







 文章详细解释了InnoDB存储引擎如何组织数据页,数据按照主键排序形成链表,以及通过页目录和二分查找提高检索效率。随着数据量增加,使用B+树结构建立索引,实现快速查询,叶子节点存储完整用户数据并以双向链表链接。
文章详细解释了InnoDB存储引擎如何组织数据页,数据按照主键排序形成链表,以及通过页目录和二分查找提高检索效率。随着数据量增加,使用B+树结构建立索引,实现快速查询,叶子节点存储完整用户数据并以双向链表链接。
关于mysql索引思考(innoDB底层)
1、innoDB是如何存储数据的
数据是保存在innoDB页中的(以页作为最小和磁盘交互的单位(也就是我们写入磁盘也叫做持久化))
每页的默认大小为16kb

- 数据页中的数据是如何存储的
用户记录是按照主键由小到大的顺序串联而来的单向链表(innoDB会自动创建infimum最小记录和Supremum最大记录)
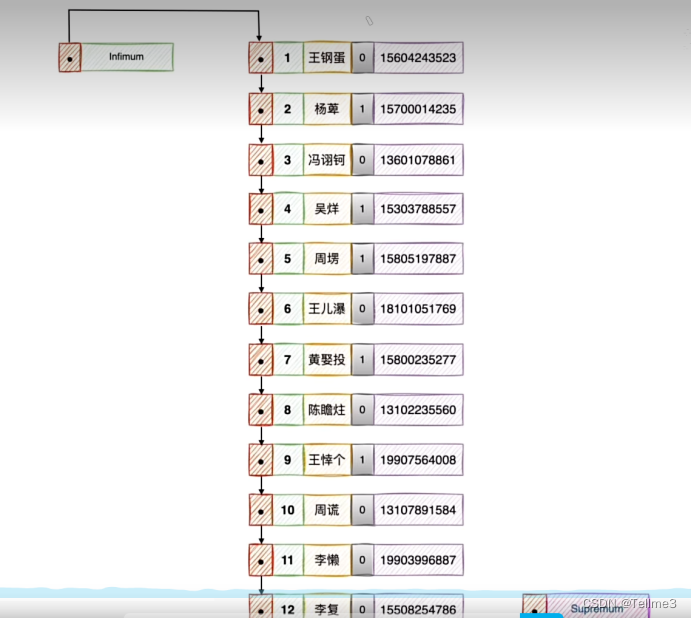
- 当数据页中的数据太多要如何?(遍历时不可能遍历)
3.1 InnoDB将页中的数据分为一个一小组,将小组里面最大的记录作为小组长
3.2(记录小组里面的数据个数,并将小组长的地址拿出来作为一个目录(官方叫槽))
3.3槽在物理空间是连续的(就很好找其中的上一条下一条数据)我们使用二分法来快速查找槽(我们可以将槽想象为每个章节的小结(每个小组是章节))
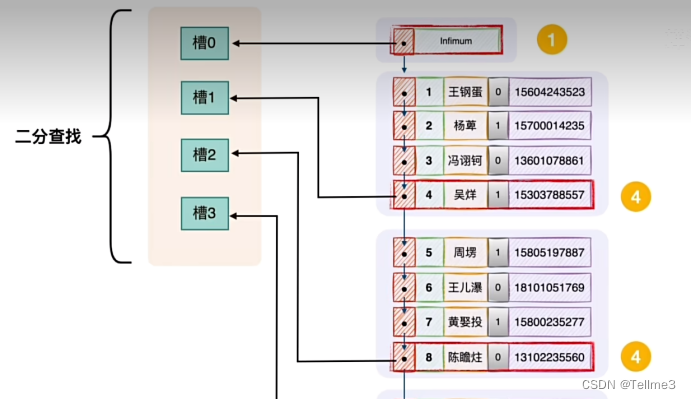
我们可以将槽想象为每个章节的小结(每个页是章节)我们在每一页中查找数据就很快了(每条数据的索引就是小结)
但是我们不知道到底在那个页中查找数据了,所以我们就需要给这些页也建造目录了
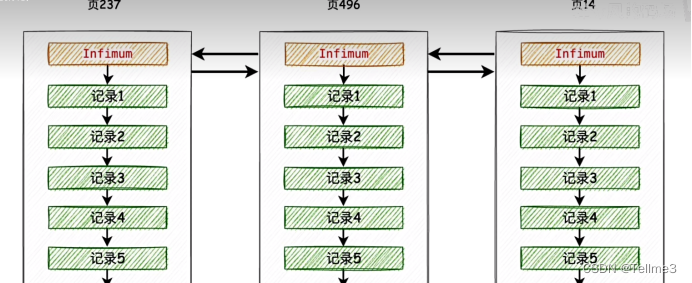
4、各个数据页之间是以双向链表来进行链接的,而每个页里面的数据是单向链表链接的(那每个小组直接也是单向链表链接了)
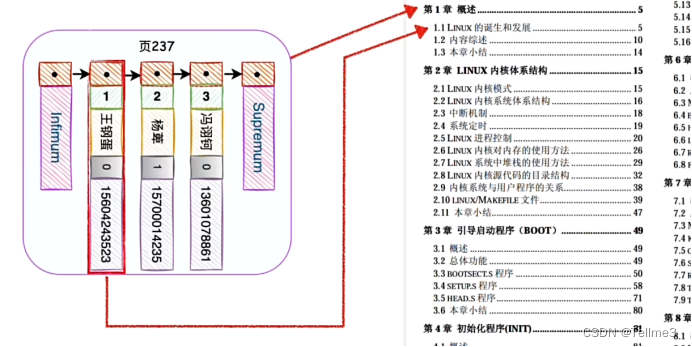
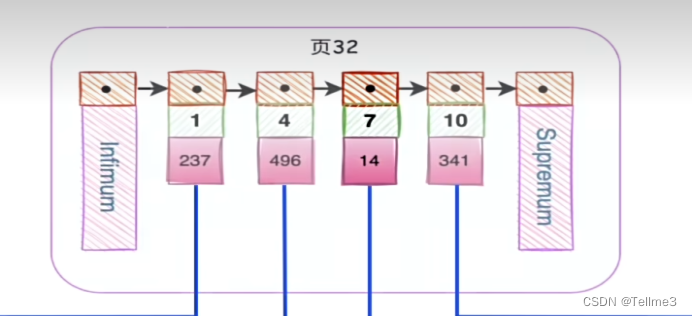
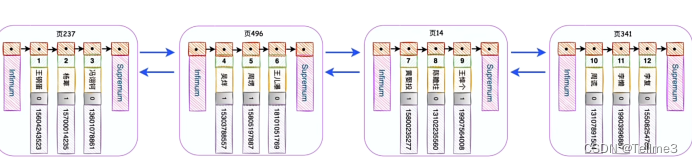 5、如何更快查询到数据?我们给这些分别为这些页建立一个目录(也就是给这个数据页建立一个目录数据项)目录数据项包含两项(1、每页里面数据的最小的主键值2、页号(也就是那一页))
5、如何更快查询到数据?我们给这些分别为这些页建立一个目录(也就是给这个数据页建立一个目录数据项)目录数据项包含两项(1、每页里面数据的最小的主键值2、页号(也就是那一页))
5.1、每页里面数据的最小的主键值(这个顺序排列的方便后面二分查找)
 5.2、页号
5.2、页号
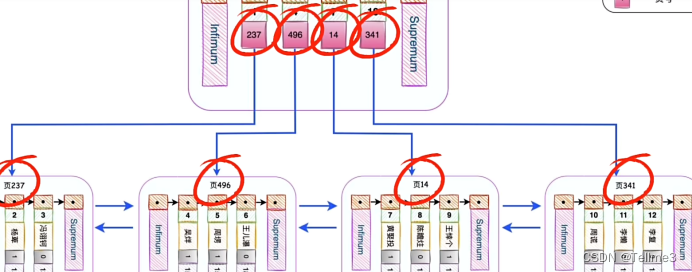
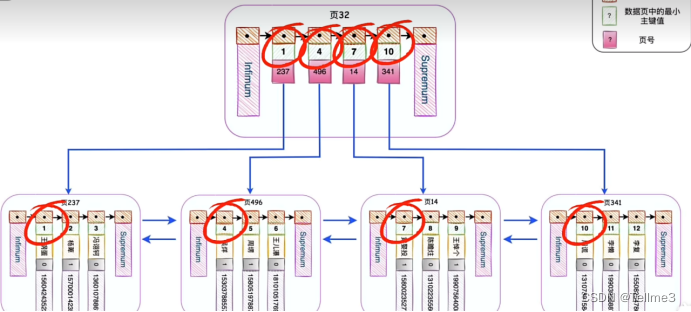
- 我们模拟一下如何查找一个数据(查id为8)
第一步:先查找到目录数据页32
第二步:根据二分法开始定位到7所在的页数14(8比7大嘛)
第三步:再到爷14中进行查找即可
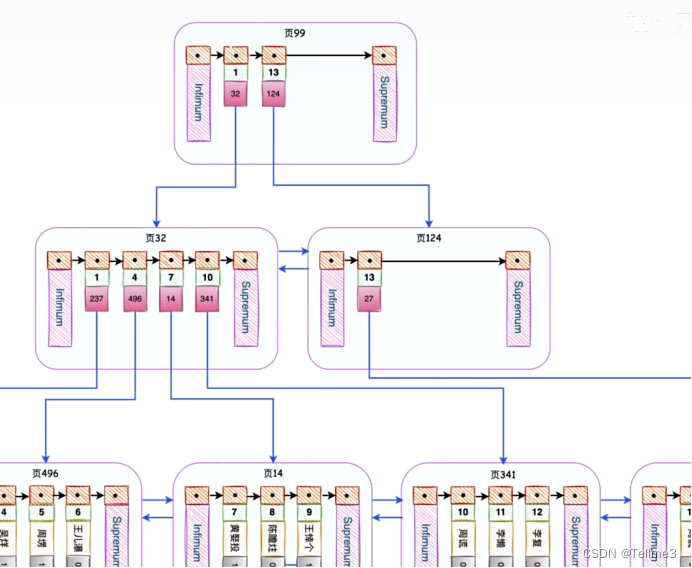
- 我们开始套娃(建树过程),当我们目录页太多,目录记录项也不够用了怎么办?再加目录记录项即可

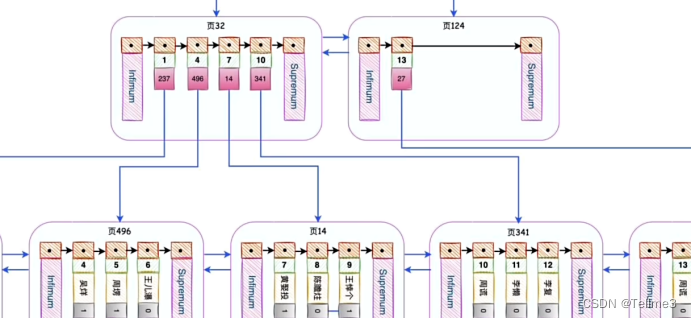
那要是目录记录页也太多了?怎么查找我们再给这个目录记录也添加目录(B+树(索引(主键索引,又叫聚簇索引)))
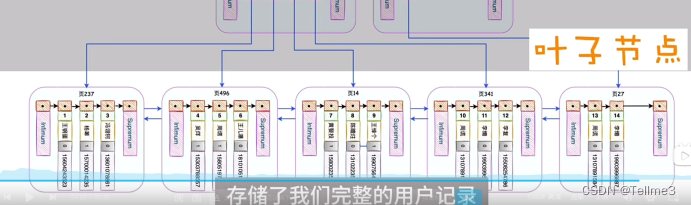
叶子节点存储了我们完整的用户数据(之间的不同页(或者叫不同叶?)用的是双向链表链接,叶子节点的里面的数据用的是单向链表)
特点:


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









