







了解算法:集合(set)算法
一、前言
这篇文章是STL学习资源的一部分,一次一点关于STL的知识。本文专注于集合(set)上的算法,这里的“集合”一词是元素集合的一般含义,而不仅仅是std::set,
前提:范围已排序。即这篇文章中提到的所有算法都要求输入范围是排序的。同样,它们的输出范围(当存在时)也是排序的。
二、取两个集合的部分数据
STL具有4种互补算法,可以取2个给定集合的不同部分。它们有一种常见的原型形式,输入两个范围,输出一个范围:
template<typename InputIterator1, typename InputIterator2, typename OutputIterator>
OutputIterator algo(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
因此,对于两个排序集合A和B,可以这样调用:
algo(A.begin(), A.end(), B.begin(), B.end(), result);
result 可以是vector上的 std::back_inserter ,也可以是任何其他输出迭代器。
假设有两个集合A和B。
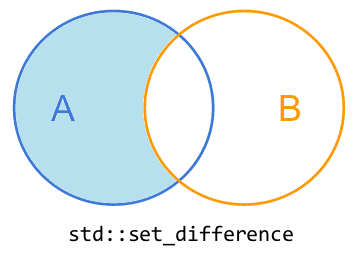
2.1、std::set_difference
std::set_difference将在A中而不是B中的所有元素复制到result中。也可以称为取非(即NOT)。
示例:
#include <algorithm>
#include <iterator>
#include <set>
#include <vector>
std::vector<int> A = {...} // sorted vector
std::set<int> B = {...} // std::set is always sorted
std::vector<int> results;
std::set_difference(A.begin(), A.end(),
B.begin(), B.end(),
std::back_inserter(results));
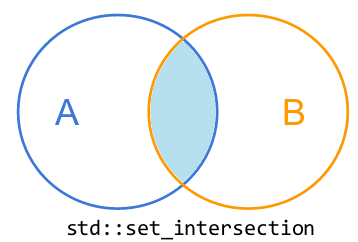
2.2、std::set_intersection
std::set_intersection将既在A中也在B中的所有元素复制到result中。即交集。
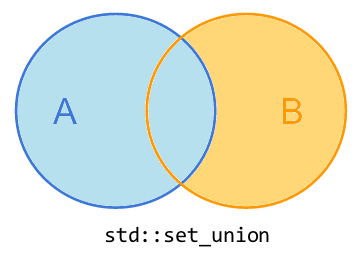
2.3、std::set_union
std::set_union将A、B或两者中的所有元素复制到result中。对于同时存在于两者中的元素,将取A的版本(除非在B中出现的公共元素比在A中出现的多,在这种情况下,也取其在B中的附加版本)。
2.4、std::set_symmetric_difference
std::set_symmetric_difference 只是简单地将在 A 中却不在 B 中的元素以及在 B 中却不在 A 中的元素复制到 result 中。
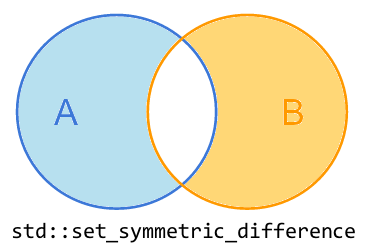
std::set_symmetric_difference 是一个特别好的算法示例,虽然听起来很复杂,但它实际上非常容易理解,并且在日常编码中非常有用。这种情况在STL算法中经常发生。
三、比较两个集合
比较两个集合的算法不得不提到std::includes,因为它操作的是集合(即前面解释过的按顺序排列的元素集合)。
给定两个排序集合A和B,std::include检查B的所有元素是否也在A中。
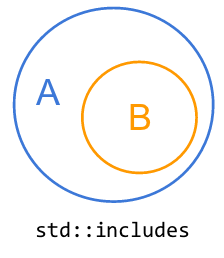
函数原型:
template<typename InputIterator1, typename InputIterator2>
bool std::includes(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2 );
使用方式:
bool AincludesB = std::includes(A.begin(), A.end(), B.begin(), B.end());
四、合并两个集合
4.1、std::merge
std::merge用于将两个排序集合 合并为一个排序集合。函数原型:
template<typename InputIterator1, typename InputIterator2, typename OutputIterator>
OutputIterator merge(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
给定两个排序集合A和B,将A和B合并到从result开始的排序范围中。
使用方式:
std::merge(A.begin(), A.end(), B.begin(), B.end(), result);
4.2、std::inplace_merge
虽然这篇文章中的所有算法在代码中经常有用,但std::inplace_merge很少使用。由于STL学习的目标之一是涵盖所有算法,所以在这里描述它一下,如果对这个算法不感兴趣,而只是对代码的实际结果感兴趣,那么可以直接跳到下一节。
std::inplace_merge算法接受一个集合,并直接在其中进行合并。而std::merge接受两个集合,并在第三个集合中输出其结果。std::inplace_merge将其操作的集合视为两个连续的部分,并将第一部分与第二部分合并。
函数原型:
template<typename BidirectionalIterator>
void inplace_merge(BidirectionalIterator first, BidirectionalIterator middle, BidirectionalIterator last );
其中:
first是集合的开始,也是第一部分的开始;middle是集合第二部分的开始;last是全集的结束,也是第二部分的结束。
std::inplace_merge和std::sort有什么不同?
答案是前置条件的不同:
- 在
std::inplace_merge中,第一部分和第二部分本身已经排序,因为std::inplace_merge是一个集合算法。 - 还有一个相当大的技术差异,即
std::sort需要随机访问迭代器,而std::inplace_merge只需要双向迭代器。
std::inplace_merge在什么地方有用?当然是在合并排序算法的实现中啦。
五、为什么排序?
在这篇文章中看到的所有算法都要求它们的输入和输出范围排序。原因是:
- 如果将未排序的输入范围传递给这些算法中的任何一个,结果将是错误的。因为这些算法基于输入范围已排序这一事实做出假设。如果这不是真的,那么这些假设就是假的。
- 这些假设让算法更快地执行它们的工作。通常以
O(n)的复杂度,而不是O(n * logN)的复杂度。
六、结论
我们看到了STL提供的所有操作集合的算法,集合是一般意义上排序元素的集合。这些算法是如何比较它们所操作的元素,以检查如何处理它们的呢?在使用这些算法时,理解这一点至关重要,这将在后面的一篇专门文章进行介绍。
















 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











