






在批量提交几十个Job后,需要得到每个算例中20个SET在U3方向的位移,数据电子厂,在线打工
from odbAccess import openOdb
from textRepr import *
my_odb = openOdb(r"E:\240426slice\0425s3000t25slice.odb")
step = my_odb.steps['Step-1']
frame = step.frames[-1]
dis_field = frame.fieldOutputs['U']
for i in range(0,20):
setname = 'SET-N%s'%(i+1)
NodeSet = my_odb.rootAssembly.nodeSets[setname]
local_dis_values = dis_field.getSubset(region=NodeSet)
with open('3_25_N%s'%(i+1)+'.txt','w') as f:
f.write("NodeLabel, NodeDis\n")
for node_value in local_dis_values.values:
txt_line = "{}, {}\n".format(node_value.nodeLabel,node_value.data[2])
f.write(txt_line)
解释如下:
from odbAccess import openOdb
from textRepr import *
my_odb = openOdb(r"E:\240426slice\0425s3000t25slice.odb") #""中间替换成自己的路径
step = my_odb.steps['Step-1']
frame = step.frames[-1] #-1代表最后一帧,根据自己需要,比如你场输出100步,需要第51帧的,-1改成51也行
dis_field = frame.fieldOutputs['U'] #U代表位移
for i in range(0,20): #这里写了一个循环因为我有20个set,名称是SET-N1到SET-N20
setname = 'SET-N%s'%(i+1)
NodeSet = my_odb.rootAssembly.nodeSets[setname]
local_dis_values = dis_field.getSubset(region=NodeSet) #输出我指定的set的数据
with open('3_25_N%s'%(i+1)+'.txt','w') as f: #3_25_N%s'%(i+1)是我定义的名字3_25_Ni(i=1到20),可以改成自己的
f.write("NodeLabel, NodeDis\n")
for node_value in local_dis_values.values:
txt_line = "{}, {}\n".format(node_value.nodeLabel,node_value.data[2])
#.data存储了xyz三个方向的位移,data[0]是x方向,data[1]是y方向,data[2]是z方向,我只需要U3位移,所以只输出2,需要三个方向可以直接.data
#输出的格式是 节点编号-u3位移
f.write(txt_line) 在CAE界面操作
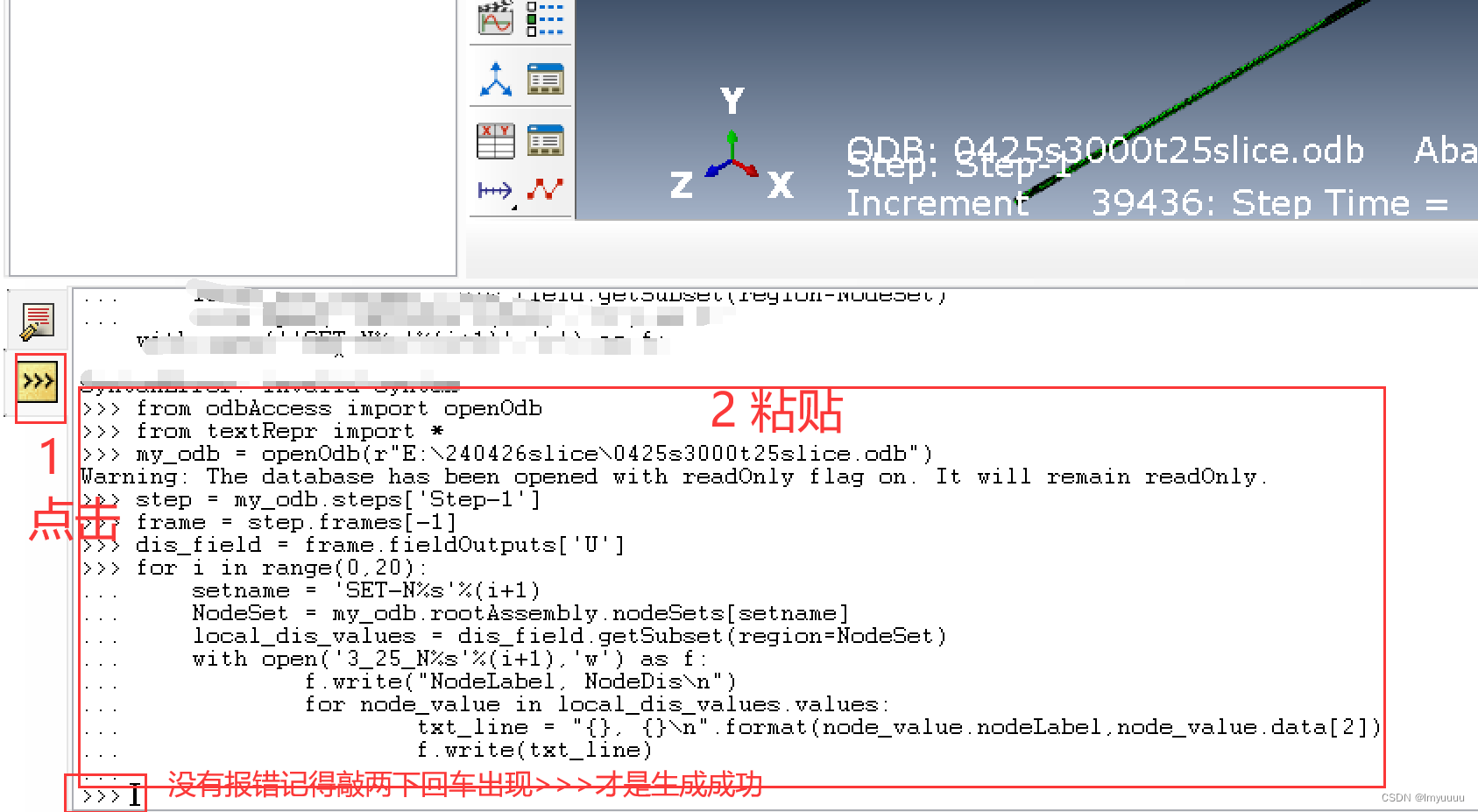
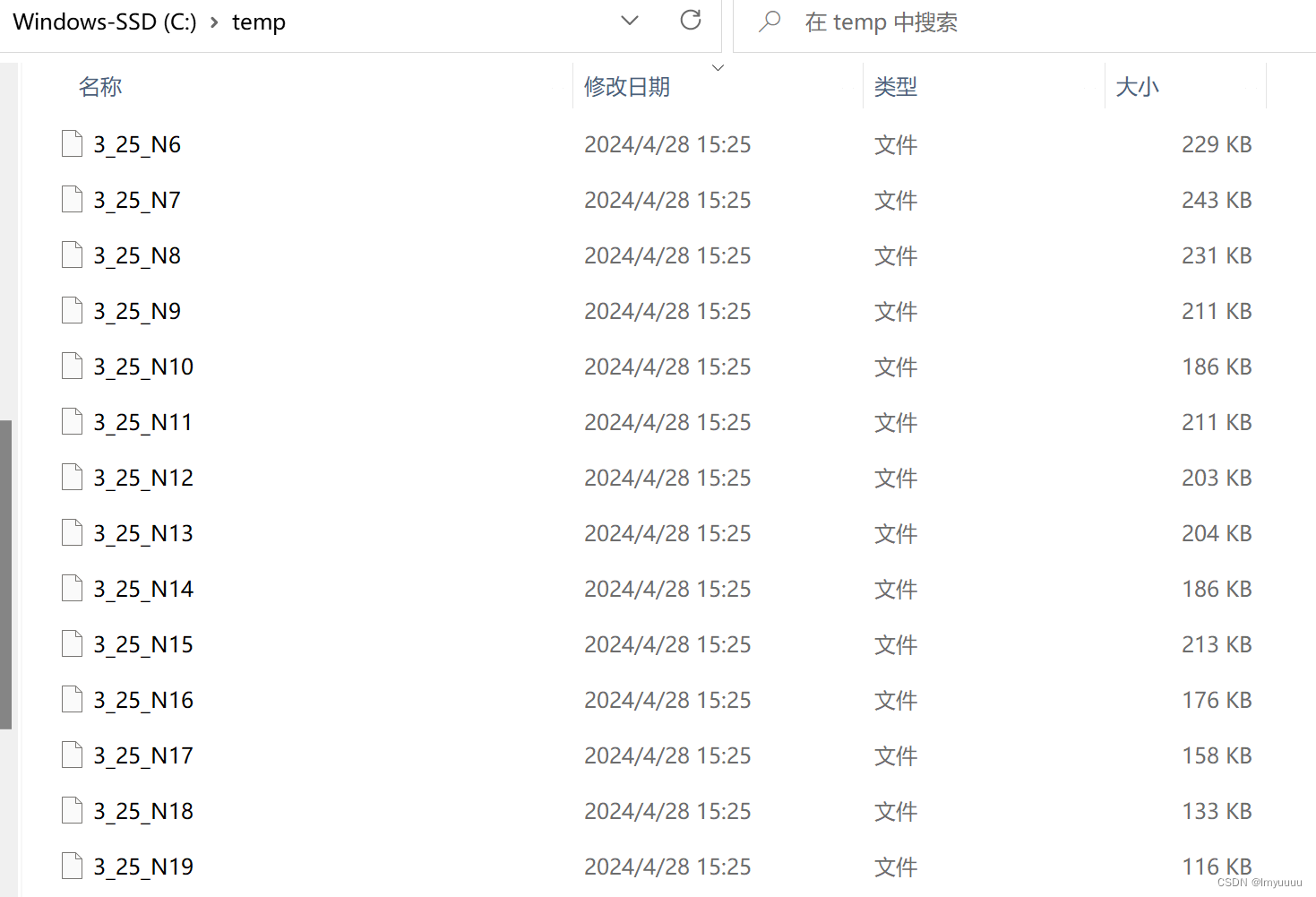
输出的文件在默认文件夹里,我是C/Temp里面:
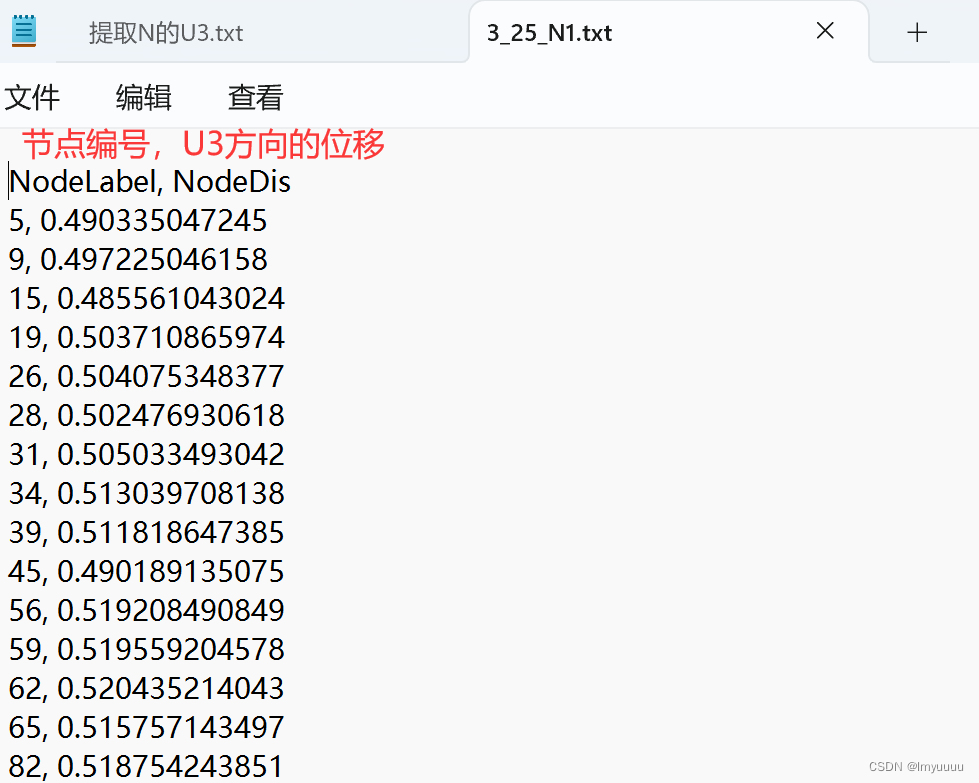
如果只需要单个集合的U3位移可以参照此代码:
from odbAccess import openOdb
from textRepr import *
my_odb = openOdb(r"你的文件位置")
step = my_odb.steps['Step-1']
frame = step.frames[-1]
dis_field = frame.fieldOutputs['U']
NodeSet = my_odb.rootAssembly.nodeSets['你的SET名称']
local_dis_values = dis_field.getSubset(region=NodeSet)
with open('你想输出的文件名字.txt','w') as f:
f.write("NodeLabel, NodeDis\n")
for node_value in local_dis_values.values:
txt_line = "{}, {}\n".format(node_value.nodeLabel,node_value.data[2])
f.write(txt_line)
-------------------------------------------------------------------------------------------------------------------------------
0429增加:好好好,数据不对劲还需要逐帧分析,修改代码如下:
from odbAccess import openOdb
from textRepr import *
my_odb = openOdb(r"E:\240426slice\0425s3000t250slice.odb")
step = my_odb.steps['Step-1']
for frame_step in range(44,60): #提取44-60帧的数据
frame = step.frames[frame_step]
dis_field = frame.fieldOutputs['U']
for i in range(0,20):
setname = 'SET-N%s'%(i+1)
NodeSet = my_odb.rootAssembly.nodeSets[setname]
local_dis_values = dis_field.getSubset(region=NodeSet)
with open('3_250_N%s'%(i+1)+'F'+str(frame_step)+'.txt','w') as f:
f.write("NodeLabel, NodeDis\n")
for node_value in local_dis_values.values:
txt_line = "{}, {}\n".format(node_value.nodeLabel,node_value.data[2])
f.write(txt_line) 















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









