







5. BufferQueue
BufferQueue要解决的是生产者和消费者的同步问题,应用程序生产画面,SurfaceFlinger消费画面;SurfaceFlinger生产画面而HWC Service消费画面。用来存储这些画面的存储区我们称其为帧缓冲区buffer, 下面我们以应用程序作为生产者,SurfaceFlinger作为消费者为例来了解一下BufferQueue的内部设计。
5.1. Buffer State的切换
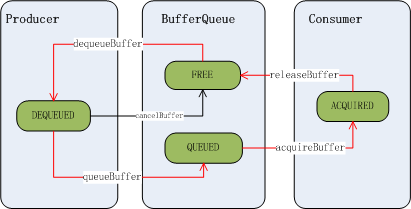
在BufferQueue的设计中,一个buffer的状态有以下几种:
FREE :表示该buffer可以给到应用程序,由应用程序来绘画
DEQUEUED:表示该buffer的控制权已经给到应用程序侧,这个状态下应用程序可以在上面绘画了
QUEUED: 表示该buffer已经由应用程序绘画完成,buffer的控制权已经回到SurfaceFlinger手上了
ACQUIRED:表示该buffer已经交由HWC Service去合成了,这时控制权已给到HWC Service了
buffer的初始状态为FREE, 当生产者通过dequeueBuffer来申请buffer成功时,buffer状态变为了DEQUEUED状态, 应用画图完成后通过queueBuffer把buffer状态改到QUEUED状态, 当SurfaceFlinger通过acquireBuffer操作把buffer拿去给HWC Service合成, 这时buffer状态变为ACQUIRED状态,合成完成后通过releaseBuffer把buffer状态重新改为FREE状态。状态切换如下图所示:
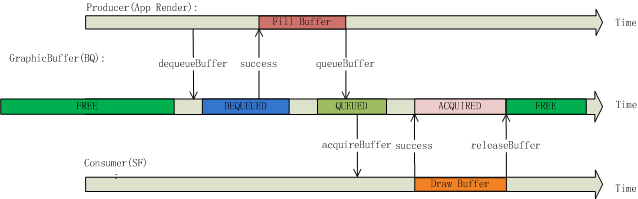
从时间轴上来看一个buffer的状态总是这样循环变化:
FREE->DEQUEUED->QUEUED->ACQUIRED->FREE
应用程序在DEQUEUED状态下绘画,而HWC Service在状态为ACQUIRED状态下做合成:
5.2. BufferSlot
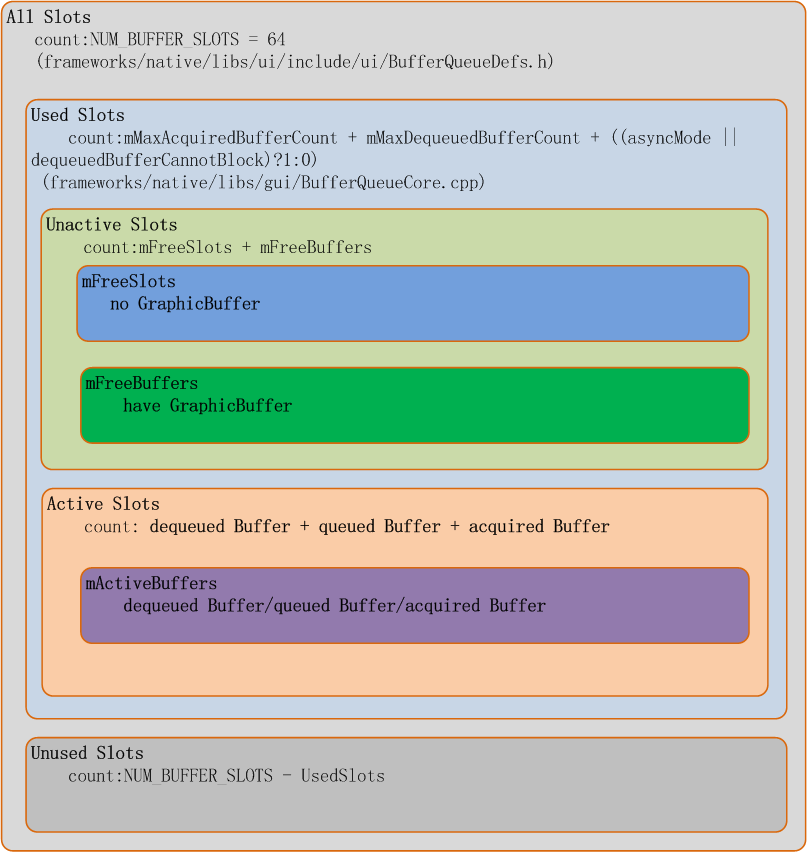
每一个应用程序的图层在SurfaceFlinger里称为一个Layer, 而每个Layer都拥有一个独立的BufferQueue, 每个BufferQueue都有多个Buffer,Android 系统上目前支持每个Layer最多64个buffer, 这个最大值被定义在frameworks/native/gui/BufferQueueDefs.h, 每个buffer用一个结构体BufferSlot来代表。
每个BufferSlot里主要有如下重要成员:
struct BufferSlot{
......
BufferState mBufferState;//代表当前Buffer的状态 FREE/DEQUEUED/QUEUED/ACQUIRED
....
sp<GraphicBuffer> mGraphicBuffer;//代表了真正的buffer的存储空间
......
uint64_t mFrameNumber;//表示这个slot被queued的编号,在应用调dequeueBuffer申请slot时会参考该值
......
sp<Fence> mFence;//在Fence一章再来看它的作用
.....
}64个BufferSlot可以分成两个部分,used Slots和Unused Slots, 这个比较好理解,就是使用中的和未被使用的,而Used Slots又可以分为Active Slots和UnActive Slots, 处在DEQUEUED, QUEUED, ACQUIRED状态的被称为Active Slots, 剩下FREE状态的称为UnActive Slots, 所以所有Active Slots都是正在有人使用中的slot, 使用者可能是生产者也可能是消费者。而FREE状态的Slot根据是否已经为其分配过内存来分成两个部分, 一是已经分配过内存的,在Android源码中称为mFreeBuffers, 没有分配过内存的称为mFreeSlots, 所以如果我们在代码中看到是从mFreeSlots里拿出一个BufferSlot那说明这个BufferSlot是还没有配置GraphicBuffer的, 这个slot可能是第一次被使用到。其分类如下图所示:
我们来看一下,应用上帧时SurfaceFlinger是如何管理分配这些Slot的。
应用侧对图层buffer的操作接口是如下文件:
frameworks/native/libs/gui/Surface.cpp
应用第一次dequeueBuffer前会通过connect接口和SurfaceFlinger建立“连接”:
int Surface::connect(int api, const sp<IProducerListener>&listener, bool reportBufferRemoval){
ATRACE_CALL();//应用第一次上帧前可以在trace 中看到这个
......
int err = mGraphicBufferProducer->connect(listener, api, mProducerControlledByApp, &output);//这里通过binder调用和SurfaceFlinger建立联系
......
}应用在第一次dequeueBuffer时会先调用requestBuffer:
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();//这里可以在systrace中看到
......
//这里尝试去dequeueBuffer,因为这时SurfaceFlinger对应Layer的slot还没有分配buffer,这时SurfaceFlinger会回复的flag会有BUFFER_NEEDS_REALLOCATION
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps?&frameTimestamps:nullptr);
......
if((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) {
......
//这里检查到dequeueBuffer返回的结果里带有BUFFER_NEEDS_REALLOCATION标志就会发出一次requestBuffer
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
......
}
......
}在SurfaceFlinger这端,第一次收到dequeueBuffer时发现分配出来的slot没有GraphicBuffer, 这时会去申请对应的buffer:
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
if ((buffer == NULL) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))//检查是否已分配了GraphicBuffer
{
......
returnFlags |= BUFFER_NEEDS_REALLOCATION;//发现需要分配buffer,置个标记
}
......
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
......
//新创建一个新的GraphicBuffer给到对应的slot
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
......
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;//把GraphicBuffer给到对应的slot
......
}
......
return returnFlags;//注意在应用第一次请求buffer, dequeueBuffer返回时对应的GraphicBuffer已经创建完成并给到了对应的slot上,但返回给应用的flags里还是带有BUFFER_NEEDS_REALLOCATION标记的
}应用侧收到带有BUFFER_NEEDS_REALLOCATION标记的返回结果后就会调requestBuffer来获取对应buffer的信息:
status_t BufferQueueProducer::requestBuffer(int slot, sp<GraphicBuffer>* buf) {
ATRACE_CALL();
......
mSlots[slot].mRequestBufferCalled = true;
*buf = mSlots[slot].mGraphicBuffer;
return NO_ERROR;
}从上面可以看出requestBuffer的主要作用就是把GraphicBuffer传递到应用侧,这里思考一个问题,既然SurfaceFlinger在响应dequeueBuffer时就已经为slot新创建了GraphicBuffer, 为什么还需要应用侧再次调用requestBuffer时再把GraphicBuffer传给应用呢? 为什么dequeueBuffer不直接返回呢?这不是多花费一次跨进程通信的时间吗? 为什么设计成了这个样子呢?
我们再来看一下应用侧接口dequeueBuffer的函数设计:
frameworks/native/libs/gui/IGraphicBufferProducer.h
virtual status_t dequeueBuffer(int* buf, sp<Fence>* fence, uint32_t width, uint32_t height,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps);注意第一个参数只是返回一个int值,它表示的是64个slot里的哪一个slot, 其他参数里也不会返回这个slot所对应的GraphicBuffer的信息,但这个slot拿到应用侧后,应用是要拿到确确实实的GraphicBuffer才能把共享内存mmap到自已进程空间,才能在上面绘画。而显然这个接口的设计并不会带来GraphicBuffer的信息,那设计之初为什么不把这个信息放进来呢? 因为这个接口调用太频繁了,比如在90FPS的设备上,一秒钟该接口要执行90次,太频繁了,而且这个信息只需要传递一次就可以了,如果每次这个接口都要带上GraphicBuffer的信息,传输了很多冗余数据,所以不如加入一个新的api(requestBuffer)来完成GraphicBuffer传递的事情.
应用侧在requestBuffer后会拿到GraphicBuffer的信息,然后会通过importBuffer在本进程内通过binder传过来的parcel包把GraphicBuffer重建出来:
frameworks/native/libs/ui/GraphicBuffer.cpp
status_t GraphicBuffer::unflatten(
void const*& buffer, size_t& size, int const*& fds, size_t& count) {
......
if (handle != 0) {
buffer_handle_t importedHandle;
//获取从SurfaceFlinger传过来的buffer
status_t err = mBufferMapper.importBuffer(handle, uint32_t(width), uint32_t(height),
uint32_t(layerCount), format, usage, uint32_t(stride), &importedHandle);
......
}
......
}如下图所示,从App侧看,前三帧都会有requestBuffer, 都会有importBuffer,在第4帧时就没有requestBuffer/importBuffer了,因为我们当前系统一共使用了三个buffer,从systrace上可以看到这个区别:

当一个surface被创建出来开始上帧时其流程如下图所示,应用所使用的画布是在前三帧被分配出来的,从第四帧开始进入稳定上帧期,这时会重复循环利用前三次分配的buffer。
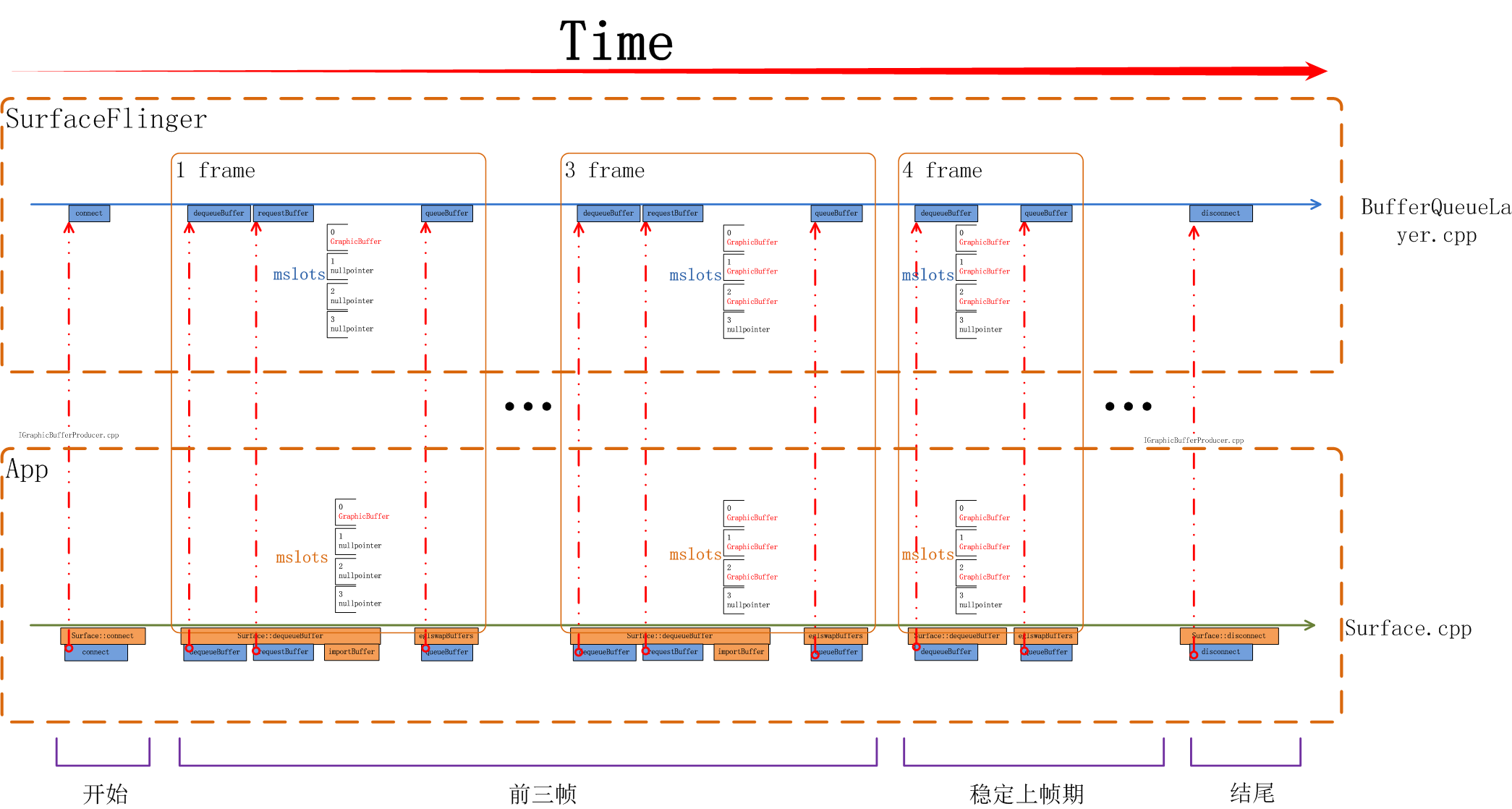
思考一个问题,在三个buffer的系统中一定是前三帧中触发分配GraphicBuffer吗? 如果某个应用有一个SurfaceView自已决定上帧的帧率,而这个帧率非常低,如低到一秒一帧,那前三秒会把三个Buffer分配出来吗?我们需要了解一下多buffer下SurfaceFlinger的管理策略是什么。
5.3. Buffer管理
前文提到了每个图层Layer都有最多64个BufferSlot, 如下图所示,每个BufferSlot都会记录有自身的状态(BufferState),以及自已的GraphicBuffer指针mGraphicBuffer.

但不是每个Layer都能使用到那么多,每个Layer最多可使用多少个Layer是在这里设置的:
frameworks/native/services/surfaceflinger/BufferQueueLayer.cpp
void BufferQueueLayer::onFirstRef() {
......
// BufferQueueCore::mMaxDequeuedBufferCount is default to 1
if (!mFlinger->isLayerTripleBufferingDisabled()) {
mProducer->setMaxDequeuedBufferCount(2);//3 buffer时这里设为2, 是因为在BufferQueueCore那里会+1
}
......
}我们重新回忆下BufferSlot的几个状态,FREE ,代表该buffer可以给到应用程序,由应用程序来绘画, 这样的Slot SurfaceFlinger会根据是否有给它分配有GraphicBuffer分到两个队列里, 有GraphicBuffer的分配到mFreeBuffers里, 没有GraphicBuffer的分配到mFreeSlots里; 当应用申请走一个Slot时,该Slot状态会切换到DEQUEUED状态,该Slot会被放入mActiveBuffers队列里; 当应用绘画完成后Slot状态会切到QUEUED状态,所有QUEUED状态的Slot会被放入mQueue队列里; 当一个Slot被HWC Service拿去合成后状态会变为ACQUIRED, 这个Slot会被从mQueue队列中取出放入mActiveBuffers队列里;
我们先来看一个BufferSlot管理的场景:
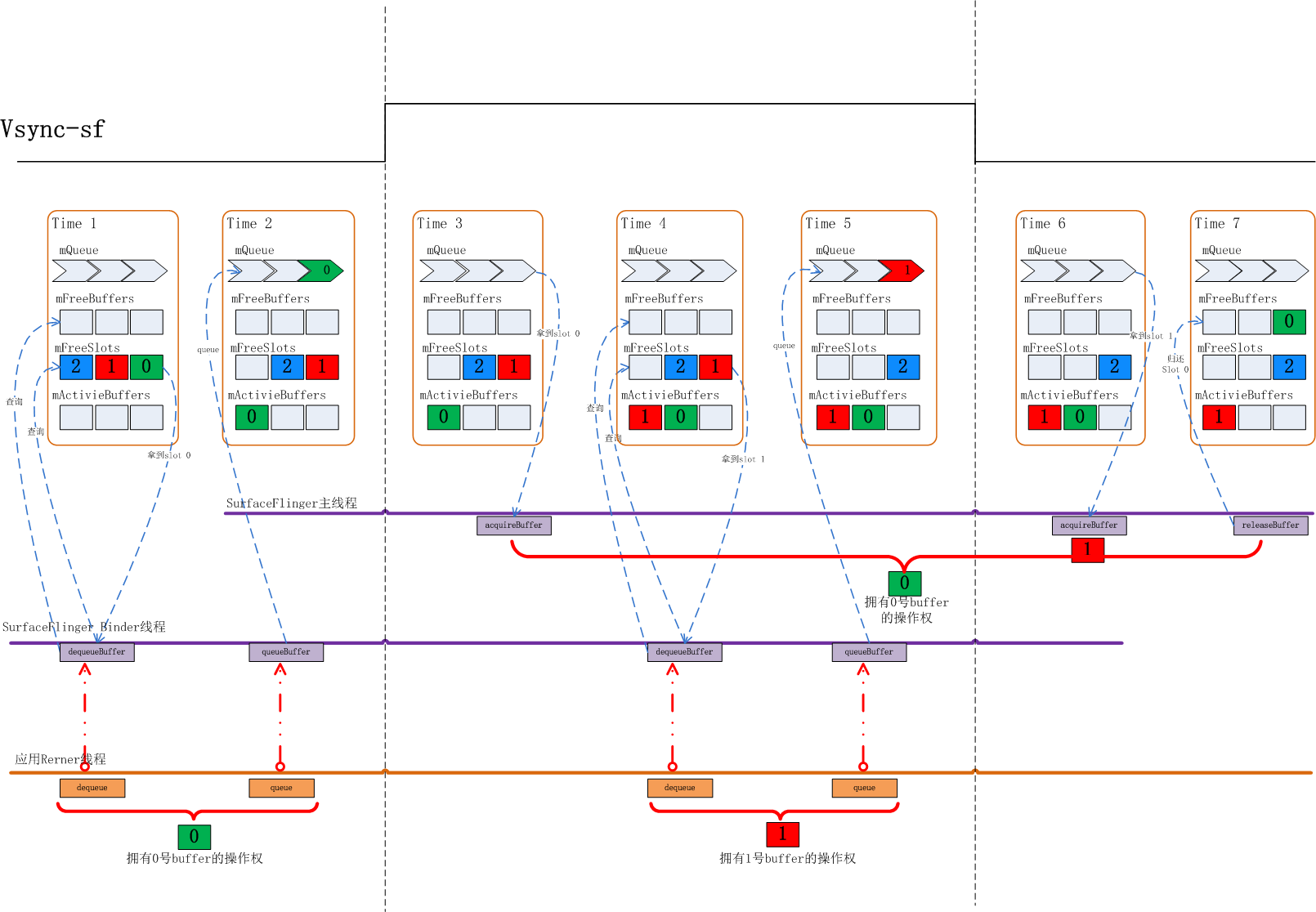
Time1: 在上图中,初始状态下,有0, 1, 2这三个BufferSlot, 由于它们都没有分配过GraphicBuffer, 所以它们都位于mFreeSlots队列里,当应用来dequeueBuffer时,SurfaceFlinger会先检查在mFreeBuffers队列中是否有Slot, 如果有则直接分配该Slot给应用。显然此时mFreeBuffers里是空的,这时Surfaceflinger会去mFreeSlots里去找出第一个Slot, 这时就找到了0号Slot, dequeueBuffer结束时应用就拿到了0号Slot的使用权,于此同时SurfaceFlinger也会为0号Slot分配GraphicBuffer, 之后应用将通过requestBuffer和importBuffer来获取到该Slot的实际内存空间。
应用dequeueBuffer之后0号Slot切换到DEQUEUED状态,并被放入mActiveBuffers列表。
Time2:应用完成绘制后通过queueBuffer来提交绘制好的画面,完成后0号Slot状态变为QUEUED状态,放入mQueue队列,此时1,2号Slot还停留在mFreeSlots队列中。
Time3: 上面这个状态会持续到下一个Vsync-sf信号到来,当Vsync-sf信号到来时,SurfaceFlinger主线程会检查mQueue队列中是否有Slot, 有就意味着有应用上帧,这时它会把该Slot从mQueue中取出放入mActiveBuffers队列,并将Slot的状态切换到ACQUIRED, 代表这个Slot已被拿去做画面合成。那么这之后0号Slot被从mQueue队列拿出放入mActivieBuffers里。
Time4:接下来应用继续调用dequeueBuffer申请buffer, 此时0号Slot在mActiveBuffers里,1,2号在mFreeSlots里,SurfaceFlinger仍然是先检查mFreeBuffers里有没有Slot, 发现还是没有,再检查mFreeSlots里是否有,于是取出了1号Slot给到应用侧,同时1号Slot状态切换到DEQUEUED状态, 放入mActiveBuffers里,
Time5:1号Slot应用绘画完毕,通过queueBuffer提交上来,这时1号Slot状态由DEQUEUED状态切换到了QUEUED状态,进入mQueue队列,之后将维持该状态直到下一个Vsync-sf信号到来。
Time6: 此时Vsync-sf信号到来,发现mQueue中有个Slot 1, 这时SurfaceFlinger主线程会把它取出,把状态切换到ACQUIRED, 并放入mActiveBuffers里。
Time7:这时0号Slot HWC Service使用完毕,通过releaseBuffer还了回来,0号Slot的状态将从ACQUIRED切换回FREE, Surfaceflinger会把它从mActivieBuffers里拿出来放入mFreeBuffers里。注意这时放入的是mFreeBuffers里而不是mFreeSlots里,因为此时0号Slot是有GraphicBuffer的。
在上述过程中SurfaceFlinger收到应用dequeueBuffer请求时处在FREE状态的Slot都还没有分配过GraphicBuffer, 由之前的讨论我们知道这通常发生在一个Surface的前几帧时间内。如3 buffer下的前三帧。
我们再来看一下申请buffer时mFreeBuffers里有Slot时的情况:
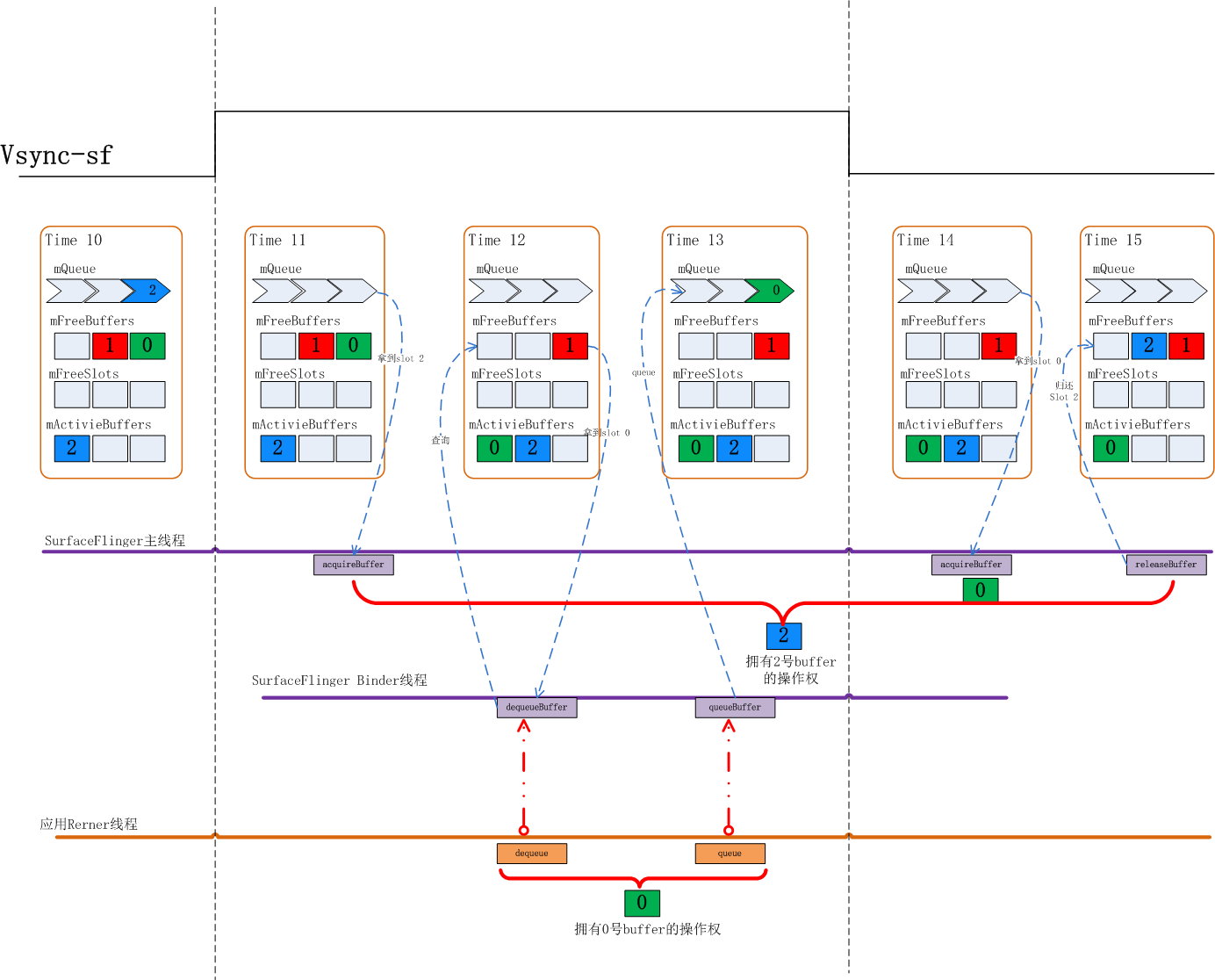
Time11:当下的状态是0,1两个Slot都在mFreeBuffers里,2号Slot在mActiveBuffers里,这时应用来dequeueBuffer
Time12: SurfaceFlinger仍然会先查看mFreeBuffers列表看是否有可用的Slot, 发现0号可用,于是0号Slot状态由FREE切换到DEQUEUED状态,并被放入mActiveBuffers里
Time13:应用对0号Slot的绘图完成后提交上来,这时状态从DEQUEUED切换到QUEUED状态,0号Slot被放入mQueue队列,之后会维持该状态直到下一下Vsync-sf信号到来
Time14:这时Vsync-sf信号到来,SurfaceFlinger主线程中检查mQueue队列中是否有Slot, 发现0号Slot, 于是通过 aquireBuffer操作把0号Slot状态切换到ACQUIRED
这个过程中应用申请buffer时已经有处于FREE状态的Slot是分配过GraphicBuffer的,这种情况多发生在Surface的稳定上帧期。
再来关注一下acquireBuffer和releaseBuffer的过程:
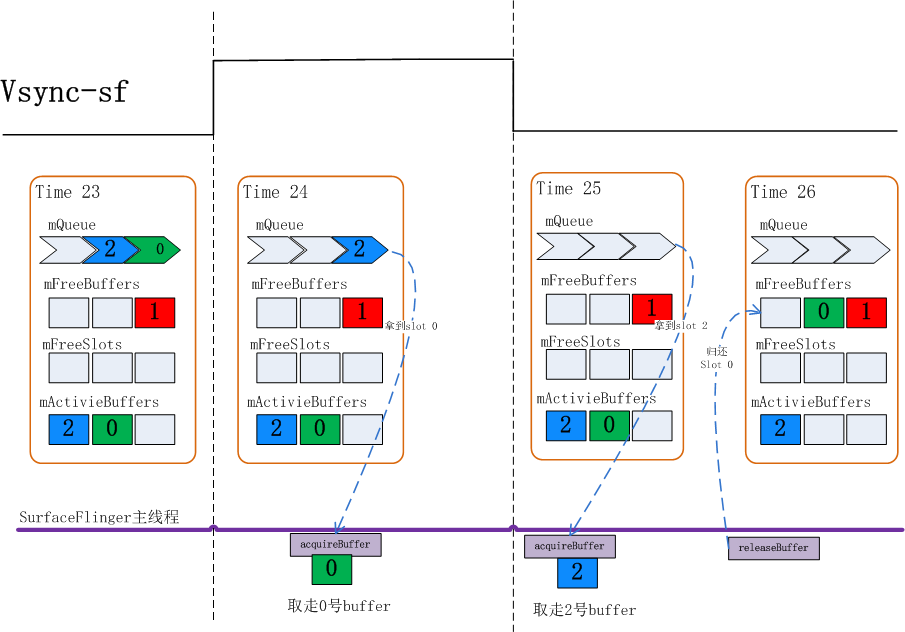
Time 23: 当前状态mQueue里有两个buffer
Time 24:Vsync-sf信号到达,从mQueue队列里取走了0号Slot,
Time 25: 再一次Vsync-sf到来,这时SurfaceFlinger会先查看mQueue队列是否有buffer,发现有2号Slot, 会先取走2号Slot
Time 26: 此时0号Slot已经被HWC Service使用完毕,需要把Slot还回来,0号Slot在此刻进入mFreeBuffers队列。
这里需要注意的是两个时序:
每次Vsync-sf信号到来时总是先查看mQueue队列看是否有Layer上帧,然后才会走到releaseBuffer把HWC Service使用的Slot回收回来
本次Vsync-sf被aquireBuffer取走的Slot总是会在下一个Vsync-sf时才会被release回来
由上述过程不难看出,如果应用上帧速度较慢,比如其上帧周期时长大于两倍屏幕刷新周期时,每次应用来dequeueBuffer时前一次queueBuffer的BufferSlot都已经被release回来了,这时总会在mFreeBuffers里找到可用的,那么就不需要三个Slot都分配出GraphicBuffer.
在应用上帧过程中所涉及到的BufferSlot我们可以通过systrace来观察:
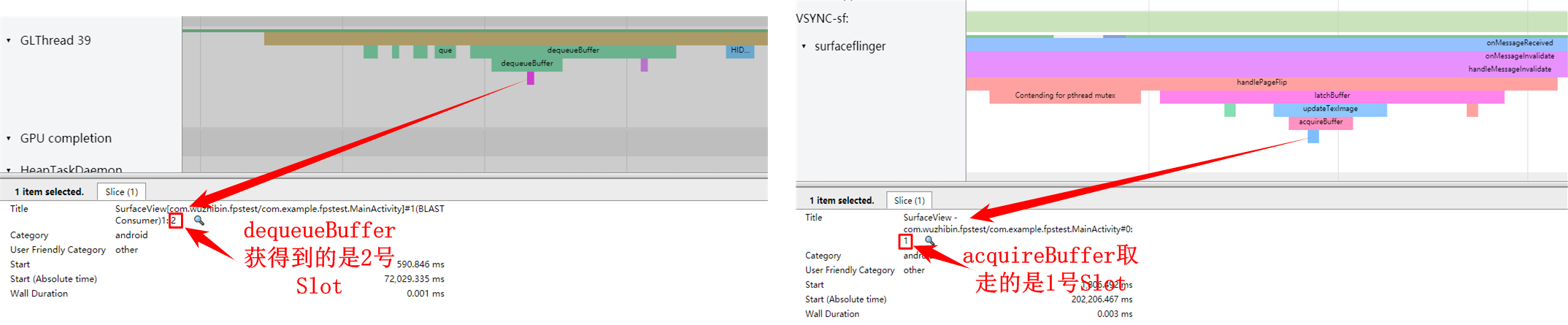
这两个图中显示可以从systrace中看到每次dequeueBuffer和acquireBuffer所操作到的Slot是哪个,当然releaseBuffer也可以在systrace上找到:

从trace里我们还应注意到,releaseBuffer是在postComposition里调用到的,这段代码如下:
frameworks/native/services/surfaceflinger/surfaceflinger.cpp
void SurfaceFlinger::postComposition(){
ATRACE_CALL();
......
for(auto& layer:mLayersWithQueuedFrames){//这里只要主线程执行到这个postComposition函数就一定会让集合中的layer去执行releasePendingBuffer, 而这个releasePendingBuffer里就会调用到releaseBuffer
layer->releasePendingBuffer(dequeueReadyTime);
}
......
}mLayersWithQueuedFrames里的Layer是在这里被加入进来的:
bool SurfaceFlinger::handlePageFlip(){
......
mDrawingState.traverse([&](Layer* layer){
.......
if(layer != nullptr && layer->hasReadyFrame()){//这里是判断这个Layer是否有buffer更新,也就是mLayersWithQueuedFrames里放的是有上帧的layer
......
mLayersWithQueuedFrames.push_back(layer);
......
}
.......
});
......
}在Layer的releasePendingBuffer里会把对应的Slot的状态切到FREE状态,切换到FREE状态后,是很可能被应用dequeueBuffer获取到的,那么怎么能确定buffer已经被HWC Service使用完了呢?如果HWC Service还没有使用完成,而应用申请到了这个buffer,buffer中的数据会出错,怎么解决这个问题呢,这就要靠我们下一章要讨论的Fence来解决。
我们再从帧数据更新的流程上来看下bufferSlot的管理,从systrace(屏幕刷新率为90HZ)上可以观察到的应用上帧的全景图:
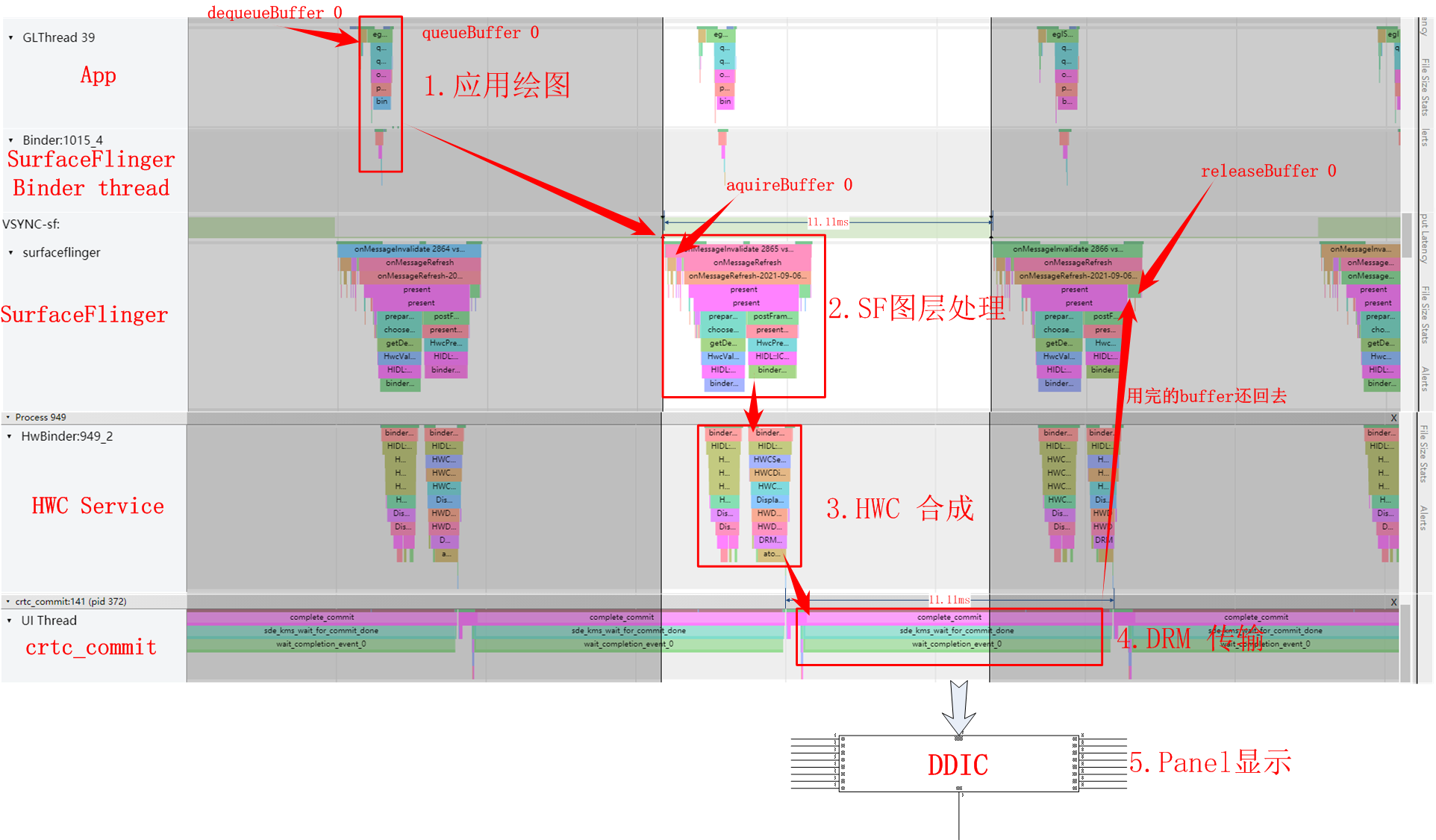
首先应用(这里是以一个SurfaceView上帧为例)通过dequeueBuffer拿到了BufferSlot 0, 开始第1步绘图,绘图完成后通过queueBuffer将Slot 0提交到SurfaceFlinger, 下一个Vsync-sf信号到达后,开始第2步图层处理,这时SurfaceFlinger通过aquireBuffer把Slot 0拿去给到HWC Service,与此同时进入第3步HWC Service开始把多个图层做合成,合成完成后通过libdrm提供的接口通知DRM模块通过DSI传输给DDIC, Panel 通过Disp Scan Gram把图像显示到屏幕。
5.4. 代码接口
以应用为生产者SurfaceFlinger为消费者为例,BufferQueue的Slot管理核心代码如BufferQueueCore、BufferQueueProducer、BufferQueueConsumer组成, 生产者这边还有一个Surface它是应用侧操作BufferQueue的接口:
相关代码路径如下:
Surface.cpp (frameworks\native\libs\gui)
BufferQueueCore.cpp (frameworks\native\libs\gui)
BufferQueueProducer.cpp (frameworks\native\libs\gui)
BufferQueueConsumer.cpp (frameworks\native\libs\gui)
IGraphicBufferProducer.cpp (frameworks\native\libs\gui)
IGraphicBufferConsumer.cpp (frameworks\native\libs\gui)
IConsumerListener.h (frameworks\native\libs\gui\include\gui)由于Android规定,BufferQueue的buffer必须是在Consumer侧来分配,所以BufferQueue的核心Slot管理代码是在SurfaceFlinger进程空间内执行的,它们关系可以用如下图来表示:
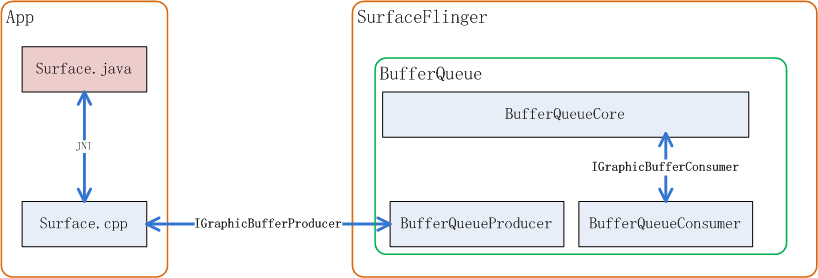
相关代码路径:
IGraphicBufferProducer用来规定了BufferQueue向生产者提供的接口有哪些,比如请求buffer用到的dequeueBuffer, 提交buffer用到的queueBuffer等等:
class IGraphicBufferProducer : public RefBase {
......
virtual status_t connect(const sp<IProducerListener>& listener,
int api, bool producerControlledByApp, QueueBufferOutput* output) = 0;
virtual status_t requestBuffer(int slot, sp<GraphicBuffer>* buf) = 0;
virtual status_t dequeueBuffer(int* slot, sp<Fence>* fence, uint32_t w, uint32_t h,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) = 0;
virtual status_t queueBuffer(int slot, const QueueBufferInput& input,
QueueBufferOutput* output) = 0;
virtual status_t disconnect(int api, DisconnectMode mode = DisconnectMode::Api) = 0;
......
}connect接口是在开始时上帧前调用一次,主要用来让生产者和消费者沟通一些参数,比如api 版本,buffer的尺寸,个数等; disconnect用于在生产者不再生产断开连接,用以通知消费端清理一些资源。
IGraphicBufferConsumer则规定了消费者和BufferQueueCore的接口有哪些,比如查询从mQueue队列中取出buffer,和还buffer到BufferQueue:
class IGraphicBufferConsumer : public RefBase {
......
virtual status_t acquireBuffer(BufferItem* buffer, nsecs_t presentWhen,
uint64_t maxFrameNumber = 0) = 0;
virtual status_t releaseBuffer(int buf, uint64_t frameNumber, EGLDisplay display,
EGLSyncKHR fence, const sp<Fence>& releaseFence) = 0;
......
}5.5. 本章小结
让我们用一张图来总结说明一下在Triple Buffer下应用连续上帧过程中三个buffer的使用情况,以及在此过程中应用, SurfaceFlinger是如何配合的:
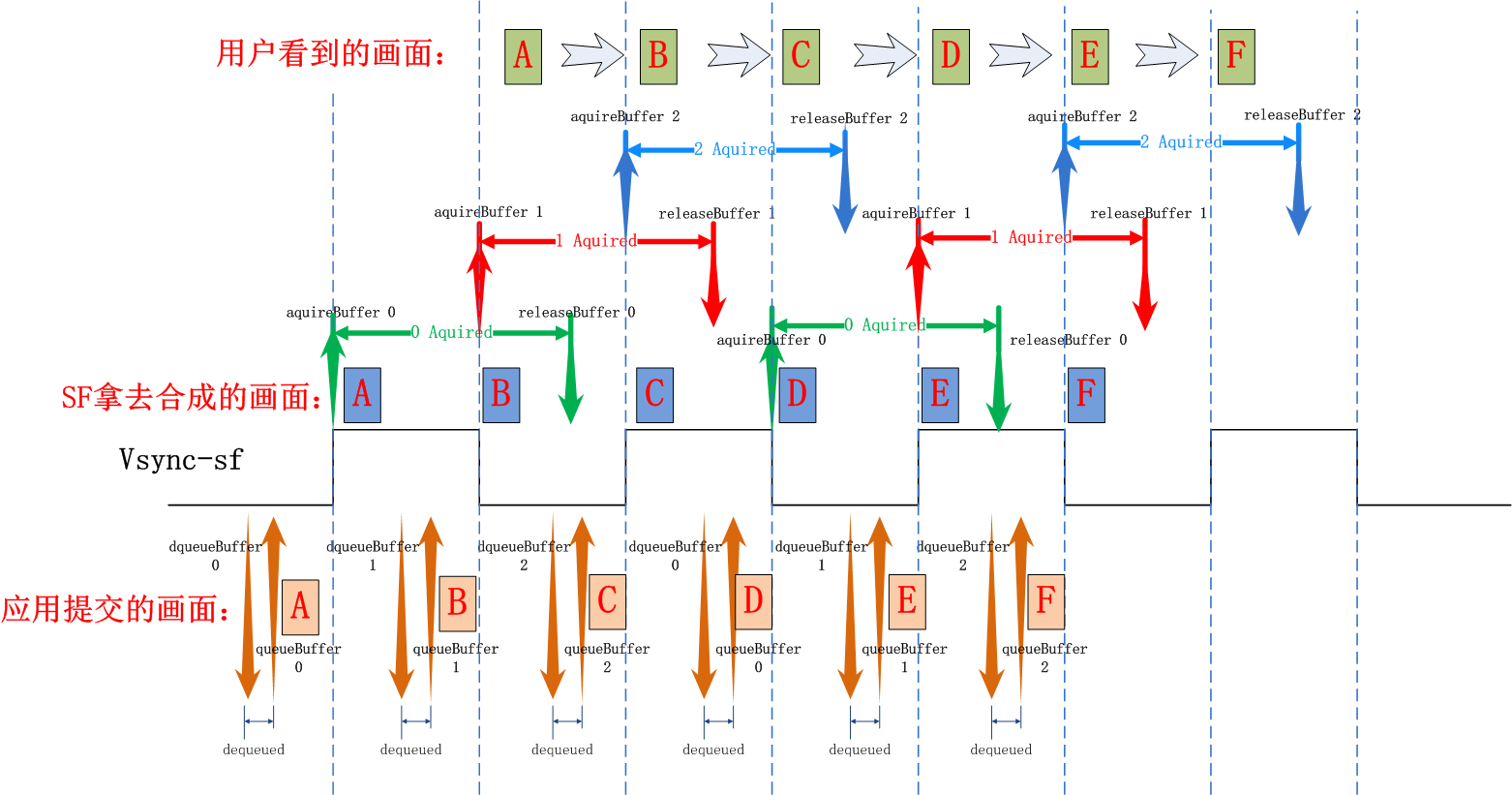
应用在每个Vsync信号到来后都会通过dequeueBuffer/queueBuffer来申请buffer和提交绘图数据,Surfaceflinger都会在下一个vsync信号到来时取走buffer去做合成和显示, 并在下一下个vsync时将buffer还回来,再次循环。
6. Fence
Fence这个英文单词通常代表栅栏,篱笆,围墙,代表了此处是否可以通行。它是内核提供的不同硬件间同步机制,在userspace层我们可以将它视为是一把锁,它代表了某个硬件对共享资源的占用情况。
6.1. 为什么要有Fence
一般凡是共享的资源都要建立一个同步机制来管理,比如在多线程编程中对临界资源的通过加锁实现互斥访问,再比如BufferQueue中Surfaceflinger和应用对共享内存(帧缓冲)的访问中有bufferstate来标识共享内存控制权的方法来做同步。没有同步机制的无序访问极可能造成数据混乱。
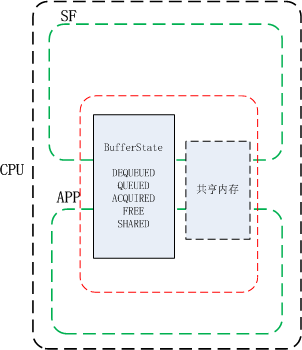
上面图中的BufferState的方式只是解决了在CPU管理之下,当下共享内存的控制权归属问题,但当共享资源是在两个硬件之中时,情况就不同了,比如当一个帧缓冲区共享内存给到GPU时,GPU并不清楚CPU还有没有在使用它,同样地,当GPU在使用共享内存时,CPU也不清楚GPU是否已使用完毕,如下面这个例子:
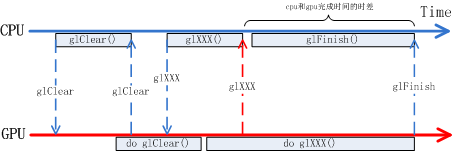
CPU调用OpenGL函数绘图过程的一个简化版流程如上图所示,首先CPU侧调用glClear清空画布,再调用glXXX()来画各种各样的画面,对于CPU来讲在glXXX()执行完毕后,它的绘图工作已经完成了。但其实glXXX()的具体工作是由GPU来完成的,CPU侧的glXXX()只是在向GPU传达任务而已,任务传达完并不意味着任务已经完成了。真正任务做完是在GPU把glXXX()所对应的工作做完才是真正的任务完成了。从CPU下达完任务到GPU完成任务间存在时差,而且这个时差受GPU工作频率影响并不是一个定值。在OpenGL的语境中CPU可以通过glFilish()来等待GPU完成所有工作,但这显然浪费了CPU本可以并行工作的时间,这段时间CPU没有用来做别的事情。
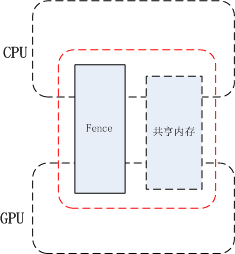
在上面的例子中CPU下达了要在画布上绘画的指令给GPU, 而GPU什么时候画完时间是不确定的,这里的画布就是共享资源,CPU和GPU的工作完全是异步的。Fence提供了一种方式来处理不同硬件对共享资源的访问控制。
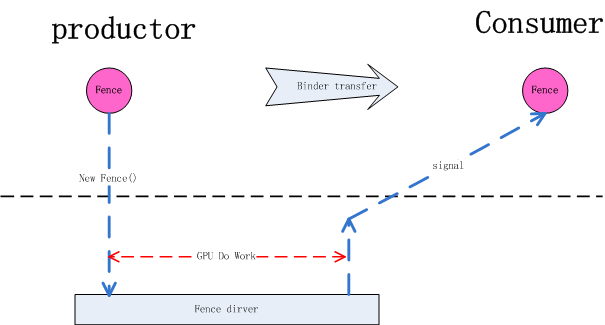
我们可以这样来理解Fence的工作原理: Fence是一个内核driver, 对一个Fence对象有两种操作, signal和wait, 当生产者(App)向GPU下达了很多绘图指令(drawCall)后GPU开始工作,这里CPU就认为绘图工作已经完成了,之后把创建的Fence对象通过binder通知给消费者(SurfaceFlinger),SurfaceFlinger收到通知后,此时SurfaceFlinger并不知道GPU是否已经绘图完毕,即GPU是否已对共享资源访问完毕,消费者先通过Fence对象的wait方法等待,如果GPU绘图完成会调用Fence的signal, 这时消费者就会从Fence对象的wait方法中跳出。即wait方法结束时就是GPU工作完成时。这个signal由kernel driver来完成。有了Fence的情况下,CPU在完成自已的工作后就可以继续做别的事情,到了真正要使用共享资源时再通过Fence wait来和GPU同步,尽最大可能做到了让不同硬件并行工作。
6.2. 与BufferQueue协作方式
我们以App(productor)和SurfaceFlinger(Consumer)间的交互来看下Fence在其中的作用:
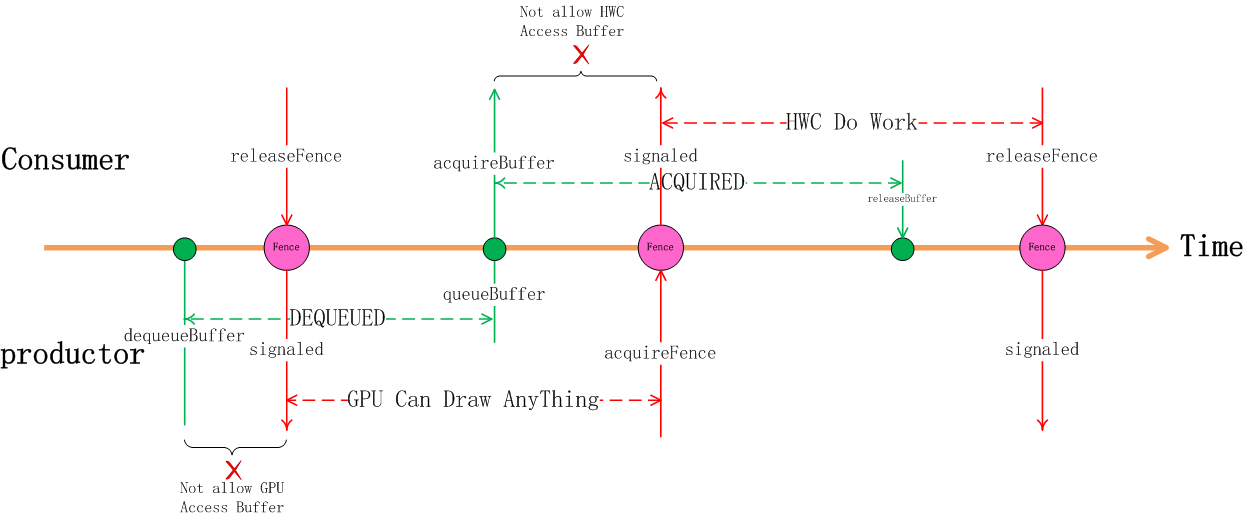
首先App通过dequeueBuffer获得某一Slot的使用权,这时Slot的状态切换到DEQUEUED状态,随着dequeueBuffer函数返回的还有一个releaseFence对象,这时因为releaseFence还没有signaled, 这意味着虽然在CPU这边已经拿到了buffer的使用权,但别的硬件还在使用这个buffer, 这时的GPU还不能直接在上面绘画,它要等releaseFence signaled后才能绘画。 接下来我们先假设GPU的工作花费的时间较长,在它完成之前CPU侧APP已经完成了queueBuffer动作,这时Slot的状态已切换为QUEUED状态,或者vsync已经到来状态变为ACQUIRED状态, 这在CPU侧代表该buffer给HWC去合成了,但这时HWC的硬件MDP还不能去读里面的数据,它还需要等待acauireFence的signaled信号,只有等到了acquireFence的signaled信号才代表GPU的绘画工作真正做完了,GPU已经完成了对帧缓冲区的访问,这时HWC 的硬件才能去读帧缓冲区的数据,完成图层合成的工作。
同样地,当SurfaceFlinger执行到releaseBuffer时,并不能代表HWC 已经完全完成合成工作了,很有可能它还在读取缓冲区的内容做合成, 但不妨碍releaseBuffer的流程执行,虽然HWC还在使用缓冲区做合成,但帧缓冲区的Slot有可能被应用申请走变成DEQUEUED状态,虽然Slot是DEQUEUED状态这时GPU并不能直接存取它,它要等代表着HWC使用完毕的releaseFence的signaled信号。
应用侧申请buffer的同时会获取到一个fence对象(releaseFence):
frameworks/native/libs/gui/Surface.cpp
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();
.....
sp<Fence> fence;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
.....
}对应SurfaceFlinger侧:
frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
.......
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;//把Slot里记录的mFence对象返回出去,就是应用侧拿到的releaseFence
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;//不妨思考下这里为什么可以清成NO_FENCE?
.......
}应用侧上帧时要创建一个fence来代表GPU的功能还在进行中,提交buffer的同时把fence对象传给SurfaceFlinger:
frameworks/native/libs/gui/Surface.cpp
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
ATRACE_CALL();
......
sp<Fence> fence(fenceFd >= 0 ? new Fence(fenceFd) : Fence::NO_FENCE);//创建一个fence, 这个就是SurfaceFlinger侧的acquireFence
......
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,//将fence放入input参数
static_cast<android_dataspace>(mDataSpace), crop, mScalingMode,
mTransform ^ mStickyTransform, fence, mStickyTransform,
mEnableFrameTimestamps);
......
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);//把这个fence传给surfaceflinger
......
}对应的SurfaceFlinger侧从binder里获取到应用侧传来的fence对象(这个称为acquireFence):
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
......
sp<Fence> acquireFence;
......
input.deflate(&requestedPresentTimestamp, &isAutoTimestamp, &dataSpace,
&crop, &scalingMode, &transform, &acquireFence, &stickyTransform,
&getFrameTimestamps);
......
mSlots[slot].mFence = acquireFence;//queueBuffer完成时Slot的mFence放的是acquireFence
......
}我们来通过systrace观察一个因GPU工作时间太长,从而让DRM工作线程卡在等Fence的情况:

如上图所示,complete_commit函数(从上面4.3章我们了解过这个函数是执行SOC准备传输数据到DDIC的过程)执行时前面有一段时间是陷于等待状态了,那么它在等谁呢,从图中所示我们可以看出它在等下73026号fence的signal信号。这种情况说明drm内部的dma要去读这miHoYo.yuanshen这个应用的buffer时发现应用的GPU还没有把画面画完,它不得不等待它画完才能开始读取,但既然都已经送到crtc_commit了,至少在CPU这侧,该Slot的BufferState已经是ACQUIRED状态。
6.3 本章小结
在本章节中我们了解了不同硬件间同步工作的一种方法,了解了Fence在App画面更新过程中的使用情况。

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









