







 研究引入斯坦福情绪树库,为理解语义组合性提供大规模标记资源,并提出递归神经张量网络(RNTN)模型,该模型在情绪检测任务中取得显著提升,尤其是在捕捉否定情绪和复杂情绪结构方面表现出色。RNTN在新树库上训练后,单句情感分类准确率提升至85.4%,短语情感标签预测准确率为80.7%。
研究引入斯坦福情绪树库,为理解语义组合性提供大规模标记资源,并提出递归神经张量网络(RNTN)模型,该模型在情绪检测任务中取得显著提升,尤其是在捕捉否定情绪和复杂情绪结构方面表现出色。RNTN在新树库上训练后,单句情感分类准确率提升至85.4%,短语情感标签预测准确率为80.7%。
Richard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang,
Christopher D. Manning, Andrew Y. Ng and Christopher Potts
Stanford University, Stanford, CA 94305, USA
richard@socher.org,{aperelyg,jcchuang,ang}@cs.stanford.edu
{jeaneis,manning,cgpotts}@stanford.edu
摘要:语义词空间已经非常有用,但不能用有原则的方式来表达较长词组的含义。进一步的工作是,在情绪检测这类任务中理解语义的组合性,这需要更丰富的监督训练、评估资源和更强大的组合模型。为了解决这个问题,我们引入了情绪树库。在11855个句子组成的解析树中它为215154个短语设置了细粒度 情绪标签并提出了情绪组合性的新挑战。为了解决这些问题,我们引进了递归神经张量网络。当在新的树库基础上训练了之后,该模型的几个指标明显优于以前的所有方法。它推动了单句正/负分类领域的状态指标从80%到85.4%。预测所有短语情感标签细粒度的准确率达到了80.7%,特征基准包有了9.7%的改善。最后,它是唯一的一种可以准确地捕捉否定的影响的模型并且其范围遍历了包含肯定和否定短语的多级别树。
一、引言
单个单词的语义向量空间已被广泛的用作特征(Turney and Pantel, 2010)。因为它们不能正确地捕捉较长的词组的含义,组合性语义向量空间最近受到了很多关注(Mitchell和Lapata,2010; Socher等,2010;Zanzotto等人,2010; Yessenalina和Cardie,2011;Socher等,2012; Grefenstette等,2013)。然而,由于目前缺乏用来捕获这些数据呈现的基本现象的大型和已标记的组合型资源和模型,进展遇到了很大的阻碍。为了满足这一需求,我们引进了斯坦福情绪树库和一个强大的递归神经张量网络,能够准确预测目前在这个新主体的组成语义的影响。
斯坦福情绪树库是第一个完全标记分析的树主体,允许对语言中情绪的组合性影响进行全面分析。语料库是基于Pang and Lee (2005)引入的数据集,由11,855个从电影评论中提取的单句组成。它经由斯坦福分析器(Klein and Manning, 2003)分析,并且包括了来自那些解析树的总共215154个独特的短语,每个词语由三个人人工标注。这个新的数据集允许我们分析情绪的复杂性和捕捉复杂的语言现象。
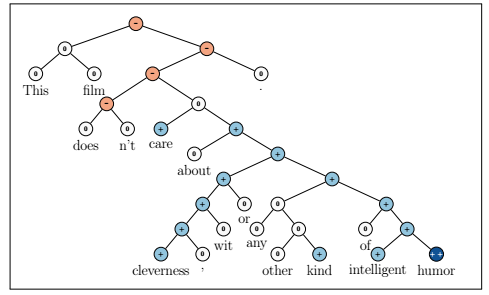
图一展示了一种清晰组成结构的例子,该数据集的粒度和大小将让团队用来训练基于监督和结构化机器学习技术的组成模型。虽然有多种数据集文件和块标签可供使用,但是仍然有必要更好地从短评中(如Twitter数据,其每篇文档提供较少的总信号)捕获情绪数据。为了获取更高的精度组成性的影响,我们提出了一个被称为递归神经张量网络(RNTN)新模式。递归神经张量网络采取任何长度的输入词组。它们通过单词向量和一个解析树来代表一个短语,之后利用使用相同张量基础的组合性功能的树来计算更高的节点向量。我们比较几个监督、组成性模型,如标准递归神经网络(RNN)(Socher等人 2011B),矩阵向量RNNs(Socher等,2012),和一些基准例如忽略了词序的神经网络,Naive Bayes (NB), bi-gram NB and SVM。当通过新的数据集训练之后,所有的模型都得到显著的提升,但是当预测所有节点的细分类情绪的时候,RNTN以80.7%的准确率获得了最高表现性能。最后,我们使用包括积极和消极的句子的一组测试集,它们的求反结果表明,不像单词集合包,RNTN能准确地捕捉到情绪的变化和否定的范围。RNTNs也学习那些对比结合但是却占主导地位的短语的情绪。完整的训练和测试代码,在线演示和斯坦福情绪树库数据集可在http://nlp.stanford.edu/sentiment 上获取。
二、相关工作
这项工作与自然语言理解的五个不同领域相关联,对于给定的空间限制,我们不能做出充分的正确判断,所以每个都有自己大量的相关工作。
Semantic Vector Spaces.(语义向量空间) 语义向量空间的主导方法是使用的单个单词相似分布。通常,一个字和它的空间上下文共同出现被用来描述每个单词(Turney and Pantel, 2010; Baroniand Lenci, 2010),例如tf-idf。这种思想的变体使用更复杂的频率,诸如在一个特定句法的上下文中一个单词是如何经常出现的(Pado and Lapata, 2007; Erk and Pado, 2008)。但是,分布式向量往往不能正确捕获反义词的差异,因为这些往往有相似的上下文。一个可能的补救方法是利用神经子向量(Bengio et al., 2003)。这些向量可以通过无监督的方式进行训练来捕捉相似分布(Collobert and Weston, 2008; Huang et al., 2012),但是还可以进行微调和训练如情绪检测特定的任务(Socher et al., 2011b)。本文的模型能够使用纯粹的监督字表示。这些监督字是完全在新的语料上学习到的。
Compositionality in Vector Spaces. (向量空间的组合性) 大多数的组合性算法和相关数据集捕获两个字的组合。Mitchell and Lapata (2010)使用两个字的短语,通过计算向量加法和向量乘法等等来分析相似性。一些相关的模型,如全息减缩表示(Plate,1995年),量子逻辑(Widdows,2008年),离散连续模型(Clark和Pulman,2007年&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









