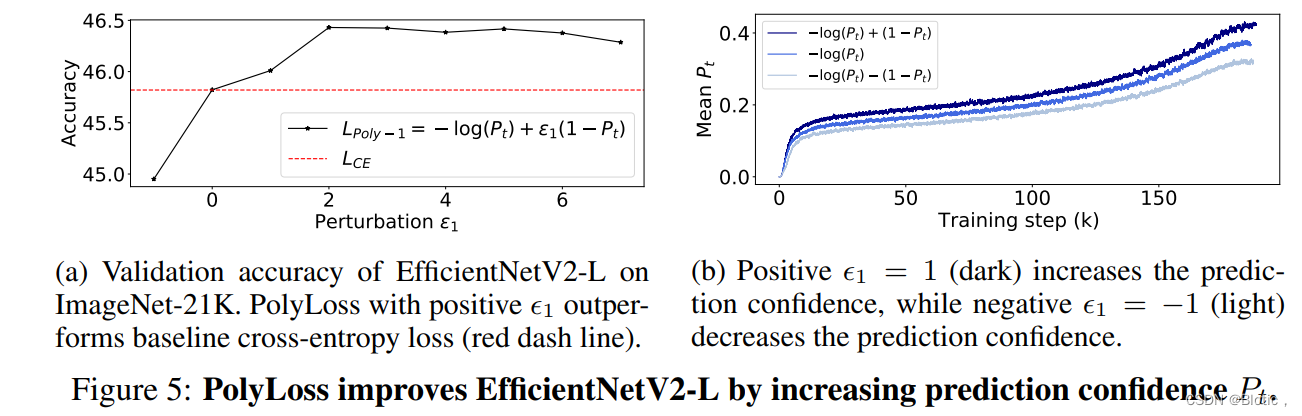
\qquad
令人惊讶的是,见图5a,增加主导多项式系数的权重可以提高在ImageNet-21K上的预训练精度(+0.6),而减少它则会降低精度(-0.9)。设置
ϵ
1
=
−
1
\epsilon _1=-1
ϵ1=−1可以截断交叉熵损失(公式1)中的主导多项式项,这类似于有一个
γ
=
1
\gamma =1
γ=1的焦点损失(公式2)。然而,相反的变化,即
ϵ
1
>
0
\epsilon _1>0
ϵ1>0,提高了不平衡的ImageNet-21K的准确性。
\qquad
Fine tuning on ImageNet-1K(在ImageNet-1K上进行微调) 在ImageNet-21K上进行预训练后,我们利用EfficientNetV2-L检查点在ImageNet-1K上进行微调,除了用Poly-1公式取代原来的交叉熵损失外,其他步骤与Tan & Le(2021)相同。PolyLoss将微调精度提高了0.4%,将ImageNet-1K的top-1精度从86.8%推进到87.2%。

5.2 L P O L Y − 1 L_{POLY-1} LPOLY−1 IMPROVES 2D INSTANCE SEGMENTATION AND OBJECT DETECTION ON COCO( L P O L Y − 1 L_{POLY-1} LPOLY−1改善了Coco上的2d实例分割和物体检测)
5.3 L P O L Y − 1 L_{POLY-1} LPOLY−1 IMPROVES 3D OBJECT DETECTION ON WAYMO OPEN DATASET( L P O L Y − 1 L_{POLY-1} LPOLY−1提高了Waymo开放数据集的3D物体检测能力)
6 CONCLUSION
\qquad
在本文中,我们提出了 PolyLoss 框架,它为分类问题的常见损失函数提供了统一的视图。我们认识到,在多项式展开下,与交叉熵损失相比,焦点损失是多项式系数的水平偏移。这种新的见解促使我们探索另一个维度,即垂直修改多项式系数。
\qquad
我们的 PolyLoss 框架提供了通过调整多项式系数来更改损失函数形状的灵活方法。在这个框架中,我们提出了一种简单有效的 Poly-1 公式。通过简单地用一个额外的超参数
ϵ
1
\epsilon _1
ϵ1调整领先的多项式系数,我们展示了我们简单的 Poly-1 改进了多个任务和数据集的各种模型。我们希望 Poly-1 公式的简单性(额外的一行代码)和有效性将导致更多分类应用的采用,而不是我们设法探索的分类。
\qquad
更重要的是,我们的工作强调了常见损失函数的局限性,即使在成熟的最先进模型上,简单的修改也可能带来改进。我们希望这些发现能鼓励人们在常用的交叉熵和焦点损失以及本工作中提出的最简单的Poly-1损失之外探索和重新思考损失函数的设计。
REPRODUCIBILITY STATEMENT(可重复性申明)
\qquad
我们的实验是基于公共数据集和开放源代码库,如脚注3-6所示。我们不调整任何默认的训练超参数,只修改损失函数,如表2-7所示。所提出的最终公式
L
P
o
l
y
−
1
L_{Poly-1}
LPoly−1需要修改一行代码。
\qquad
下面是带有softmax激活的
L
C
E
P
o
l
y
−
1
L_{CE}^{Poly-1}
LCEPoly−1 的代码示例。

\qquad
下面是带有α标签平滑
L
C
E
P
o
l
y
−
1
L_{CE}^{Poly-1}
LCEPoly−1 的示例代码。

\qquad
下面是带有sigmoid激活的
L
F
L
P
o
l
y
−
1
L_{FL}^{Poly-1}
LFLPoly−1 的代码示例。

\qquad
下面是带有α标签平滑
L
F
L
P
o
l
y
−
1
L_{FL}^{Poly-1}
LFLPoly−1 与的示例代码。

SUPPLEMENTARY MATERIAL(补充材料)
7 PROOF OF THEOREM 1(证明定理1)
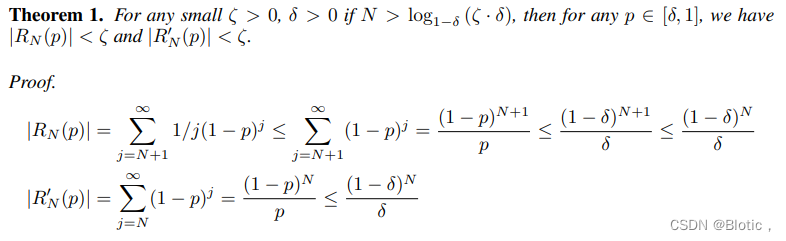
8 ADJUSTING OTHER TRAINING HYPERPARAMETERS LEADS TO HIGHER GAIN.(调整其他训练超参数会导致更高的增益。)
\qquad
主文中显示的所有实验都是基于基础损失函数的超参数优化,这实际上使PolyLoss处于不利地位。这里我们用ResNet50的权重衰减率作为一个例子。默认的权重衰减
(
l
e
−
4
)
(le-4)
(le−4)是针对交叉熵损失优化的。调整衰减率可能会降低交叉熵损失的模型性能,但会导致PolyLoss的收益高得多(+0.8%),这比使用交叉熵损失训练的最佳精度(76.3%)更好。

\qquad
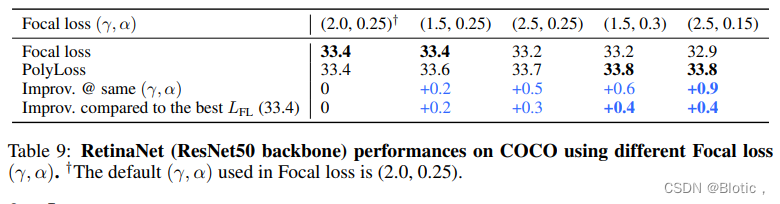
在此,我们增加了使用RetinaNet对COCO检测的额外消融研究。Focal loss的最佳γ和α平衡值是(2.0,0.25)(Lin等人,2017)。由于所有的超参数都是相对于最优的(γ,α)值进行优化的,所以我们观察到在调整主导多项式项时没有任何改进。我们怀疑检测AP是在超参数的 “局部最大值”。通过调整(γ,α)值,我们显示PolyLoss一直优于最好的Focal Loss AP(33.4),即只调整γ值(第3,4列)或同时调整γ和α值(第5,6列)。
9 L D R O P L_{DROP} LDROP WITH MORE HYPERPARAMETER TUNING(带有更多超参数调整的 L D R O P L_{DROP} LDROP)
\qquad
对于
L
D
r
o
p
(
N
=
2
)
\small L_{Drop}(N=2)
LDrop(N=2),除了调整学习率,我们还进一步调整了第二个多项式的系数
(
α
)
(\alpha)
(α)。类似于之前的工作(Gonzalez & Miikkulainen, 2020b),和权重衰减。
L
D
r
o
p
∗
=
(
1
−
P
t
)
+
α
(
1
−
P
t
)
2
(
8
)
L_{Drop^{*}} = (1-P_t)+\alpha (1-P_t)^{2} \qquad(8)
LDrop∗=(1−Pt)+α(1−Pt)2(8)
\qquad
与Feng et al. (2020)不同,在放弃所有高阶多项式后,α=0.5,我们发现最佳α=8,而最佳学习率与默认设置(0.1)相同。仅此一项就将准确率提高到70.9,这表明简单地放弃多项式是不够的,调整多项式系数是关键。进一步调整权重衰减导致模型质量的提高不到0.1%。
\qquad
与之前的工作相比(Gonzalez & Miikkulainen, 2020b; Feng et al., 2020),Poly-1更加有效,并且只包含一个超参数。与
L
D
r
o
p
∗
L_{Drop^{*}}
LDrop∗相比,调整Poly-1的权重衰减进一步提高了准确性,同时拥有更少的超参数,如表10所示。

10 COLLECTIVELY TUNING MULTIPLE POLYNOMIAL COEFFICIENTS(集体调谐多个多项式系数)
\qquad
除了调整单个多项式系数外,在这一节中,我们探索集体调整PolyLoss框架中的多个多项式系数。特别是,我们将原始交叉熵损失中的系数从1/j(公式1)改为指数衰减。这里,我们定义
L
e
x
p
=
∑
j
=
1
2
N
e
−
(
j
−
1
)
/
N
(
1
−
P
t
)
j
(
9
)
L_{exp}=\sum_{j=1}^{2N}e^{-(j-1)/N}(1-P_t)^{j} \qquad(9)
Lexp=j=1∑2Ne−(j−1)/N(1−Pt)j(9)
其中我们在两倍的衰减因子N处切断了无限和。我们对
N
∈
{
5
,
20
,
80
,
320
}
N\in\{5, 20, 80, 320\}
N∈{5,20,80,320}和学习率
l
e
a
r
n
i
n
g
r
a
t
e
∈
{
0.1
,
0.4
,
1.6
,
6.4
}
learning rate\in\{0.1, 0.4, 1.6, 6.4\}
learningrate∈{0.1,0.4,1.6,6.4}进行二维网格搜索。最好的精度是72.3,其中N=80,学习率=1.6,见表11。
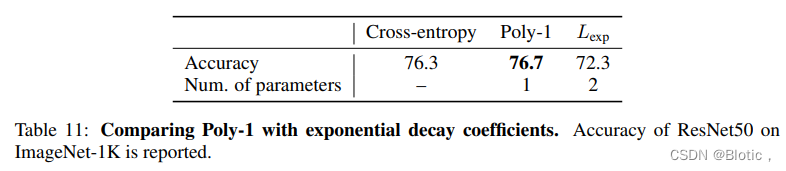
虽然Poly-1比使用
L
e
x
p
L_{exp}
Lexp好,但除了使用指数衰减,还有很多可能性。我们相信了解集体调整多个系数如何影响训练是一个重要的课题。
11 COMPARING TO OTHER TRAINING TECHNIQUES(与其他训练技术的比较)
\qquad
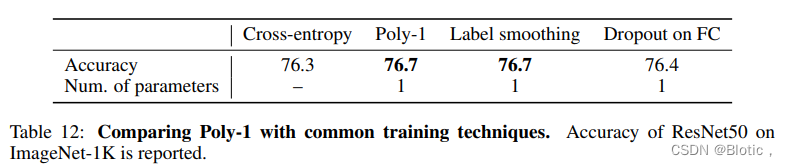
正如最近的工作(He et al., 2019; Bello et al., 2021; Wightman et al., 2021)所示,虽然独立的新型训练技术经常导致低于1%的改进,但将它们结合起来可以带来显著的整体改进。为了说明问题,Poly-1实现了与其他常用的训练技术类似的改进,如标签平滑和FC上的dropout ,见表12
\qquad
\qquad
\qquad
\qquad















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









