






引言:我们在使用计算机的过程中,经常会在计算机自身的硬件配置中看到“GPU”或者“图形处理器”,等字样,“GPU”是什么?有什么作用?本文将围绕GPU展开一系列分析。
摘要:图形处理单元,即GPU(graphic processing unit)作为电子计算机中的重要结构,在冯式计算机结构中属于运算器与控制器。其结构较为复杂,有显存,流处理器等单位。GPU的主要渲染流程之一是通过着色器管线进行渲染,且GPU本身具备很广泛而强大的功能,基于其的相关功能技术有多个分支,其中计算机图形学分支中有光线追踪,PBR等功能技术。
关键词:光学;计算机图形学;计算机硬件结构;立体几何;数字媒体技术;虚拟现实
一:基本概念与结构
GPU的全称为graphic processing unit,是专门在电子计算机上进行图形相关处理以及承担部分计算任务等工作的处理器,其主要作用有承担较大规模的计算任务,渲染数据并输出画面至显示器上等等。早期计算机的性能需求较低,结构相对简单,因此CPU可以承担几乎所有的运算任务。但随着技术发展与对计算机性能要求的提升,CPU已经难以胜任处理计算机内所有的任务。因此,计算机界想出了一个办法:创造另一个独立于CPU的新处理单元,专门负责处理图形相关任务,增强计算机的并行计算能力,这便是GPU的雏形。如今,我们在显示器上看到的画面基本都是由GPU进行渲染并输出的,由于其运算规模较大等特性,如今GPU早已突破了用于增强计算机并行计算能力的设计初衷,在自动驾驶,人工智能,媒体娱乐等方面也发挥着极其重大的作用。
在高中信息技术的学习中,我们都知道计算机主要由五部分组成:即运算器,控制器,存储器,输入设备与输出设备。其中运算器与控制器合称CPU(中央处理器),并没有GPU的影子,那么GPU属于计算机的哪种结构呢?实际上,同CPU一样,GPU在功能上也属于运算器与控制器,但电子计算机被发明以来,其具体硬件结构不断更迭,例如早期计算机使用的早已被淘汰的地址总线或磁芯存储器,到现在的apu,ddr颗粒内存等。到目前,电子计算机的具体硬件组成主要可归为CPU,GPU(显卡),内存,硬盘,主板,散热器,显示器以及外设等,但无论几十年来计算机的具体结构如何更迭,其底层结构一直遵从“运算器,控制器,存储器,输入设备,输出设备”的冯·诺依曼式基本结构,而GPU也是近二十年来才逐渐发展成熟并成为计算机主要元器件的,未来计算机结构还可能产生各种更迭,故在我们学习的冯氏计算机结构图中并未标注出GPU与其他主要元件。之所以专门划出了CPU,是因为在几十年的计算机硬件组成更迭中,CPU一直都是存在于具体硬件体系中的核心部件不变,在可预见的未来也不会改变。
相较于我们所熟知的CPU,GPU有着更强的图形运算能力以及更大的运算规模,并将算术逻辑单元(alu)集成至流处理器内,换来了以流处理器为基本结构的更多运算单元以及显存(即dram)等区别。
笔者在这里需要说明的是,GPU在某些情况下可以视作显卡。由于其结构较为复杂,我们仅在这里介绍GPU内部的核心结构之二:显存与流式多处理器。
1.显存
显存(Display Random Access Memory或Video Random Access Memory,简称DRAM或VRAM),是GPU中暂存数据的部件。在高中阶段信息技术的学习中,我们知道CPU产生数据后会先将数据发送至内存部分进行暂存,而显存我们可以理解为GPU所用的内存,其本身也与内存十分相似,它会存储GPU处理过或即将提取的渲染数据。
显存主要有三个参数:容量,位宽与频率。通常来说,这三个参数的数值越大,所代表的GPU性能也就越强,其定位越高端。
显存容量通常以GB为单位,其代表了显存所能存储数据的多少。一般的GPU显存容量通常在2GB或4GB左右,部分高端GPU的显存容量可以超过20GB。值得一提的是,现在很多对电脑性能有较高需求的软件都对显存容量有着要求,如果显存容量不足,则很可能出现软件崩溃或无法打开的情况。对于有一定性能需求的电脑,其GPU显存容量应以不低于6GB为宜。
显存位宽代表了显存在单次传输中所能传输的数据量大小,其单位为比特(bit)。低端GPU的显存位宽一般在64bit左右,高端型号可以达到256或512bit以上,对于部分特殊用途的专业显卡,其显存位宽甚至能达到惊人的2048bit。
显存频率代表了显存工作时在单位时间内的工作频率,如果说显存位宽是“单次传输数据量的多少”,那么显存频率就代表了单位时间内“进行传输任务的多少”,其以Mhz为单位,其大小从数百Mhz到超过两万Mhz不等。需要注意的是,显存频率并不等于GPU中的核心频率,后者往往远低于前者,例如GeForce RTX3060的显存频率为15000Mhz,而核心频率仅为1777Mhz。
为了计算显存的运行速度,我们将显存位宽与显存频率的乘积称为显存带宽,显存带宽的大小直接反映了显存的工作效率。
2.流式多处理器
流式多处理器(Streaming Multiprocessor,简称SM,也称计算单元)是GPU的核心组成部分之一,一个GPU可以有一个或者多个SM。SM被看做GPU的心脏,可以类比CPU的核心。
相同架构的GPU包含的SM数量通常代表了GPU的性能定位,有的低端GPU配备了1个SM,部分高端GPU则可以拥有多达数百个SM。而GPU类型则定义了这些SM的功能。
SM结构下又会细分出不同的功能区域以及核心,这里简单介绍最重要的组成之一:流处理器。
流处理器(Streaming Processor ,简称SP)是GPU最基本的处理单元,对于NVIDIA牌的GPU也可称为CUDA。每个SM中包含多个SP,由GPU架构决定其功能区别。我们所说的GPU中有几千个核心或者cuda单元中,这个几千指的就是流处理器的数量。一个流处理器在运行时代表一个线程。流处理器只相当于CPU处理器中的执行单元,负责执行指令进行运算,并不包含控制单元(GPU的控制单元为Warp与指令调度单元,这里不再赘述)。
简单的说,流处理器相当于整个GPU的大脑,承担了计算机大部分的渲染运算任务。我们都知道计算机的显示画面是由一个个像素点所构成的,而渲染这些像素的主要元件,就是GPU中的流处理器。流处理器的数量在大部分情况下可以直接等同于GPU的性能强度,其数量从100余个到超过10000个不等,如英特尔的UHD620仅配备来了192个流处理器,而NVIDIA的GeForce RTX4090的流处理器个数高达18342个(一说16384个),当然,对于大部分的性能需求,几千个流处理器足以满足了。
二:GPU的部分工作原理及其流程
在高中阶段的信息技术学习中,我们知道由运算器,控制器和存储器构成的CPU负责电脑的核心控制与计算任务,在前面已经提过,CPU难以胜任计算量较为庞大的图形计算任务,因此便需要GPU来对其进行专门的运算,但GPU并不是独立运行的,其在工作上高度依赖与CPU的“合作”。
在笔者看来,GPU的工作原理主要可以简述为:CPU产生数据→GPU运算数据→GPU输出数据至显示器→显示器产生画面。
要想进一步说明GPU的工作原理,我们首先需要了解以下几个概念:
1.计算机图形学
计算机图形学(computer graphics,简称CG)是一门集合了物理学,数学以及计算机科学的学科,其涉及范围较广,并没有严格的定义与界限。中国科学技术大学教授刘利刚在《什么是计算机图形学?》一文中认为“广义的计算机图形学的研究内容非常广泛,如图形硬件、图形标准、图形交互技术、光栅图形生成算法、曲线曲面造型、实体造型、真实感图形计算与显示算法,以及科学计算可视化、计算机动画、自然景物仿真、虚拟现实等”,在笔者看来,我们可以简单的认为计算机图形学是对于数字图像,画面等视觉效果相关的一门学科。动画,建模,渲染,虚拟现实技术等技术均属于计算机图形学范畴。
2.API
API(Application Program Interface)被定义为应用程序可用以与计算机操作系统交换信息和命令的接口。一个标准的API为用户或软件开发商提供一个通用编程环境,以编写可交互运行于不同厂商计算机的应用程序。
举个常见的例子,我们在使用一些非腾讯公司的软件的时候,也可以选择微信登录。软件的开发商并非腾讯,为什么可以在软件中实现微信的登录功能呢?这就是软件开发商调用了微信的API的缘故。在这个案例中,通过API,软件开发商在自己的软件中也可以实现微信的部分功能,也就是说API承担着“桥梁”的作用,可以直接调用一些现成的相对成熟的数据以实现某些功能,而无需全部由开发者来设计这些功能,还是以微信登录举例,现有的微信用户群体已经十分广泛,开发者可以直接调用微信API来将微信登录作为登录方式,从而大大缩短了登陆系统的开发时间。
在图形学相关的编辑与开发中,我们常常用到图形学API,常见的图形学API有DirectX,OpenGL,Vulkan等。
3.着色器
着色器(shader)并非GPU硬件的一部分,而是一种用于实现图像渲染的可编辑程序。着色器主要分为顶点着色器(Vertex Shader)与像素着色器(Pixel Shader)两种,前者主要负责图形各顶点几何关系等的运算,后者主要负责视觉色彩相关的计算,我们会在之后说明。
好了,下面让我们以渲染任务举例,进一步解析GPU的工作流程及原理:

笔者首先需要强调的是,在整个过程中,图形学API在对GPU的控制中都起着决定性作用。在绝大部分情况下,用户对GPU所实现的控制都是通过应用程序调用了其内置的图形学API来实现的,作个比喻:图形学API就好像连接软件程序与GPU的“桥梁”。
当我们通过输入设备向计算机发出开始相关渲染任务的指令后,内置了图形学API的应用程序会开始对GPU进行调用,这是GPU整个工作流程的起点。CPU会先行生成目标图形的顶点坐标,法向量,纹理坐标等数据,并将其提交给GPU进行处理,这时就来到了GPU工作流程中的第一个阶段:几何处理。
我们都知道,三角形具有稳定性,其三个顶点必然在同一平面上,且其可以拼接成为任何常规图形。故我们在计算机设备中看到的任何三维物体,其几何形状全部由一个个三角形拼接组成。因此在计算机图形学中,三角形被称为“图元”,是组成计算机内图形的基本单元。几何处理以CPU送给GPU的顶点信息为起点,例如下图所示: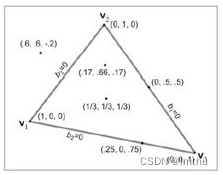
接收到CPU产生的相关数据后,我们就需要用到之前提到过的着色器中的顶点着色器(vertex shader),GPU的几何单元通过调用顶点着色器,在我们镜头所视的角度对这些坐标数据进行“描点”与连线,一个个图元就这样组成了我们所需的图形的几何外形。
完成多边形输出之后,我们就来到了顶点处理部分。对于同一目标图形需要出现的不同形态,GPU中的几何单元会通过“拖动顶点”的方式来实现几何外形的转变。应用程序会先生成位置需要发生改变的顶点的特定位置方程,而GPU几何单元就会根据这些方程来改变相关顶点的位置,来实现模型外形的变换。这一步可以说是整个几何处理的核心阶段。
几何处理完成后,我们的渲染目标就具备了形状,接下来GPU会转入下一阶段的工作:光栅化。
光栅化阶段是将上一个阶段中产生的几何图元转化成为二维图像的过程,该过程产生片元。二维图像上的每个点都包含了颜色,位置,纹理等信息数据。我们把该点和其附属的相关数据叫做一个片元(fragment)。而光栅化,就是将图元转化为片元的过程。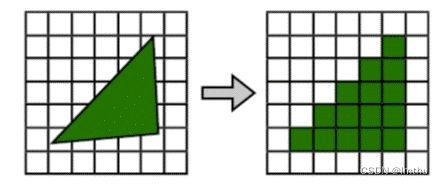
为什么要进行光栅化呢?因为几何出来得到的点,三角形都是三维信息,而图形最终只能在二维的屏幕上显示,所以必须进行三维到二维的转换。而光栅化的目的,是找出一个几何单元所覆盖的像素。光栅化会根据几何单元各个顶点的位置,来确定需要多少个像素点才能构成该几何单元,以及每个像素点都应得到哪些数据,同时将这些由三维图形转化成的像素输出。在这之后,GPU会转入下一个工作流程:纹理与像素处理。
在前面的几何处理与光栅化中,我们的渲染目标只具备了基本的形状,而这一阶段需要做的,便是在目标外形上“贴”上我们所需的颜色,纹理等效果。程序员们会事先制作好这次渲染中需要用到的素材库,GPU流处理器中的纹理单元(Texture Mapping Unit,简称TMU)会预先烘焙好所需的材质纹理,同时,GPU便会调用我们之前提到的着色器中的像素着色器(Pixel Shader)从显存中直接读取目标的纹理与颜色数据,并基于上一个阶段所产生的片元数据对目标片元进行上色与渲染工作。这种渲染方式可以近似理解为将提前烘焙渲染好的材质直接“提取”出来,大大提高了渲染效率。
纹理与像素处理阶段已经使渲染目标具备了基本的视觉特征,接下来我们来到GPU渲染工作的最后一个阶段:渲染输出。
在这个阶段,GPU主要依靠流处理器中的渲染输出单元(Render Output Processer,简称ROP)进行最终的渲染以及输出。ROP单元会先对先前产生的纹理以及像素数据进行“深度检查”,这里的“深度”并不是指其进行程度有多么深入与彻底,而是说基于产生数据在“深度”这一角度上的表现进行检查,虽然光栅化已经将三维图形全部转化成了二维像素,但其深度数据依旧会保留。ROP单元在这一步需要做的,就是根据光栅化流程保留下的深度数据进行检查与改动。对于深度和模板信息的判断能够让ROP做出让哪些像素被显示出来的决定,这一步可以避免本应被遮挡住的部分却错误地显示出来,同时也能够减少后续的输出压力。
在经过深度检查后,GPU进入了渲染输出的最终阶段,即像素填充(Pixel Fillrate,简称PF),该阶段会将之前几个步骤产生的全部图像数据以正确方式混合,通过总线输出至显示器上,并最终成为我们所看到的图像。
三:常见的GPU及其分类
首先需要说明,GPU在计算机硬件体系中并非独立单元,对于电子计算机来说,GPU在硬件配置中体现为“显卡”,故在这里将会对显卡进行描述,在大部分情况下可以粗略地将GPU与显卡画等号。
显卡主要分为三类:独立显卡,集成显卡与核芯显卡。
1.独立显卡
独立显卡,简称独显,是目前电脑上的主流显卡类型之一,也是对具有性能需求的电脑几乎唯一的选择。其将显示芯片、显存及其相关电路单独做在一块电路板上,自成一体而作为一块独立的板卡存在,插于机箱内主板的扩展插槽上,其具有三种显卡类型中最高的性能,但同时也带来了极高的功耗。对于性能较强劲的电脑来说,其独立显卡通常占据了整台电脑一半以上的功耗,并且随着技术的发展,其功耗与性能也同样在飞速增长中。
常见的独立显卡品牌有NVIDIA(英伟达)以及AMD,前者的常见类型有GeForce GTX系列,GeForce RTX系列等,例如我校的模型教室的电脑所使用的显卡就来自于GeForce GTX系列。后者的常见类型有RX系列等,其流行规模一般小于前者。
2.集成显卡
集成显卡,简称集显,指集成与主板南北桥之间的显卡,由于这种显卡早已被淘汰,因此现在集成显卡多指核芯显卡。
3.核芯显卡
核芯显卡,简称核显,是目前计算机上的另一种主流GPU硬件类型之一。相较于独显,核显的性能与功耗都更低,其基本模式是将GPU单元与CPU封装在一起,这样GPU就可以作为CPU的“一部分”,而非更为占据空间的独立显卡,使得计算机在体积,价格,环保等方面得到优化,相应地,其性能也会受到大幅限制。目前大部分的轻薄笔记本与轻量化用途的台式电脑均使用核显,例如我校计算机机房的GPU就是其CPUi7-7700内部集成的HD graphics 630作为GPU。另外,由于体积限制,目前手机上的GPU单元均为核显。
为了更直观表示同一定位下的核显与独显的性能差距,笔者做了几组实验,以对比同定位等级的核显与独显的性能:
以下是笔者的测试平台主要配置:
| Cpu | Intel i5 12600k(核显为UHD770) |
| GPU | 七彩虹NVIDIA GeForceRTX 3060ti iGame Ultra |
| 内存 | Kingston FURY 16Gx2 3600Mhz |
| 硬盘 | Acer PREDATOR NVMe 1TB |
| 主板 | MSI B660M MORTAR |
本实验中的cpu与GPU均采用了同一级别的较高端性能定位配置,实验条件中的屏幕分辨率一律为1920x1080,让我们来看看同一定位下的核显与其配套独显的性能对比情况。
由于时间有限,笔者无法从各个方面进行全面的性能测试实验,只能从几个不同领域方面的性能进行测试,结果如下:
- 基准测试与实时渲染工程对比试验
在这项实验中,我们分别使核显与独显运行一些基准测试软件或实时渲染工程,这主要反映了GPU在三维渲染方面的能力。
以下是实验数据:
| PassMark 3D标准 | 3DMark time spy | 3DMark fire strike | |
| RTX 3060ti独显 | 20589分 | 12002分 | 25980分 |
| UHD770(cpu的核显) | 2279分 | 1226分 | 2005分 |
| Unigine heaven | RDR2 最高画质 | Cyberpunk2077 最高画质 | |
| RTX 3060ti独显 | 5149分 | 平均51fps | 平均28fps |
| UHD770(cpu的核显) | 547分 | - | - |
- 视频编码输出能力对比实验
我们对于同一视频工程文件,在pr中将其以不同的编码格式导出(CUDA加速已关闭),以此多次对比两者的编码性能。
以下是实验数据:(单位:秒)
| H.264 | H.265 | MPEG4 | |
| RTX 3060ti独显 | 67s | 93s | 52s |
| UHD770(cpu的核显) | 359s | 577s | 336s |
- 并行计算能力对比实验
我们借助Passware Kit Forensic 对同一加密后的压缩包进行穷举法破解密码,电脑每秒钟所尝试的密码数量可以直接反映GPU并行计算能力。
| 硬件配置/算法 | Dictionary | Brute-force | Xieve |
| RTX3060ti独显 | 79780p/s | 50810p/s | 47294p/s |
| UHD770(cpu的核显) | 1248p/s | 578p/s | 855p/s |
结论:通过以上实验我们可以看出,同一定位下独立显卡的性能远超核芯显卡,后者在某些环境下甚至无法正常工作,对于需要一定性能需求的计算机,是用独立显卡明显可以获得更好的表现。
四:部分基于GPU的相关功能与技术
在开始之前,笔者需要注明:GPU的功能非常强大,几乎所有的涉及计算机图形学的计算机功能都会涉及到它的某些功能,基于其的相关功能与技术也有很多分支(比如AI计算等),受篇幅所限,这里笔者只能为大家浅析图形学分支下的很少几项。
1.光线追踪
光线追踪(Ray Tracing,简称RT),作为当前计算机图形学的重要组成部分与前沿技术,在游戏以及影视特效等领域有着广泛的应用。其基本原理是在通过特定算法,由GPU计算并最大限度模拟贴合现实物理规则的光线效果,包括但不限于更佳效果的阴影,光路,反射,折射,光泽效果,物体质感等。通过光线追踪技术,我们可以获得极佳的图形效果质量,但同样,光线追踪也拥有着极度恐怖的性能要求。
在现实世界中,光是由光源发射,最后传入我们的眼中的,但想要在计算机中模拟这一点,就需要渲染几乎无限的光线,如此庞大的数据量是任何计算机都无法承受的。为此,计算机图形学界想出了一种解决方案:将光线的起点改为摄像机,也就是操作者的视角,最后“反向”传入光源处,计算此过程的光线交互效果并输出至摄像机(用户视角)上,这个过程被称为求交运算。这样做避免了渲染大量我们看不到的无用光线,可以确保渲染任务中只包含我们需要看到的光线,这样一来就极大地减小了运算量,虽然依旧很高,但至少处在计算机可以承受的范围内了。由于光路可逆,所以在光线追踪技术中,即使光线的传播变为“反向”,所呈现的光线效果依旧不变。
光线追踪按照其实现方式也被分为两种,即软光追与硬光追。但无论是哪一种,都是通过计算机内的GPU硬件实现光线追踪的。软光追多指借软件光追算法以及通过API进行开发与GPU调用来实现光线追踪,而硬光追多指装备了相关领域的加速元件的GPU,例如开发专门的并行计算架构(CUDA或RT核心),改造着色器面积分配等,并通过这些部分在软光追的基础上对渲染进行加速,以获得更高的渲染效率。
在光线追踪的基础上将其与蒙特卡洛采样算法结合,便衍生出了光线追踪的另一种表现方式“路径追踪”,它以统计的方式来近似解决渲染方程,通过随机跟踪光线并计算它们在场景中相遇或反射的概率来计算颜色。路径追踪的优点在于可以更好地处理复杂照明和材质,实现更真实的光线传输效果,但也需要更高的渲染时间和更多的计算资源。很多时候路径追踪会与光线追踪混合使用,部分开发者会将其统一表述为“光线追踪”
另外,笔者在这里需要澄清很多人对于光线追踪理解的一个常见误区,即光线追踪只有在RTX显卡上实现,或光线追踪等于RTX。
这个认识误区最早来自于部分个人或组织对于半导体生产商NVIDIA在2018年发布的新一代显卡“RTX”系列中的曲解。NVIDIA在2018年发布了名为“RTX显卡”的新类型显卡,其与常规显卡的主要区别在于RTX型显卡内置了RT核心,而RT核心的用途是加速求交运算。很多人误把RT核心与RTX功能视为实现光线追踪效果的硬件基础,但实际上光线追踪的应用远早于RTX的发布。光线追踪属于一种算法,在上世纪,光线追踪的概念就已经被提出,并在之后被广泛运用于计算机图形学领域。RTX的功能只是在一定程度上提升光线追踪的渲染效率并增强渲染质量,而不是决定光线追踪效果能否正常呈现的因素。此外,借助了RTX的光线追踪也未必一定拥有更佳的画面效果,例如微软的Minecraft BE,尽管其加入了RTX光线追踪,但实际上的画面效果很糟糕。在笔者看来,决定画面质量的最重要因素应当是开发者自身的能力水平,即使具备最好的技术条件,如果没有驾驭它们的能力,最终效果也会不尽人意。
2.PBR
通过光线追踪进行渲染具有极高的性能要求,有没有一种更大众化的方法来对物体表面的阴影,反射,光泽等效果进行渲染呢?答案是有,这就是PBR。
PBR(Physically-Based Rendering,基于物理的渲染)同样是一种模拟现实物理的光照与渲染的技术流程。作为GPU基本功能的一种体现,PBR相比于光线追踪在性能要求上更低,同时也具有很高的普及程度,是当前计算机图形学中的主流渲染方案之一,
在解释PBR前,笔者先要说明一下菲涅尔效应以及微表面理论:
菲涅尔效应:在视线垂直于物体表面时,反射较弱,随着视线与物体表面夹角减小,所观察到的反射效果增强。
举个例子,我们站在水边看湖水时,我们会发现自己很容易看到脚边水面下一定深度的事物。而当我们看向更远处的水面时,我们所观察到的水面反射会明显更强,而水下的东西就很难看清了,这便是菲涅尔效应的体现。菲涅尔效应确定了计算机图形学中反射效果与观察角度的关系与变化,在计算机图形学上有着极其重要的地位。
微表面理论是一种用于计算机图形学中的渲染技术,它将物体表面在微观上统一视作由许多朝向各异且光学性质相等的微小表面组成的,而这些微小表面会对光线的反射产生影响。微表面理论是基于微分几何对反射率影响的数学分析的成果,最初是由物理光学领域的研究人员开发的。微表面理论可以更精确地描述物体表面的光学特性,从而使得渲染出来的图像更加真实。
与其说PBR是一种渲染方案,不如说是一套完整的渲染流程与标准。按照其底层设计原理可主要分为两种工作流:即金属值/粗糙度(Metallic/Roughness)工作流与镜面反射/光泽度(Specular/Glossiness)工作流,也称高光工作流。这两种工作流的基本原理,我们可以参照unity对这两种工作流的参数图表来进一步了解它们之间的差别:

通过PBR,我们可以更加高效地进行计算机上渲染任务的描述与运行,例如我们看到的计算机渲染出的材质和光照反馈,很大程度上依赖于PBR。
作为高度成熟的主流渲染方案,PBR已经自动集成于很多引擎及专业软件中,在很多状况下,我们只需要输入一些渲染方程(根据漫反射程度,菲涅尔效应等设计),再对相关参数进行调节,便可以得到大量我们想要的材质以及相关反馈。
这张图片或许能更为直观的表明PBR功能的全面性。基于PBR,只需调节最多11个参数,便可以精确模拟出几乎所有的现实物理材质在不同粗糙度下的光照反馈结果。
3.视频的编解码
在高中阶段信息技术的学习中,我们都知道视频都有与其对应的格式(如mp4,avi等),这种存在于视频文件后缀的格式叫做视频的封装格式,负责集成封装整个视频并使其可以在播放器上运行。事实上,除了封装格式,视频还有一个相当重要的格式:编码格式。
我们在计算机上播放视频的过程,就是GPU通过编解码器对视频进行解码然后输出的过程。“解码”所指的就是针对其编码格式进行解析,使其成为可以直接输出为画面的数据。对于计算机来说,针对视频的编解码单元全部都集成于GPU或内部。或许有人要问了:视频为什么要进行编码操作呢?实际上,随着计算机技术的飞速进步,视频中所含的信息量也越来越大,这时我们就需要编码格式来对视频原数据进行一定的压缩,在不损失画面质量的前提下尽可能地减小视频文件的体积,使其更为高效。不同编码格式代表了不同的压缩方式。随着计算机技术的进步,视频的编码格式也在不断更迭中。
目前较为主流的视频编码格式为H.264格式,常见的编码格式还有HEVC(H.265),QuickTime,AV1等。需要说明的是,编码格式与封装格式并不唯一对应,同一种编码格式可以选择多个封装格式,同一种封装格式也可以有多个编码格式选择,但并非全部的编码与封装格式都可以互相兼容。对于使用GPU对视频的编解码,我们通常称之为“硬解”,如果对于一些当前GPU所不支持的视频编码格式,我们还可以使用CPU进行编解码,也就是“软解”,通常来说,硬解比软解更加高效。对于采用了CPU与GPU均不支持的编码格式的视频,则无法在电脑上顺利播放,通常会显示“视频的编码格式不受支持”等字样。
4.一些性能与效率的优化技术
作为计算机中运算量最大的处理单元,GPU自然少不了大量针对性能负载以及运行效率的优化技术,这里简单介绍其中几种使用较为广泛者。
AI插帧:通过特定的人工智能(简称AI,下同)算法,借以GPU渲染,实现对于视频或实时渲染工程(如游戏)的帧率提升。对于后者,AI插帧技术可以在不增强GPU性能负荷的情况下进一步提升其运行帧率,这种技术主要用于手机游戏中。但因为这种实时AI插帧需要硬件厂商与软件开发商双端进行适配开发,且需要较成熟的AI技术,所以应用并不广泛。对于前者的视频AI插帧来说,其可以极大地提升视频的帧率,且使用门槛较低,目前广泛应用于影视领域。
nanite与lumen:这是基于目前的主流图形学引擎之一UE5(即虚幻引擎5)的针对开发者的性能优化技术,其可以在图形学工程的开发中带来巨大的性能优化与效率提升。
nanite简单来说就是通过优化引擎内部的虚拟几何系统,使得正在开发中的工程文件可以同时预览或渲染更高精细度与更高面数的场景模型。通过nanite,开发者可以在场景中同时对由上千万甚至上亿多边形所渲染出的模型进行预览与调整,而在之前,这种级别的数据量甚至可以使一些小型的工作站直接宕机,更别论常规的高性能电脑了。
lumen则是UE5内的一套新型动态全局光照技术。前面已经说过,对于光线的反射与折射,我们通常需要设定特定的渲染方程对其进行表达,而对于被光照的材质表面,我们也需要单独设置其处于光照下的材质。而lumen可以直接根据光源位置自动模拟受光照材质表面间接的镜面反射以及漫反射效果,其可以直接根据光照角度产生光照场景,极大地提高了渲染以及开发效率。
DLSS与FSR:这两种技术在名称上虽然大相径庭,但其目的与具体效果较为相似。这两种技术都应用于游戏领域,其通过成熟的AI算法,降低GPU本身的渲染精度,使用相关的AI神经网络单元,而非消耗GPU光栅化性能再进行高分辨率的填充渲染,使得最终画面可以近似获得更高的渲染精度。简单概括,就是“在使画面质量损失尽可能小的情况下降低计算机性能负载,以获得更高的流畅度(帧率)”。
五:对于GPU未来发展的展望
笔者认为,GPU的未来发展前景非常广阔。随着人工智能、机器学习、大数据,自动驾驶等技术的快速发展,GPU在数据处理、深度学习等领域中的应用越来越广泛。同时,越来越多的新技术也需要更高性能的GPU加持。因此,GPU的性能优化、功耗控制等方面将是未来发展的关键。而随着芯片制造技术的不断进步,更加高效的GPU芯片,以及GPU与CPU协同工作的解决方案也将得到更广泛的应用。总的来说,GPU的发展前景是非常广阔和光明的,我们可以期待未来GPU技术的发展会带来更多的惊喜和应用领域的拓展。
GPU所属的计算机产业是一种经济产业,其技术的进步要依靠经济效益作为基础,不像造原子弹那样可以无视经济效益进行科学研究,而推动计算机科学技术进步的购买与使用需求来自于很多产业领域,这些领域大多是新兴的,有的不受重视甚至背负着误解,但我们可以看到,正是这些领域及其产业的蓬勃发展才增加了世界对于更强大GPU乃至计算机芯片的需求量,进而直接推动了计算机科学的进步。高端GPU芯片技术长期以来一直被西方大国垄断,形势在目前虽然有些许改变,但总体上对我们来说依旧不容乐观。想要消除“卡脖子”的风险,就必须正视这些作为推动计算机技术进步最大的原动力,而非只能看到科研单位企业本身。计算机软硬件各方面的产业都是紧密连接彼此影响的,只有相关产业健康而蓬勃的发展,形成稳固的产业链为芯片制造与研究企业有力“供能”,人们对于更高端计算机GPU的需求量增加,我们才能真正的破解“卡脖子”问题。
结语:综上所述,GPU强大而多样化的功能以及在当今计算机硬件体系中无可替代的重要地位。GPU具有强大的计算性能和并行处理能力,广泛应用于各个与计算机相关的领域。其不断发展和创新使得计算机在计算和处理效率方面获得了极大的提升,成为现代计算机系统中不可替代的重要组成部分。
参考文献:
刘利刚. 什么是计算机图形学?[EB/OL]. 2020[2023.3.26]. http://staff.ustc.edu.cn/~lgliu/Resources/CG/What_is_CG.htm.
THRASH_T. PBR——概述、基于物理的材质[EB/OL]. 2022[2022.10.30]. https://blog.csdn.net/qq_15972907/article/details/124655810.
Unity. Unity中文手册[EB/OL]. 2022[2023.3.26]. https://docs.unity.cn/cn/current/Manual/index.html.

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









