






MySQL的索引有哪些? 主键索引:表的主键列会默认添加索引,索引中保存了该行记录的所有数据唯一索引(upique):该列的所有值必须唯一普通索引(normal):普通列的一种索引聚合索引:是普通索引中的一种,但是它是由多个列组成的索引复制代码 索引怎么用?
假设我们有几张表,如下
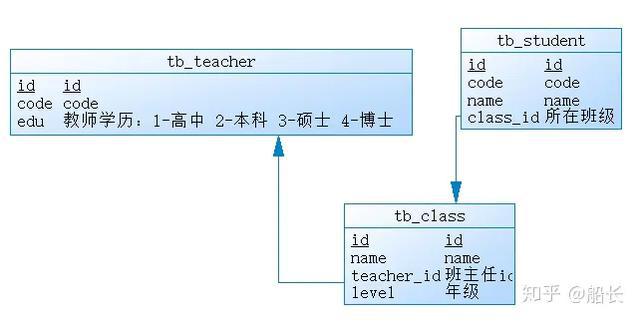
使用navicat设计学生student表,并添加索引如下

1、主键索引
mysql会为每个表的主键自动添加索引,在其索引树的叶子节点中,保存着主键所在行的所有数据,这个后面会讲。也就是说只要找到主键,就代表找到了该行记录,所以使用了主键索引速度会比较快

2、唯一索引
唯一索引对应的列,其数据不可重复,这点相当于主键,不同的是其索引树的叶子节点保存的不是所在行的所有数据,而是该列的值,查询速度比主键慢一些

3、普通索引
普通索引就没什么好说了,其值可以重复,而且索引树叶子节点保存的就是该列的值,而不是整行数据

4、聚合索引
当需要联合几个字段去查询时,使用聚合索引的速度会比多个普通索引快,因为每个索引对应一棵索引树,多个普通索引,虽然都用上了索引,但是要遍历好几个索引树,而使用聚合索引只需遍历一棵索引树

如果对索引树一点了解都没有的同学,可以先看看下面的分析,再回过头来理解一下这四种索引,必然会有焕然一新的感觉
索引的底层结构是什么? 索引底层结构分为全文索引、哈希索引、B+树索引全文索引:只有MyISAM引擎支持,不作介绍哈希索引:计算索引列的hashCode,并将其存在索引中,如果出现冲突,就以链表的形式存储,类似hashMap结构B+树索引:将索引列的值排序,并放入索引树中的指定位置(Mysql默认的索引结构)复制代码 哈希索引的原理
hash是一种key-value形式的数据结构,哈希索引是以索引列的hashCode为键,数据行的地址指针为值形成的一种索引,它是一块非常紧凑的地址空间,可以将其视为数组
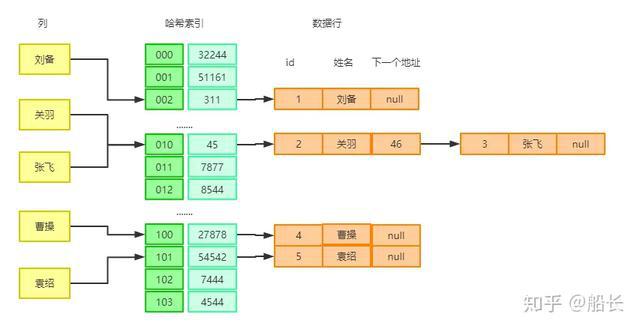
如果我们要查询【刘备】,那么先通过计算哈希码hashCode(刘备)=002得到,然后在哈希索引中找到key=002的位置,那到真正保存数据的磁盘地址311,再去找到数据行。
可见这里查找了两次,第一次是根据hashCode找到地址,第二次是根据地址找到数据行,但是这种查询速度是非常快的,因为它没有去遍历每一条数据行,而是通过hashCode直接找到数据行的磁盘地址。
那如果发生hash冲突怎么办呢?例如关羽和张飞的hashCode都等于010,这时候就会将张飞接在关羽的后面,形成一种链式结构,然后在关羽的下一个地址指针中保存张飞的地址。
当查找【张飞】时,通过hashCode(张飞)=010找到地址45,再通过地址找到了关羽,通过判断姓名【张飞】!=【关羽】,于是通过下一个地址指针46继续查找,第二次就找到了张飞。
这种解决冲突的方式称之为链地址法。所以哈希索引的结构就是数组+链表的形式,与hashMap雷同,但是当冲突太多导致链表很长时,操作数据的时候还是会一直遍历链表才能找到数据,这就会影响性能。
大家可以通过哈希索引的结构,再根据自己平时写sql用到的条件,思考一下他有什么优缺点,我将在文末进行总结。
B+树索引原理
B+树的演变
二叉树 ——> 二叉搜索树 ——> 平衡二叉树 ——> B树 ——> B+树复制代码
在这里对二叉树等结构不做深入介绍,后续的算法章节会详细介绍,只简单介绍B树和B+树。
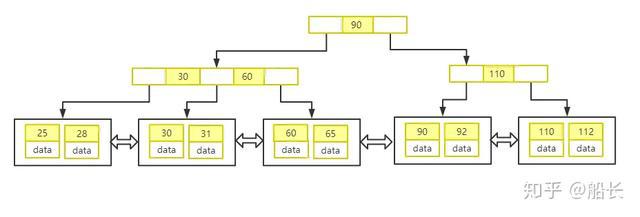
什么是B树?
基本定义:
1、根节点至少有两个子节点
2、叶子节点都在同一高度
3、如果非叶子节点有n个关键字,那么他有n+1个子节点,且这n个节点递增排列
什么是B+树?
B+是由B树演变而来的,所以它具有B树的所有特性,另外还有两点
1、B+树的非叶子节点只存关键字,不存放数据
2、B+树的叶子节点之间用指针相连,是一个双向链表
MySQL中的B+树索引
我们用上面的student表来看B+树是如何存储索引的,假设在student表中添加以下几条数据
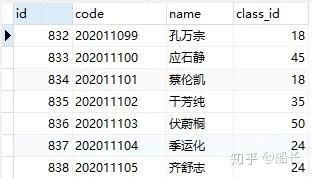
上面我们已经为其添加了索引,现在student中的所有索引如下
id:主键索引,默认创建的code:唯一索引class_id:普通索引name_class:name列和class_id列的聚合索引复制代码
id索引的B+树索引结构如下:
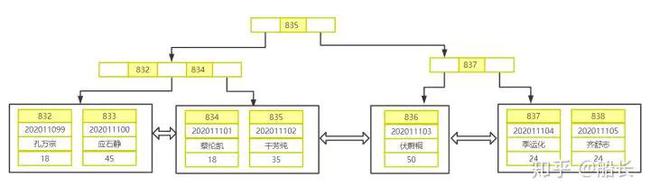
由此可知,主键索引的叶子节点存储了整行的记录,所以使用了主键索引的sql查询速度是非常快的。
唯一索引和普通索引一样,只不过该索引的值是唯一的,不会出现重复值
普通列class_id的索引树如下:
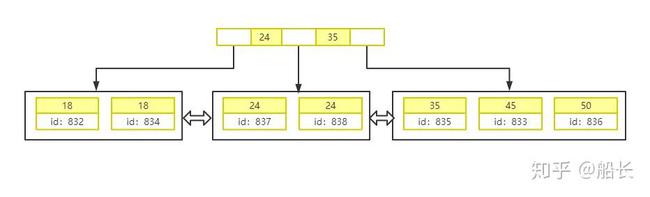
重点来了!重点来了!重点来了!
可见其叶子节点保存的是其行记录中的id,我们看下面两条sql有何不同
sql1:select * from tb_student where class_id=834sql2:select id from tb_student where class_id=834复制代码
看似一样,实则不然。第一条sql查询的是整行记录,而行记录是保存在主键的索引树中的,所以其查询步骤是:根据普通索引class_id的索引树找到叶子节点,获得行记录id,然后根据id去主键索引树中取出整行记录
这个查询过程就称之为回表,可见回表会降低查询效率
而第二条sql查询的就是id,class_id的索引树叶子节点保存的就是id的值,那么不需要去主键索引树取值了,直接将id返回即可,所以效率较前者高。(看到这里大家应该能想到为什么需要聚合索引了)
知其然,知其所以然,必百战百胜。
下面我们再看看聚合索引的树结构:
为了数据能够直观一点,我们新增一个聚合索引
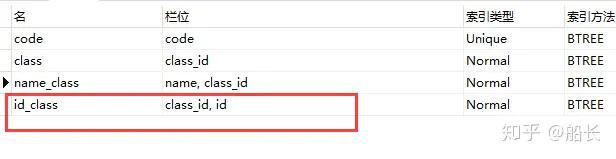
其索引树如下
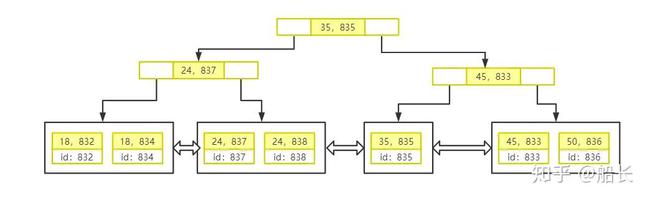
联合索引中的第一个索引是classid,那么索引树会先根据class_id去排序,而后再依次根据后面的索引列排序。所以联合索引的最左原则就可以在此体现了。
SELECT * FROM tb_student where class_id=18 and id=834复制代码
对于上面这条语句,他有两个索引可以走,第一是联合索引id_class,第二个是主键索引id,拿到底会走哪一条呢?答案是主键索引
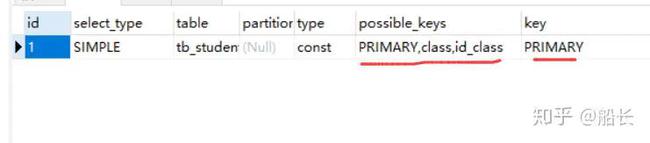
注意:联合索引和主键索引同时存在时,优先走主键索引
为什么呢?这是mysql采用的优化策略,因为主键索引可以直接查出整行数据,所以不管你select *还是select 其他字段我都能满足,而且联合索引且select *时还会涉及到一次回表操作
总结
哈希索引的优缺点
优点:1、查询速度快2、维护索引的成本相对较低缺点:1、无法进行范围查询,因为是通过计算元素的hashCode定位查找的,像age>50这种范围查找是无法使用哈希索引的2、无法通过索引排序,哈希的最大特点就是散列分布,几乎毫无规律,所以无法排序复制代码
B+树索引的优缺点
优点:1、索引树一般2-4层,查询效率高,IO消耗少2、支持各种范围查询3、支持索引排序缺点:1、维护索引树的代价高2、索引太多所占的空间也会变大复制代码
来源:知乎@船长















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









