






1.seatunnel依赖地址
2.seatunnel官网的source/sink模板
3.seatunnel的GitHub地址
一、在官网下载安装包,千万别下载apache-seatunnel-incubating-2.1.0-bin.tar.gz版本,什么依赖和功能都没有。要使用apache-seatunnel-2.3.3-bin.tar.gz,但还需要配置环境和jar包,jar包需要联网
从2.2.0-beta开始,二进制包默认不提供connectors的依赖,因此在第一次使用它时,需要执行以下命令来安装连接器。当然,您也可以从Apache Maven Repository[https://repo.maven.apache.org/maven2/org/apache/seatunnel/]手动下载连接器,然后手动移动到connectors/seatunnel目录)
sh bin/install-plugin.sh如果需要指定connector的版本,以2.3.3版本为例,需要执行
sh bin/install-plugin.sh 2.3.3也可以手动导入依赖
1.这个目录下放连接器
apache-seatunnel-2.3.3/connectors/seatunnel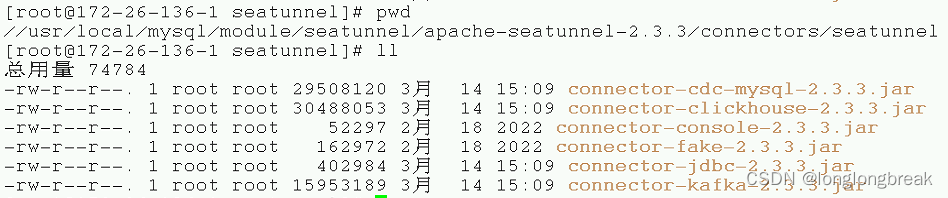
2.这个目录下放MySQL和clickhouse连接驱动和seatunnel的source包

/usr/local/mysql/module/seatunnel/apache-seatunnel-2.3.3/lib3.这个目录下放配置文件
/usr/local/mysql/module/seatunnel/apache-seatunnel-2.3.3/config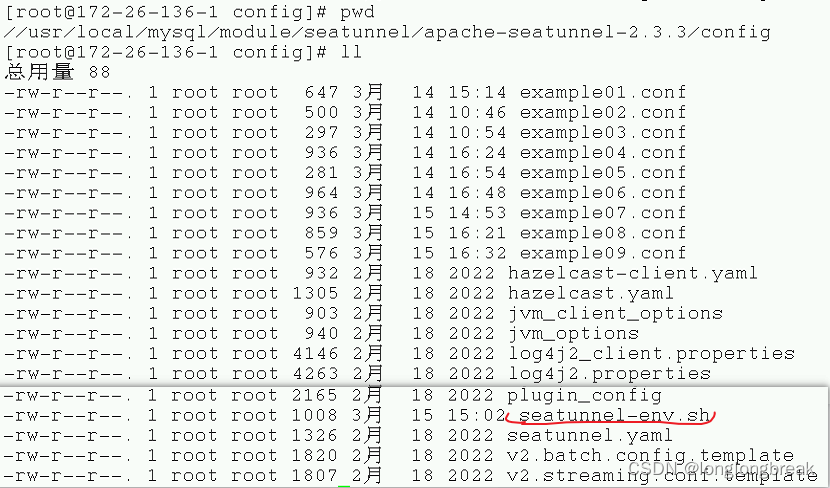
注意这里有一个
seatunnel-env.sh文件,是配置flink或者spark环境变量的文件需要配置
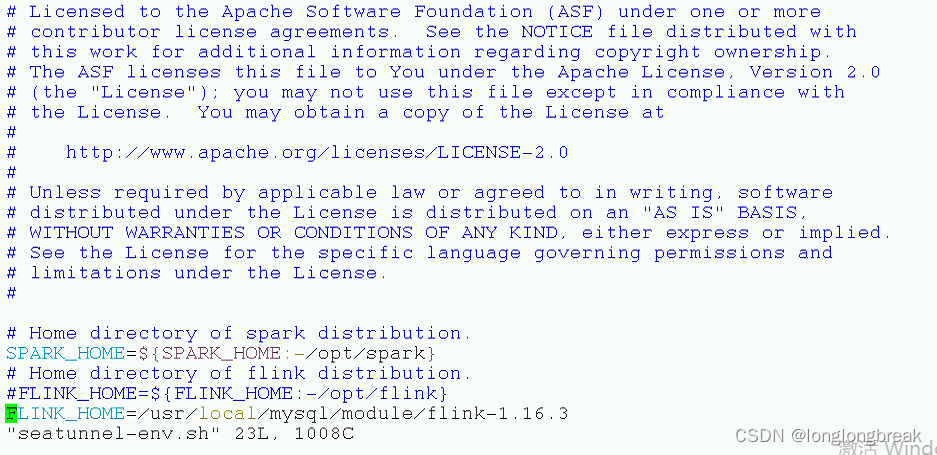
执行命令

注意这里bin目录下的启动脚本选择,启动先最好先看一下flink -v、环境变量文件seatunnel-env.sh的配置、脚本选择(flink版本不同,启动脚本不同),确保flink的jobmannean和taskman都启动,然后再执行任务

example08.conf配置文件中
env {
execution.parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
这里使用flink一定要是STREAMING,不能是BATCH具体配置格式参考上面的第2点——2.seatunnel官网的source/sink模板
最后注意执行任务可能需要几十分钟,但数据一定要等任务运行完毕后才能过去

#附件是seatunnel2.3.3版本的完整目录,包含MySQL、clickhouse的连接驱动和配置文件,包括seatunnel-env.sh环境变量文件,根据数据同步链路和服务器参数改动
#附件2是配置文件。从MySQL到clickhouse,从MySQL到Kafka,从Kafka到clickhouse
执行一次命令同步一次。在数据同步过程中,确保目标表和源表都存在,并且源表内有数据是非常重要的,这样才能够在执行同步命令后在目标表中看到同步效果
[root@172-xx-xxx-x bin]# ./start-seatunnel-flink-15-connector-v2.sh --config ../config/example07.conf
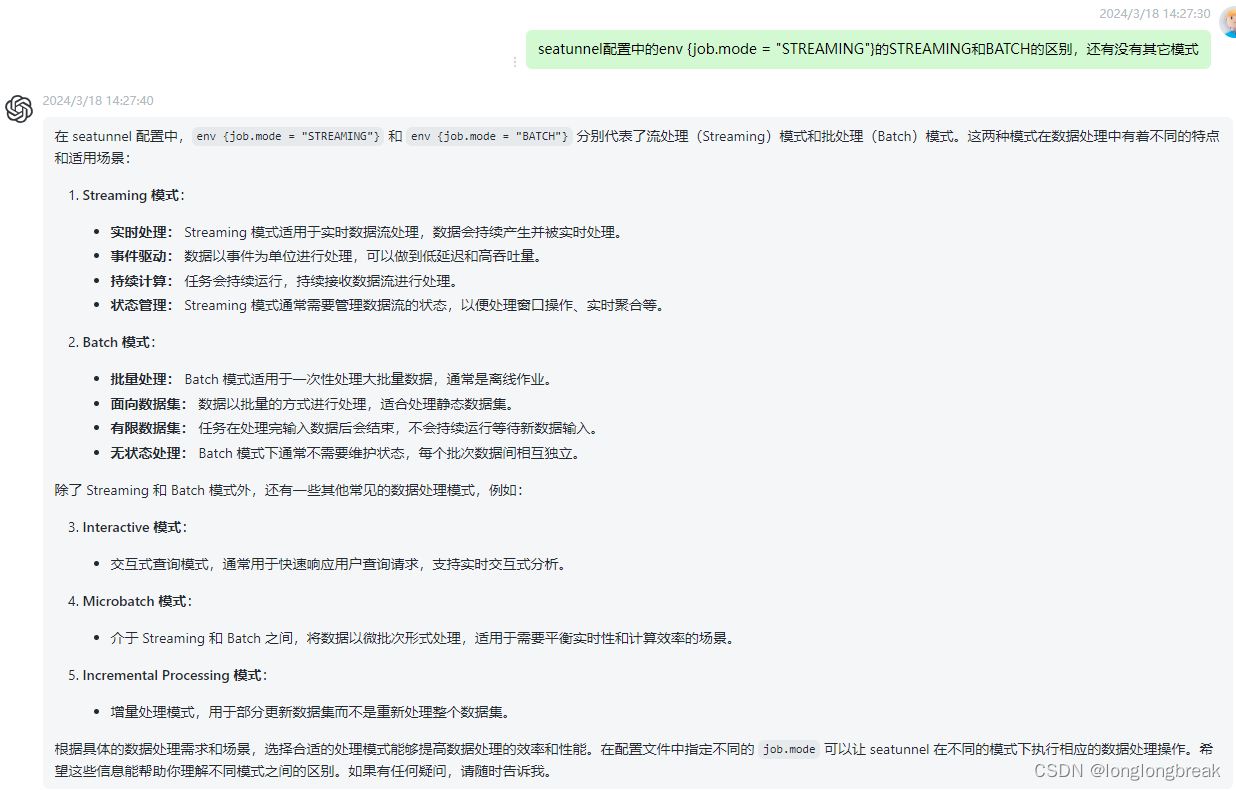
seatunnel配置中的env {job.mode = "STREAMING"}的STREAMING和BATCH的区别















 2217
2217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









