







resquest申请
登录网页
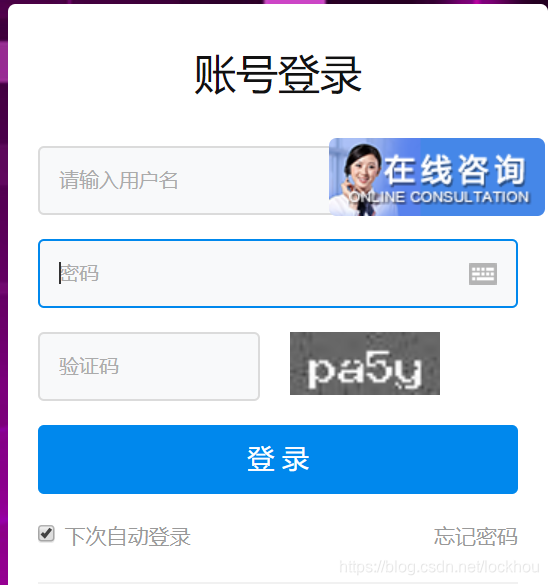
对应源码

对应代码

查找对应元素

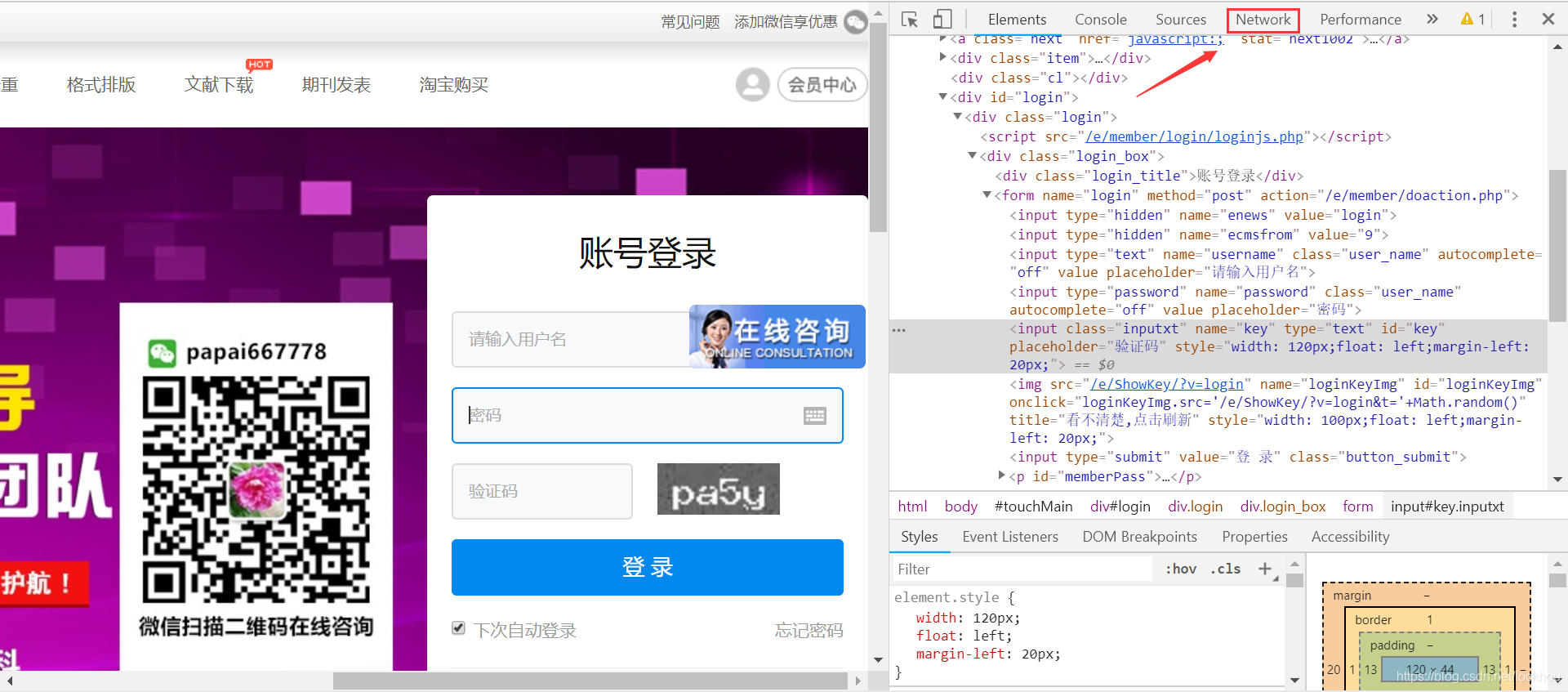
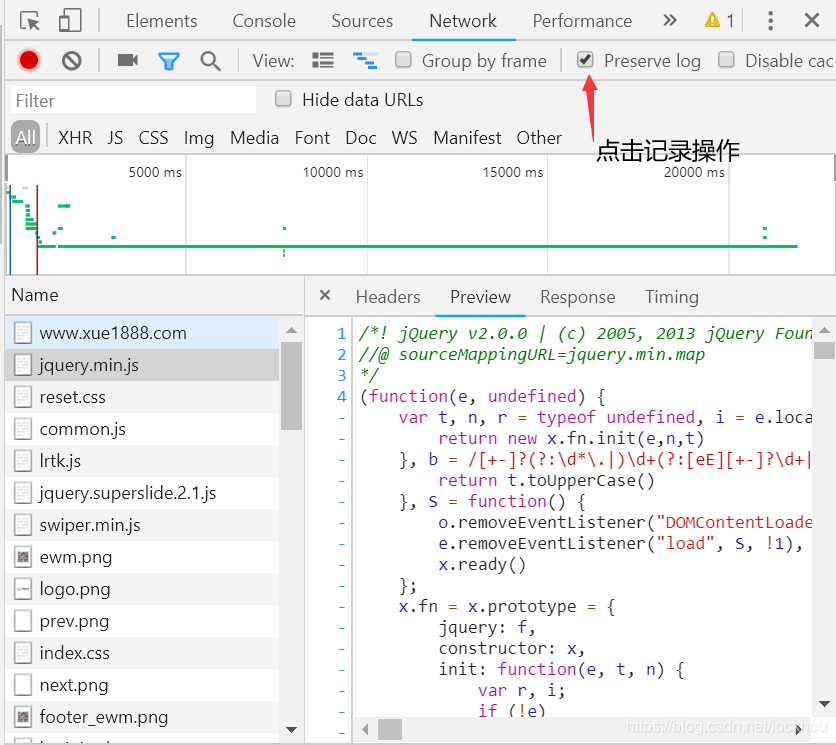
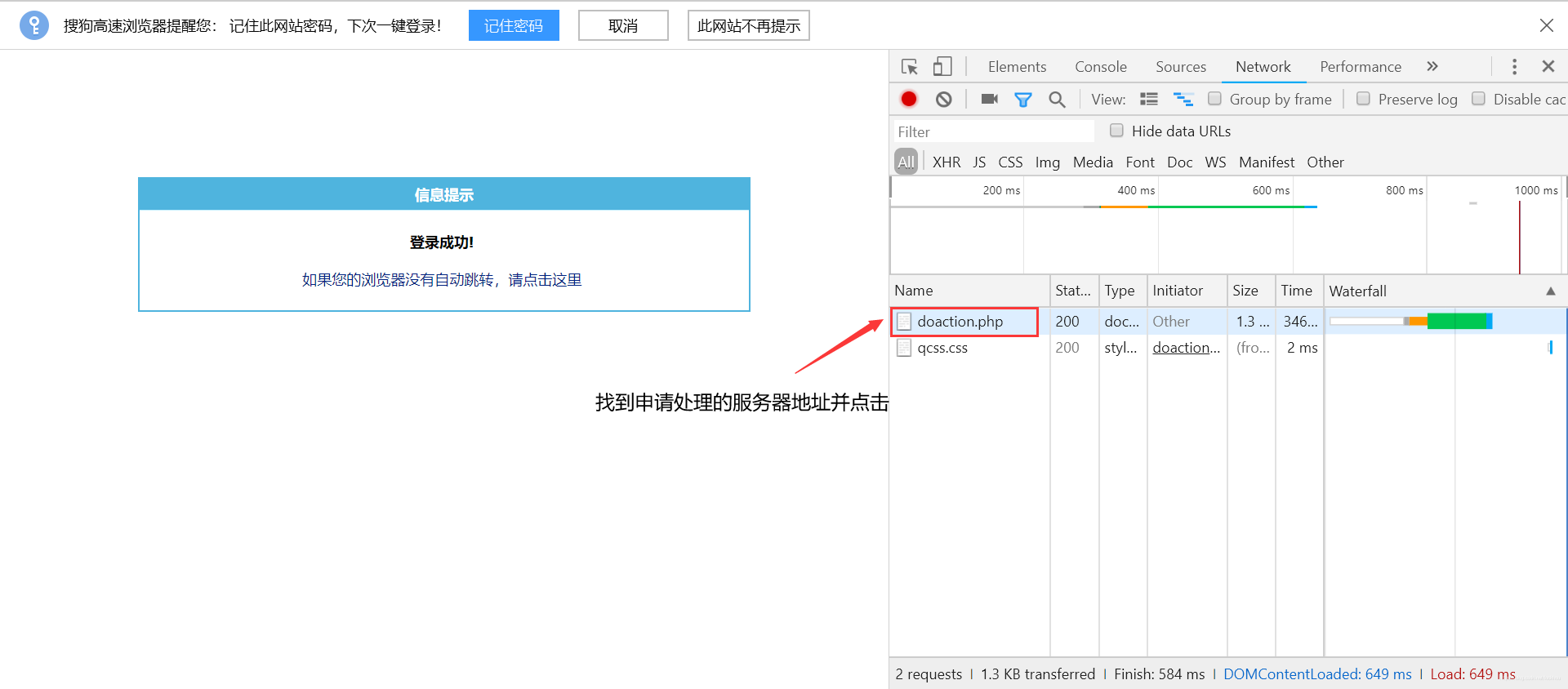
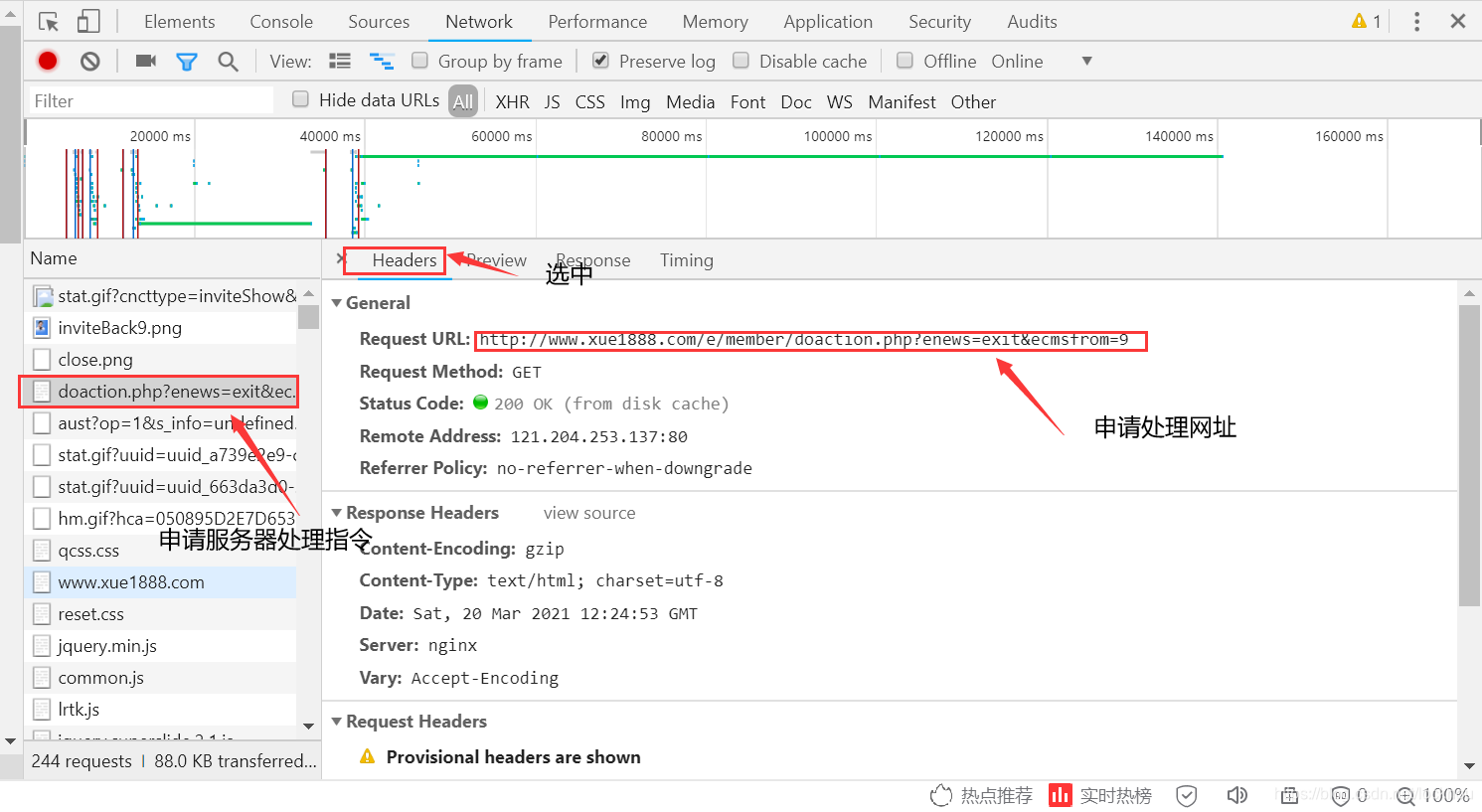
1.将申请处理网址作为session.post中的网址
2.将账号输入到pyload字典中作为“username”的值,将密码输入到pyload字典中作为“password”的值,键的名称取决于网页源代码中对文本框所取得名字。
webdriver申请
直接使用插件生成代码
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import time
driver = webdriver.Chrome() # 打开 Chrome 浏览器
# 将刚刚复制的帖在这
driver.get("http://www.xue1888.com/")
driver.execute_script("window.scrollTo(100,0);")
driver.get_screenshot_as_file("./sreenshot1.png")
key = input("please input the key with the picture:")
driver.find_element_by_name("username").send_keys("02158412")
driver.find_element_by_name("password").send_keys("194646")
driver.find_element_by_name("key").send_keys(key)
driver.find_element_by_xpath(u"//input[@value='登 录']").click()
time.sleep(10)
driver.find_element_by_link_text(u"点击进入文献下载页").click()
driver.get("http://www.xue1888.com/e/action/ListInfo/?classid=1")
driver.find_element_by_xpath("//div[@id='down_content']/div/div/ul/li[2]/a/div/h3").click()
driver.find_element_by_link_text(u"英文文献下载(推荐)").click()
driver.find_element_by_id("gs_hdr_tsi").clear()
driver.find_element_by_id("gs_hdr_tsi").send_keys("Pest identification")
driver.find_element_by_id("gs_hdr_frm").submit()
所有主要浏览器都支持 scrollTo() 方法
滚动内容的坐标位置100,500:
function scrollWindow(){
window.scrollTo(100,500);
}
启发于:https://www.jb51.net/article/140239.htm
具体内容如下:
1.安装selenium:
如果你已经安装好anaconda3,直接在windows的dos窗口输入命令安装selenium:
python -m pip install --upgrade pip
查看版本pip show selenium
2.接着去http://chromedriver.storage.googleapis.com/index.html下载chromedriver.exe(根据chrome的版本下载对应的)
3.将下载好的chromedriver.exe解压后放到指定目录
4.安装tesseract-ocr.exe 配置环境变量
5.安装pytesseract : pip install pytesseract
6.python脚本
思路:6.1登录页面按F12检查元素,获取用户名 密码 验证码 验证码图片的元素id
6.2.调用chromedriver
6.3.截取验证码图片的位置
6.4.pytesseract识别图片中字符,最后验证码识别为空!!???这个待解决
6.5.脚本如下:
from selenium import webdriver
from PIL import Image
import pytesseract
import os,time
chromedriver = "D:\Program Files\Anaconda3\selenium\webdriver\chromedriver.exe" #这里写本地的chromedriver 的所在路径
os.environ["webdriver.Chrome.driver"] = chromedriver #调用chrome浏览器
driver = webdriver.Chrome(chromedriver)
driver.get("http://xxxx.com") #该处为具体网址
driver.refresh() #刷新页面
driver.maximize_window() #浏览器最大化
#获取全屏图片,并截取验证码图片的位置
driver.get_screenshot_as_file('a.png')
location = driver.find_element_by_id('imgValidateCode').location
size = driver.find_element_by_id('imgValidateCode').size
left = location['x']
top = location['y']
right = location['x'] + size['width']
bottom = location['y'] + size['height']
a = Image.open("a.png")
im = a.crop((left,top,right,bottom))
im.save('a.png')
time.sleep(1)
#打开保存的验证码图片
image = Image.open("a.png")
#图片转换成字符
vcode = pytesseract.image_to_string(image)
print(vcode)
#填充用户名 密码 验证码
driver.find_element_by_id("staffCode").send_keys("username")
driver.find_element_by_id("pwd").send_keys("password")
driver.find_element_by_id("validateCode").send_keys(vcode)
#点击登录
driver.find_element_by_id("loginBtn").click()
如果大家有什么问题,欢迎关注公众号留言和博主进一步交流偶















 3056
3056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









