







一、登录OpenBayes进行注册登录
通过以下链接,新用户注册登录 OpenBayes , 即可获得 四个小时 RTX 4090免费使用时长 !!
注册链接:https://openbayes.com/console/signup?r=zzl99_WBHM
二、创建容器
模型训练=》创建容器=》填写容器名称=》下一步
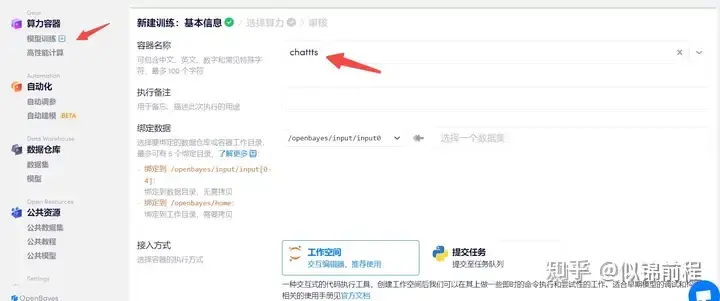
选择一台4090,2.1-gpu,python-3.10,cudu-12.1,然后执行
三、配置环境
首先需要下载llama-factory源码,执行如下命令
#下载
!git clone https://github.com/hiyouga/LLaMA-Factory.git
安装所需的模块,可以按需下载
cd LLaMA-Factory
#可选的额外依赖项:metrics、deepspeed、bitsandbytes、vllm、galore、badam、gptq、awq、aqlm、qwen、modelscope、quality
pip install -e .[torch,metrics]注意:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









