






一、基础模型下载
- 本文的背景是微调一个基于Llama3的中文版模型
Llama3-8B-Chinese-Chat,用于中文指定领域的问答下游任务
1、HuggingFace官网直接下载
-
官网地址:
https://huggingface.co/models -
镜像网址:
https://hf-mirror.com/ -
按照如下图所示搜索需要的基础模型
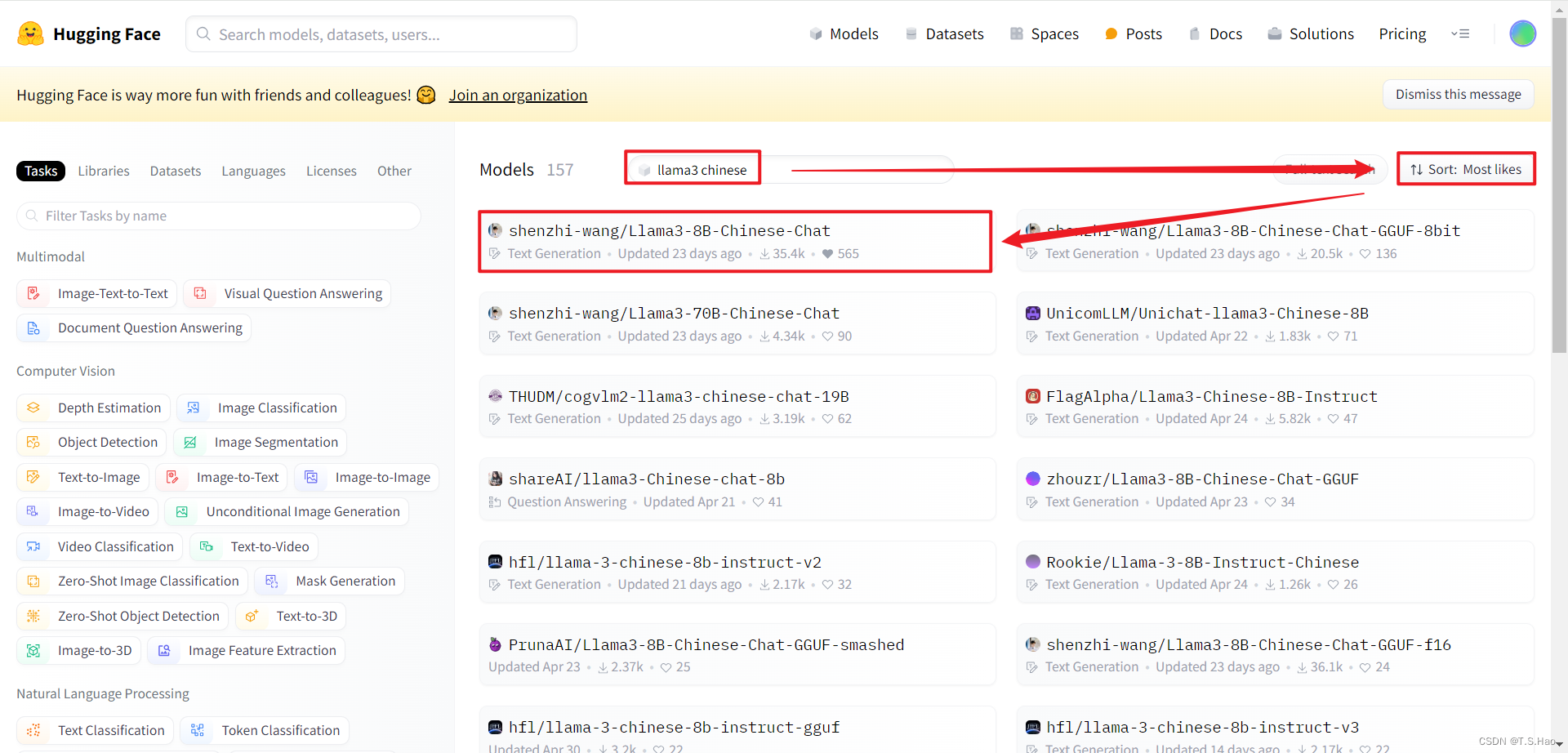
-
点击
Files and versions
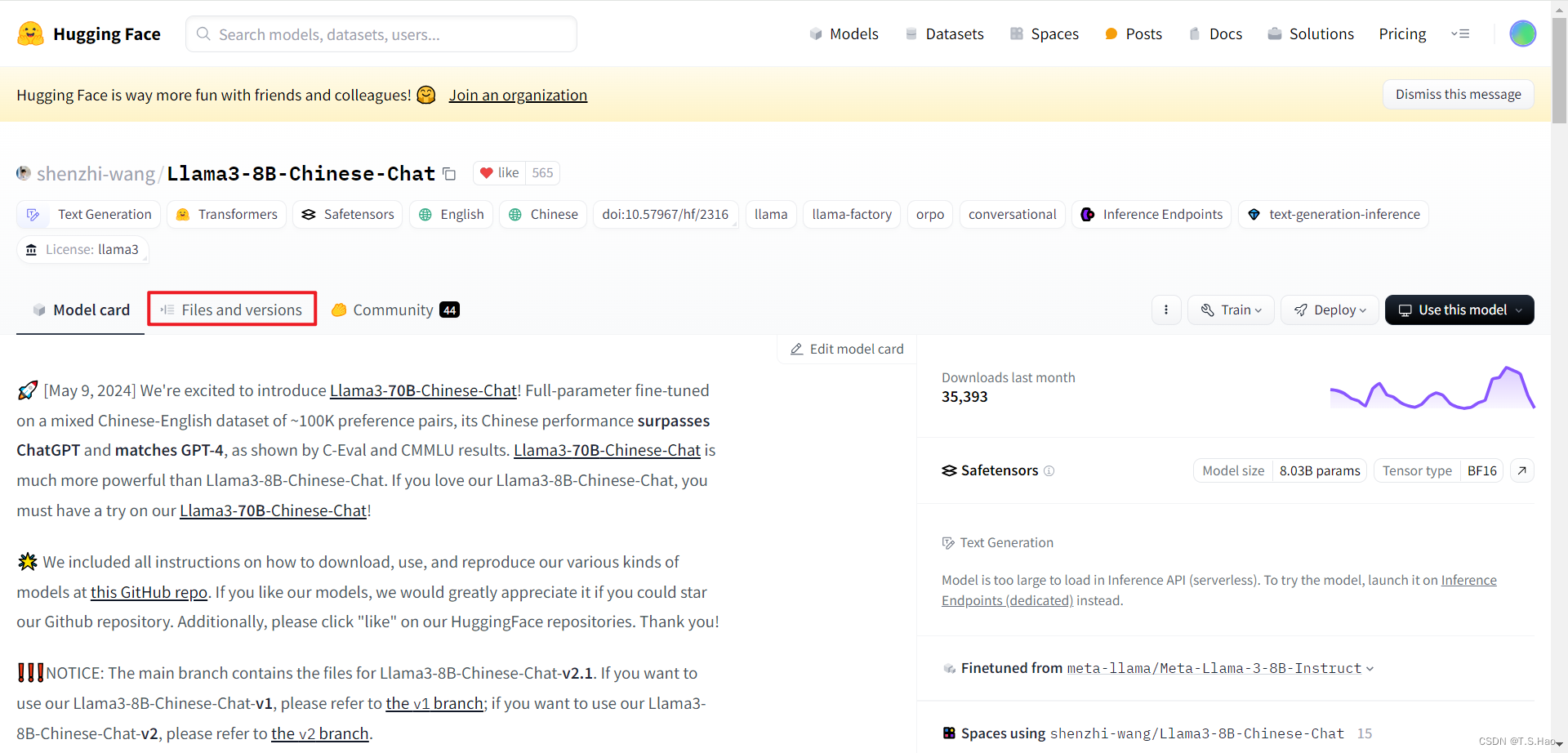
-
依次点击下载,将模型文件下载至指定的文件夹内
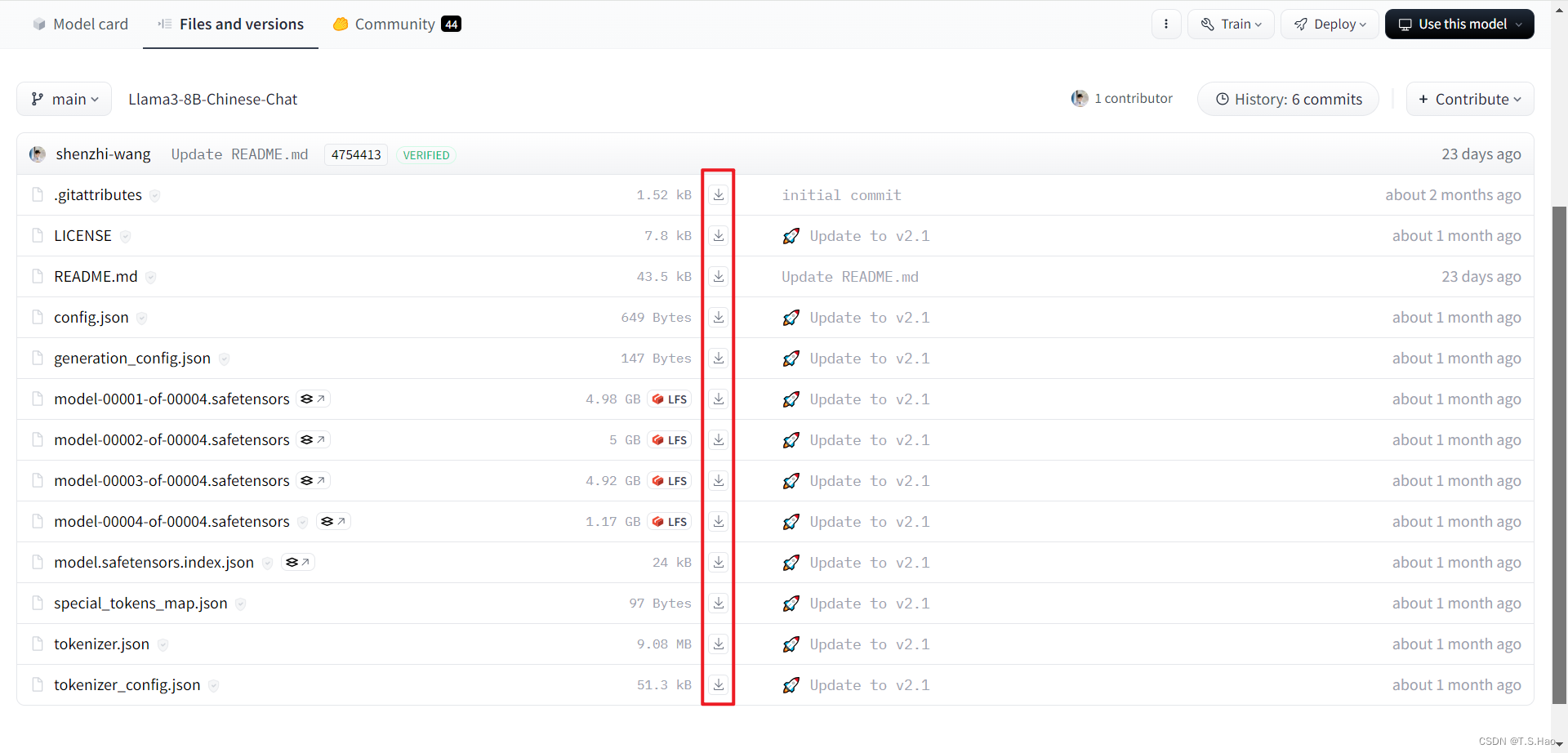
-
此方法官方网站下载速度可能很慢,建议时间紧的同学采用镜像网站下载
2、使用HuggingFace的transformers库下载
- 安装transformers工具库
pip install transformers
- 创建环境变量
HF_HOME,配置模型下载地址
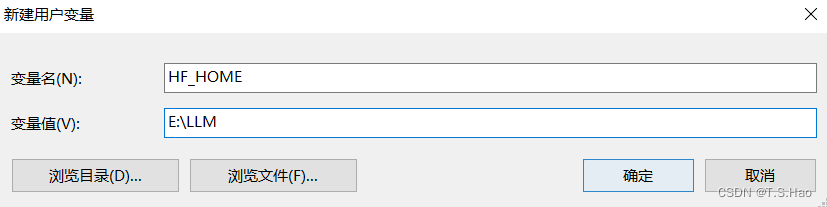
- 验证配置是否生效
huggingface-cli scan-cache

- 执行如下代码
from transformers import AutoModel
model_name = "shenzhi-wang/Llama3-8B-Chinese-Chat"
model = AutoModel.from_pretrained(model_name)
- 或者直接使用命令
transformers-cli download Qwen/Qwen2.5-14B --cache-dir ./
3、HuggingFace国内镜像下载(旧版现已经弃用)
# 下载所需的工具包
pip install -U huggingface_hub
pip install huggingface-cli
# 指定国内镜像源
# Linux
export HF_ENDPOINT=https://hf-mirror.com
# Windows
set HUGGINGFACE_HUB_ENDPOINT=https://hf-mirror.com
# 执行下载命令
# --resume-download 是下载中断恢复下载后继续从上次下载中断点继续下载
# shenzhi-wang/Llama3-8B-Chinese-Chat 是要下载模型的名称
# E:\LLM 是下载到本地的路径
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --local-dir E:\LLM
4、下载成功后最好校验一下下载的模型是否有问题
二、微调工具LLaMA-Factory 框架
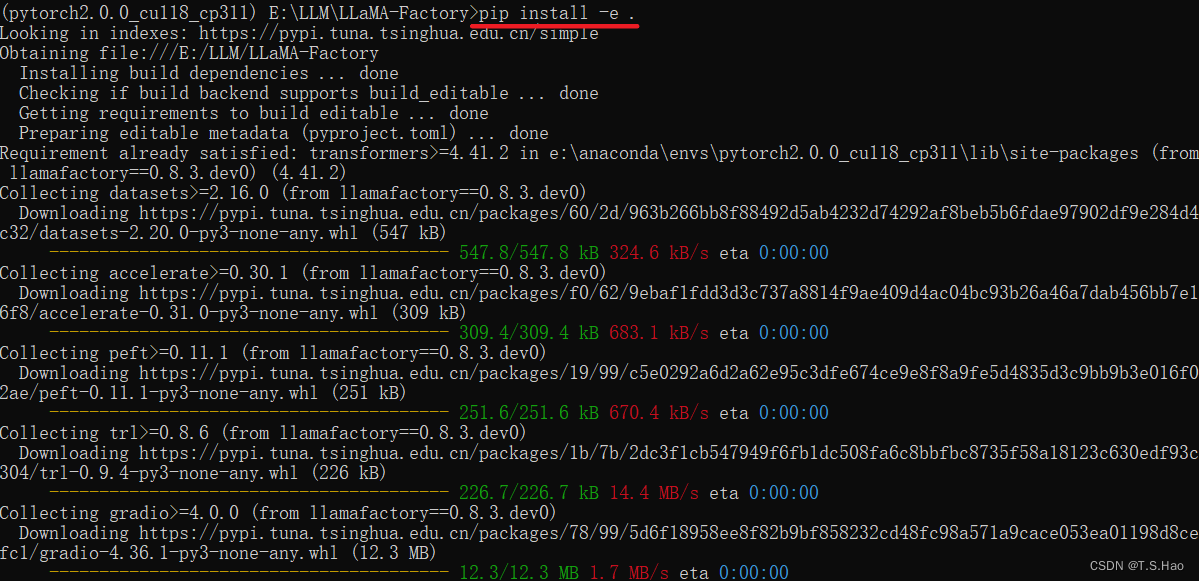
1、LLaMA-Factory安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# "[torch,metrics]"可以删除直接执行pip install -e .
pip install -e ".[torch,metrics]"
- 下载成功后,入下图所示
- LLaMA-Factory详细介绍可移步GitHub:
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
三、构建微调数据
1、打开LLaMA-Factory项目
- 目录结构如下图所示
2、构建微调json数据
- 在
data目录下新建fine_tuning_data文件夹,用来存放微调所需的数据
- 由于业务数据公司要求保密,这里就随便构造一些数据用于实验,大家可以根据自己的业务需求进行预训练数据的构造

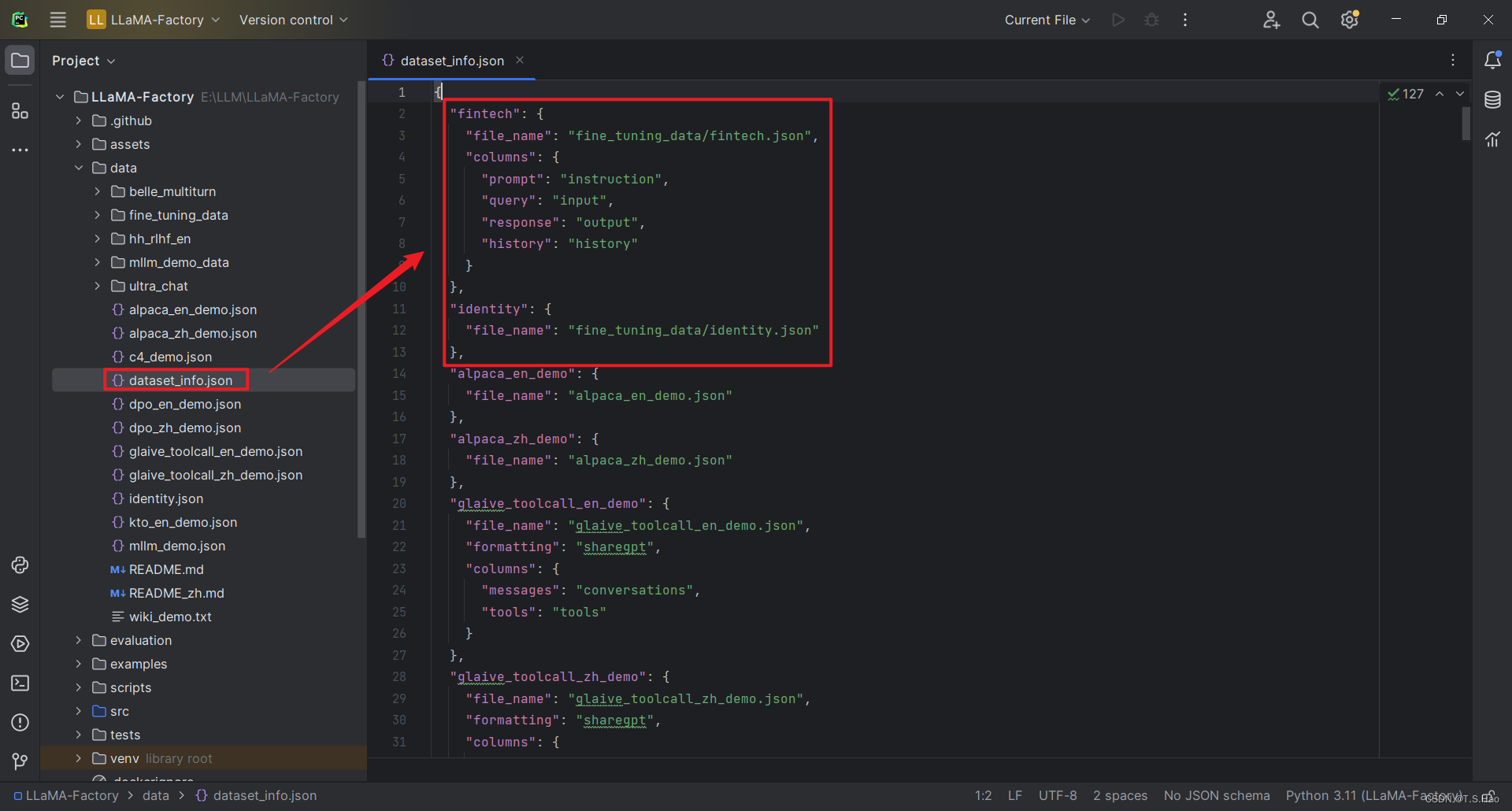
- 在
dataset_info.json文件中将刚刚构建的微调数据进行路径配置,注意配置格式要与构建的数据格式一一对应
# 新构建的节点
"fintech": {
"file_name": "fine_tuning_data/fintech.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
},
# 默认自带的节点,注意修改路径
"identity": {
"file_name": "fine_tuning_data/identity.json"
},
四、启动LLaMA-Factory Web UI进行模型微调
1、启动LLaMA-Factory并设置微调参数
- 在LLaMA-Factory项目的根目录下输入已下指令启动LLaMa-Factory Web UI
llamafactory-cli webui
- 启动成功后命令框显示如下

- Web UI界面显示如下
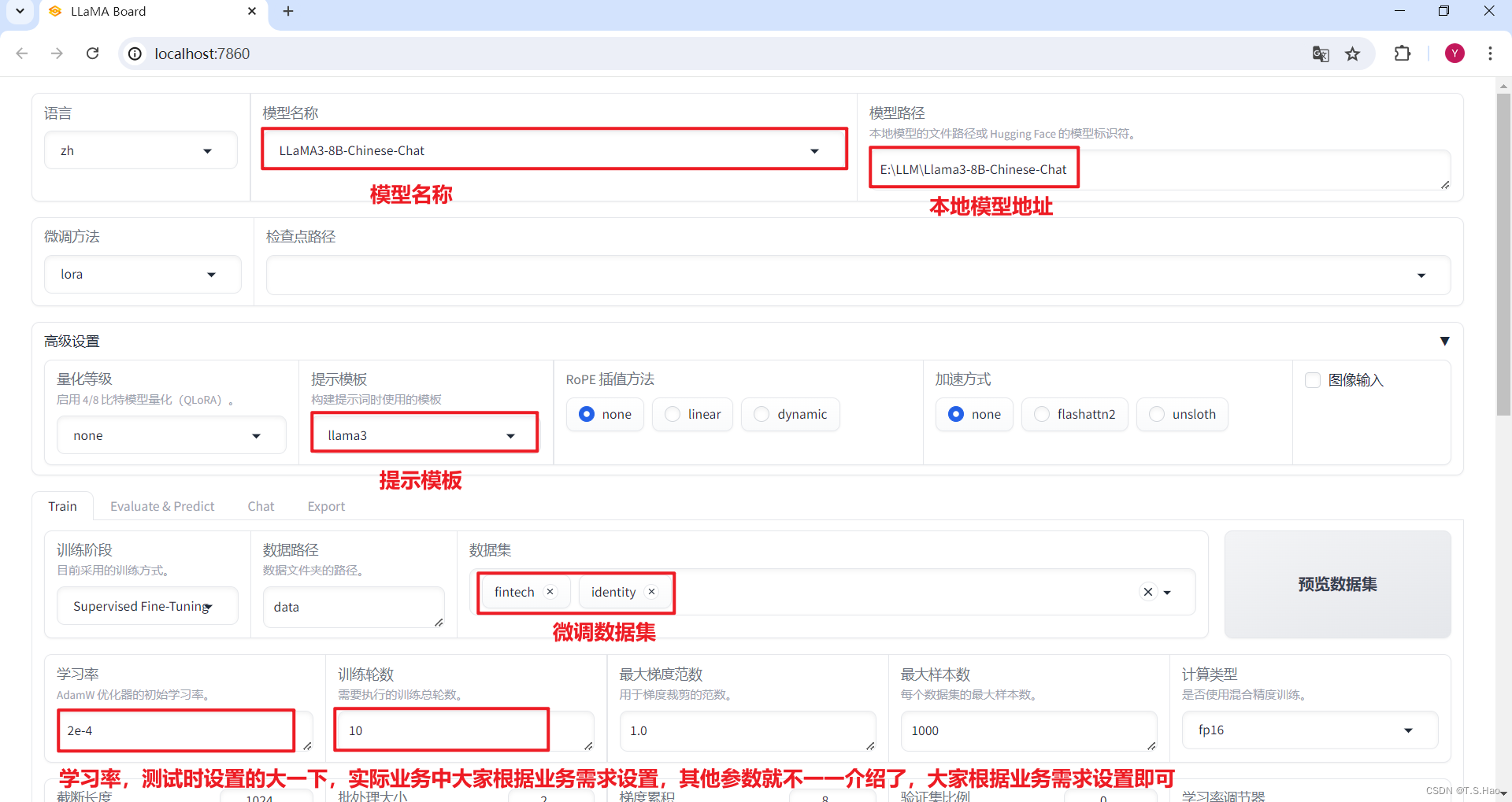
- 设置微调参数
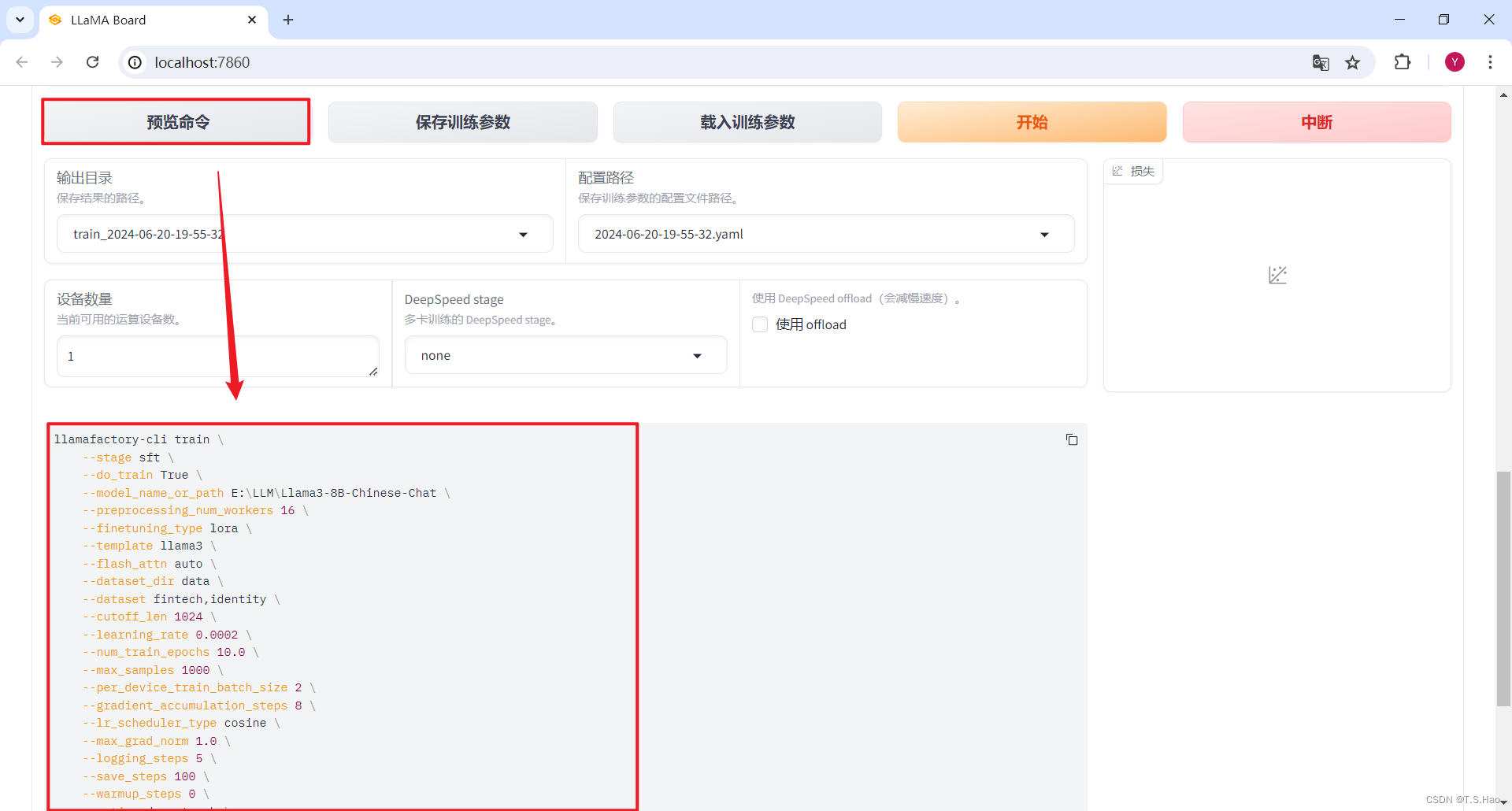
- 点击预览命令,生产微调指令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path E:\LLM\Llama3-8B-Chinese-Chat \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset fintech,identity \
--cutoff_len 1024 \
--learning_rate 0.0002 \
--num_train_epochs 10.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves\LLaMA3-8B-Chinese-Chat\lora\train_2024-06-20-19-55-32 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
2、开始微调
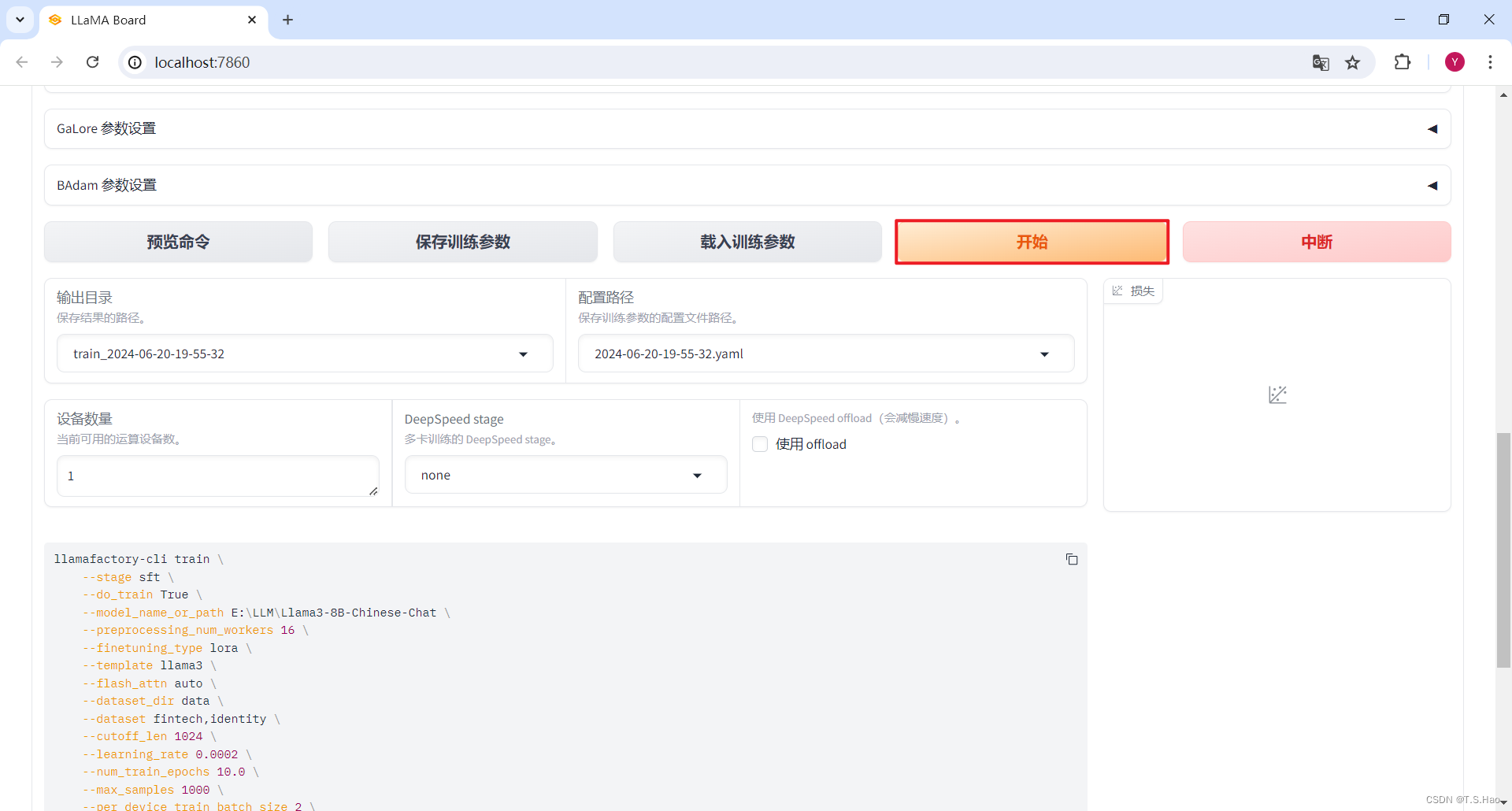
- 第一种方法启动微调
- 在Web UI中点击
开始
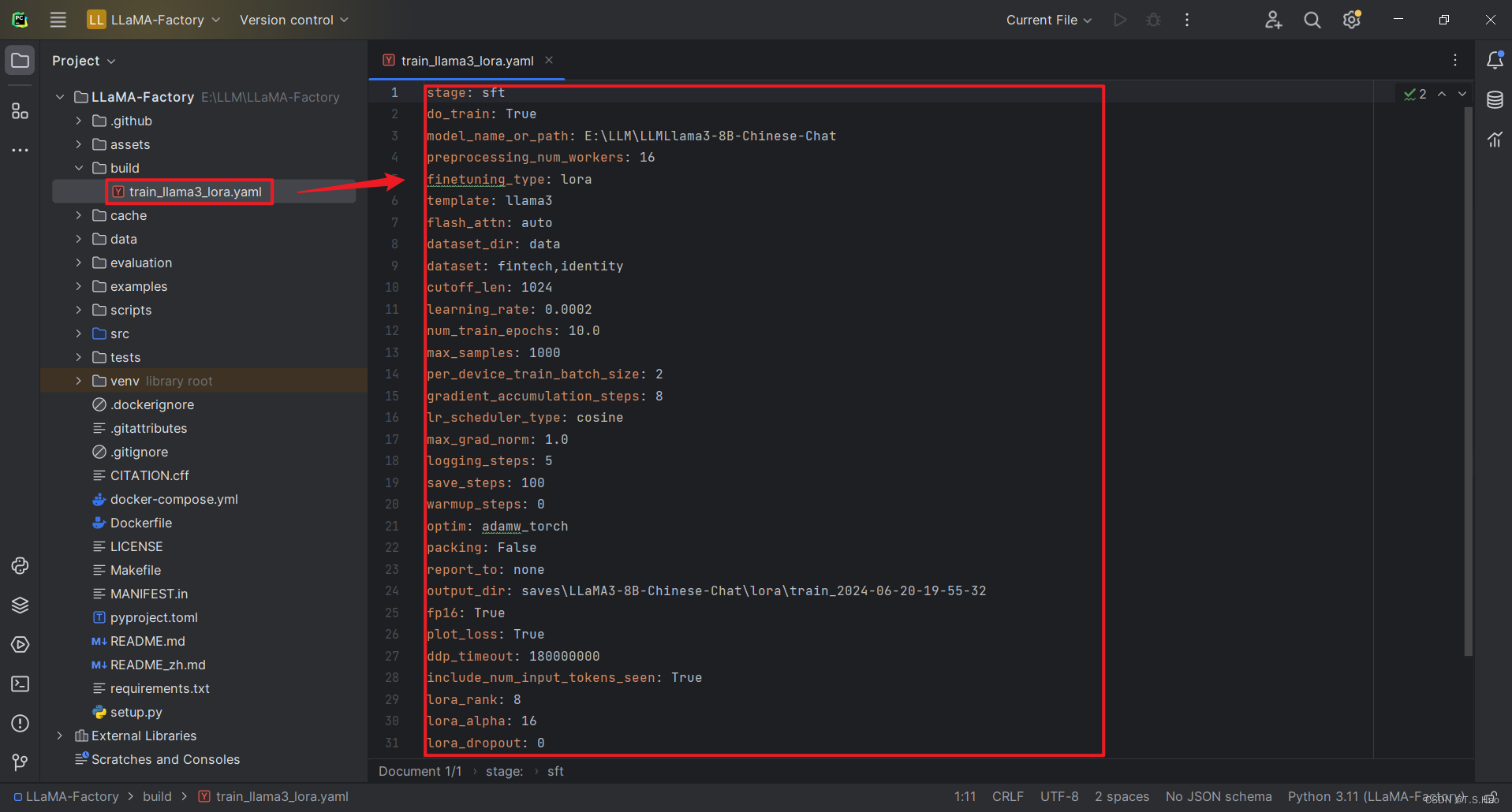
- 第二种方法启动微调
- 将微调指令构建成
build/train_llama3_lora.yaml配置文件,内容如下
stage: sft
do_train: True
model_name_or_path: E:\LLM\LLMLlama3-8B-Chinese-Chat
preprocessing_num_workers: 16
finetuning_type: lora
template: llama3
flash_attn: auto
dataset_dir: data
dataset: fintech,identity
cutoff_len: 1024
learning_rate: 0.0002
num_train_epochs: 10.0
max_samples: 1000
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
lr_scheduler_type: cosine
max_grad_norm: 1.0
logging_steps: 5
save_steps: 100
warmup_steps: 0
optim: adamw_torch
packing: False
report_to: none
output_dir: saves\LLaMA3-8B-Chinese-Chat\lora\train_2024-06-20-19-55-32
fp16: True
plot_loss: True
ddp_timeout: 180000000
include_num_input_tokens_seen: True
lora_rank: 8
lora_alpha: 16
lora_dropout: 0
lora_target: all
- 在LLaMA-Factory项目的根目录执行以下命令开始微调
llamafactory-cli train build/train_llama3_lora.yaml
- 开始微调,需要耐心等待
- 微调过程中要经常检测一下显卡的运行情况,防止“爆显存”导致微调任务终止
# Linux
watch -n 1 nvidia-smi
# windows
nvidia-smi.exe -l
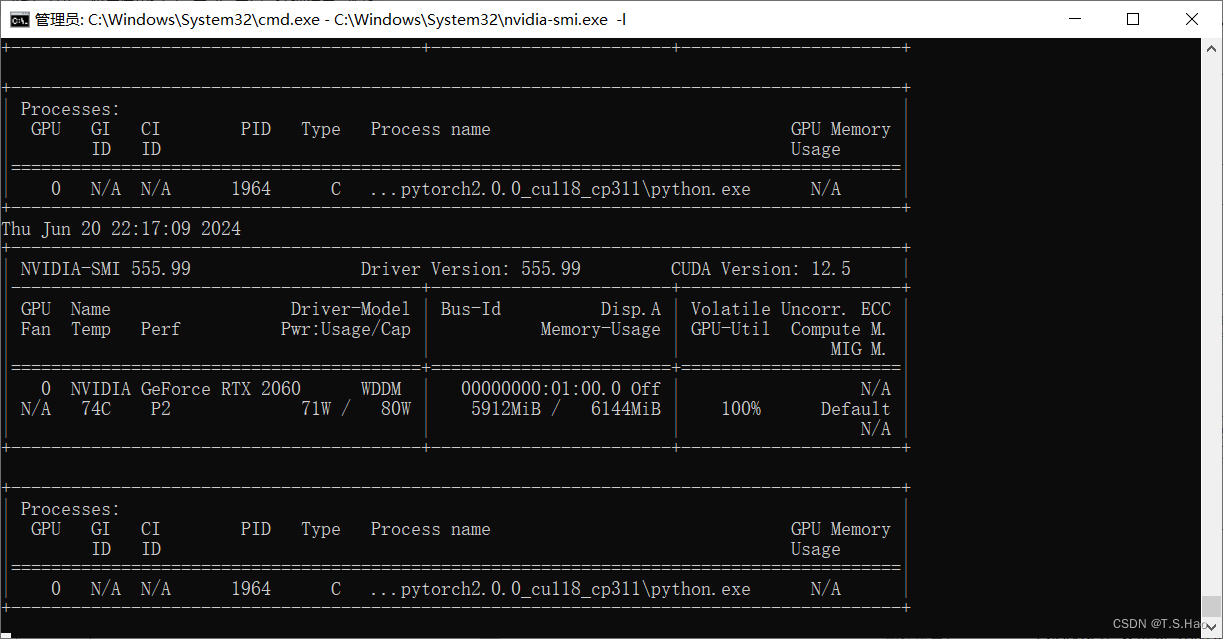
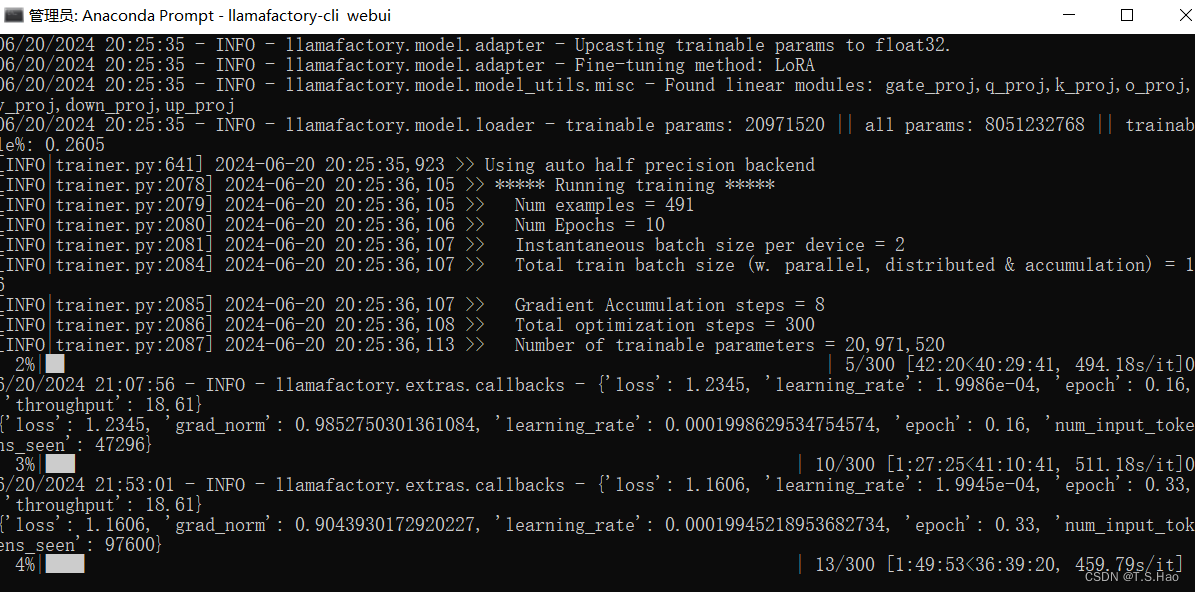
- 开始微调后,可以观看终端进度条检测微调任务进程
- 还可以在Web UI中观看微调过程中的loss下降图
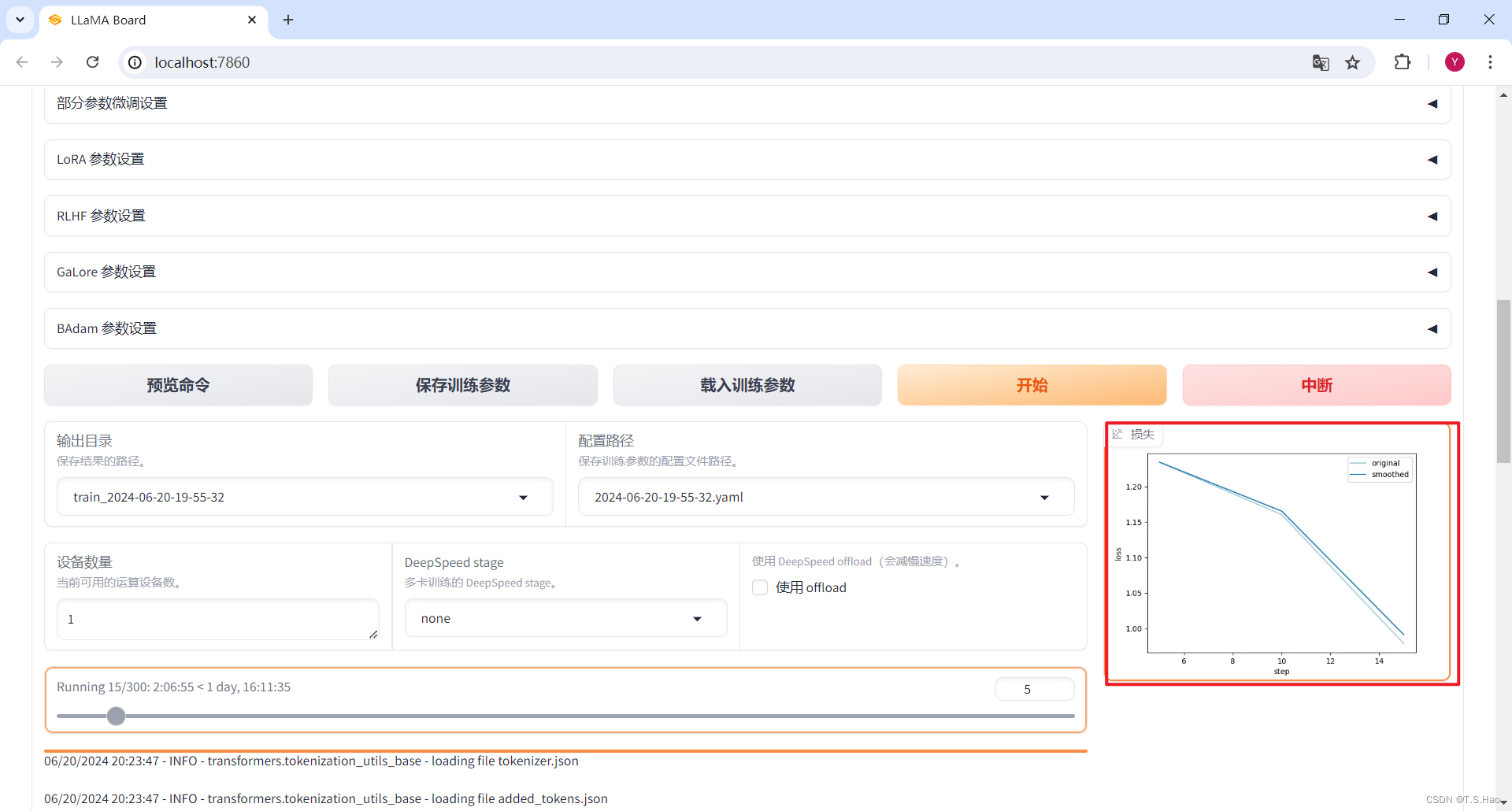
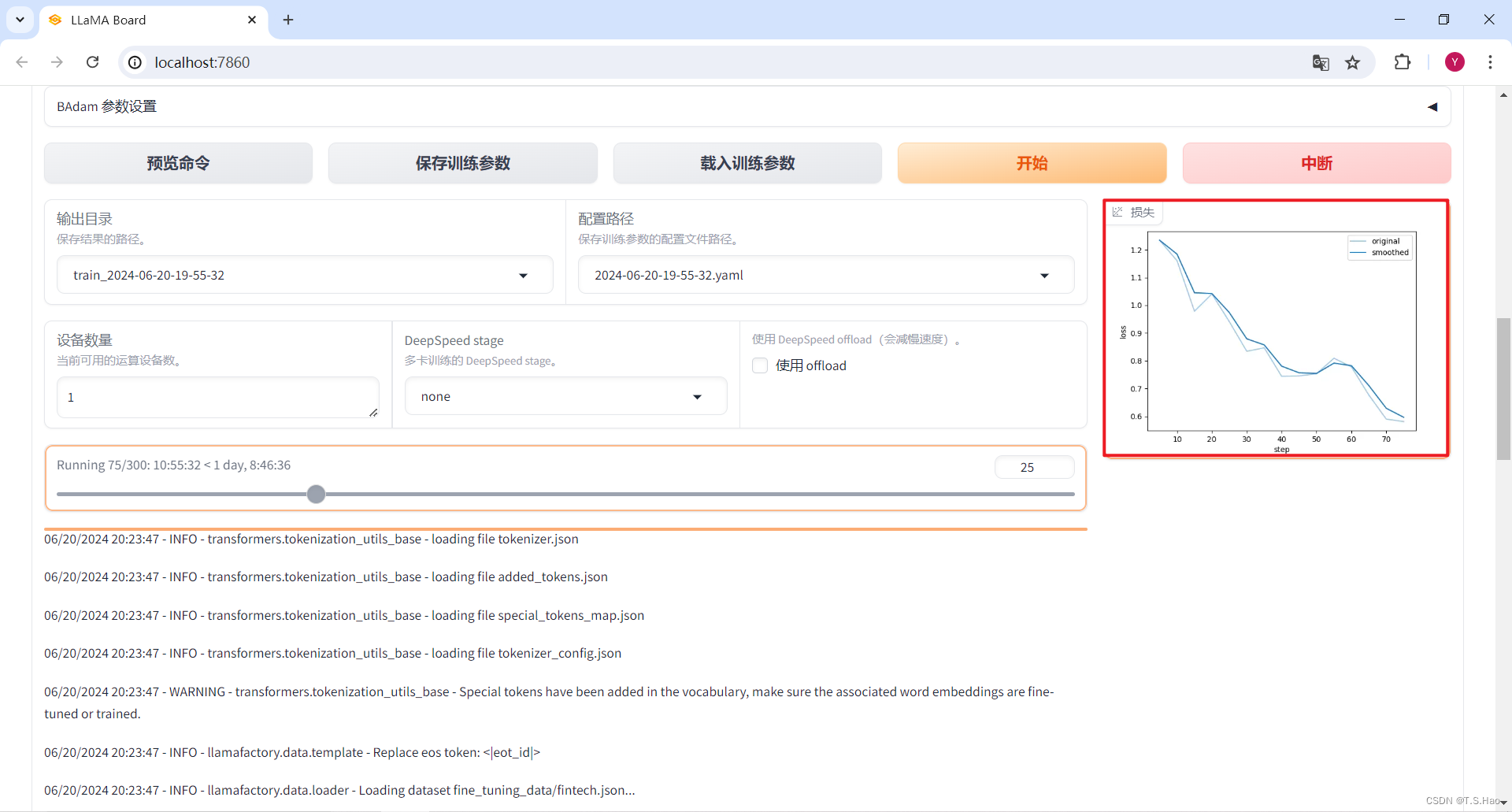
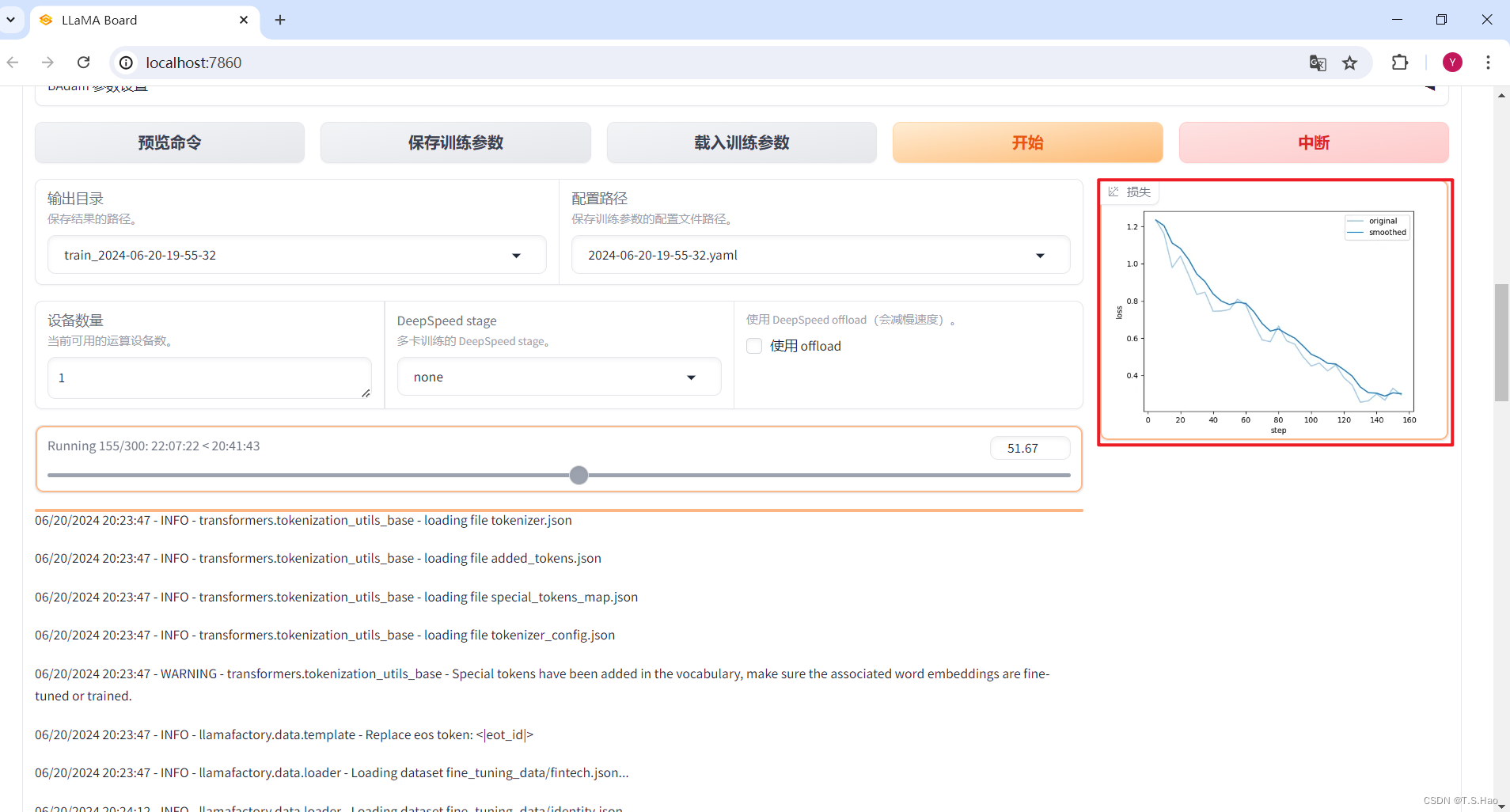
3、查看微调结果
- 微调完成后,终端和Web UI会有相应的提示
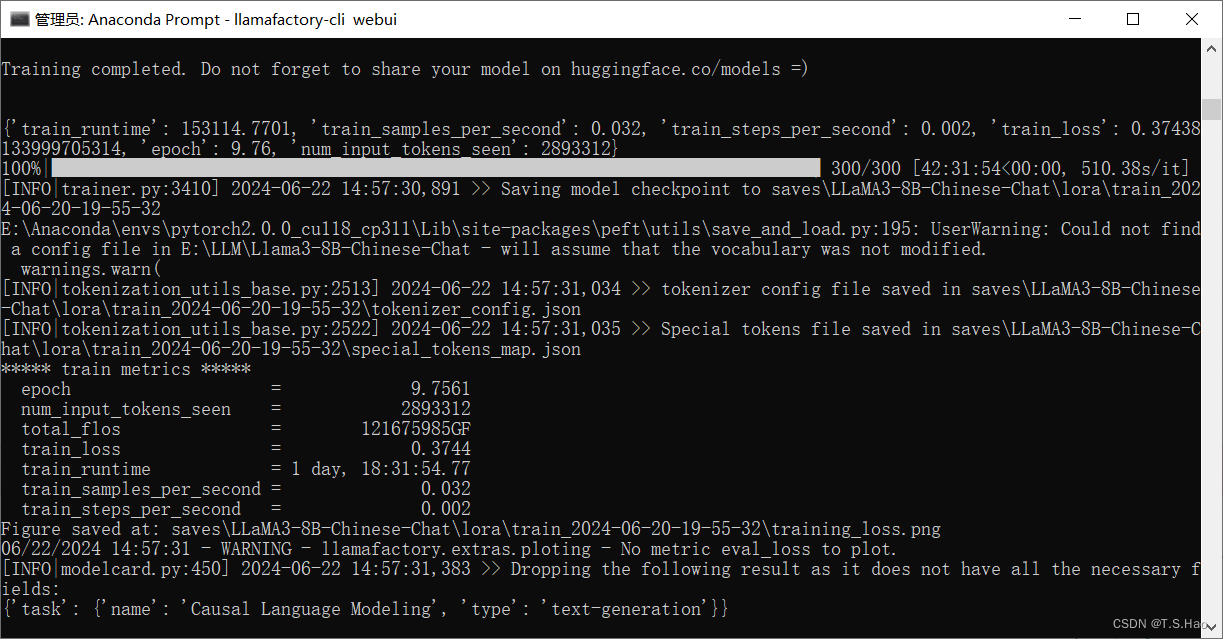
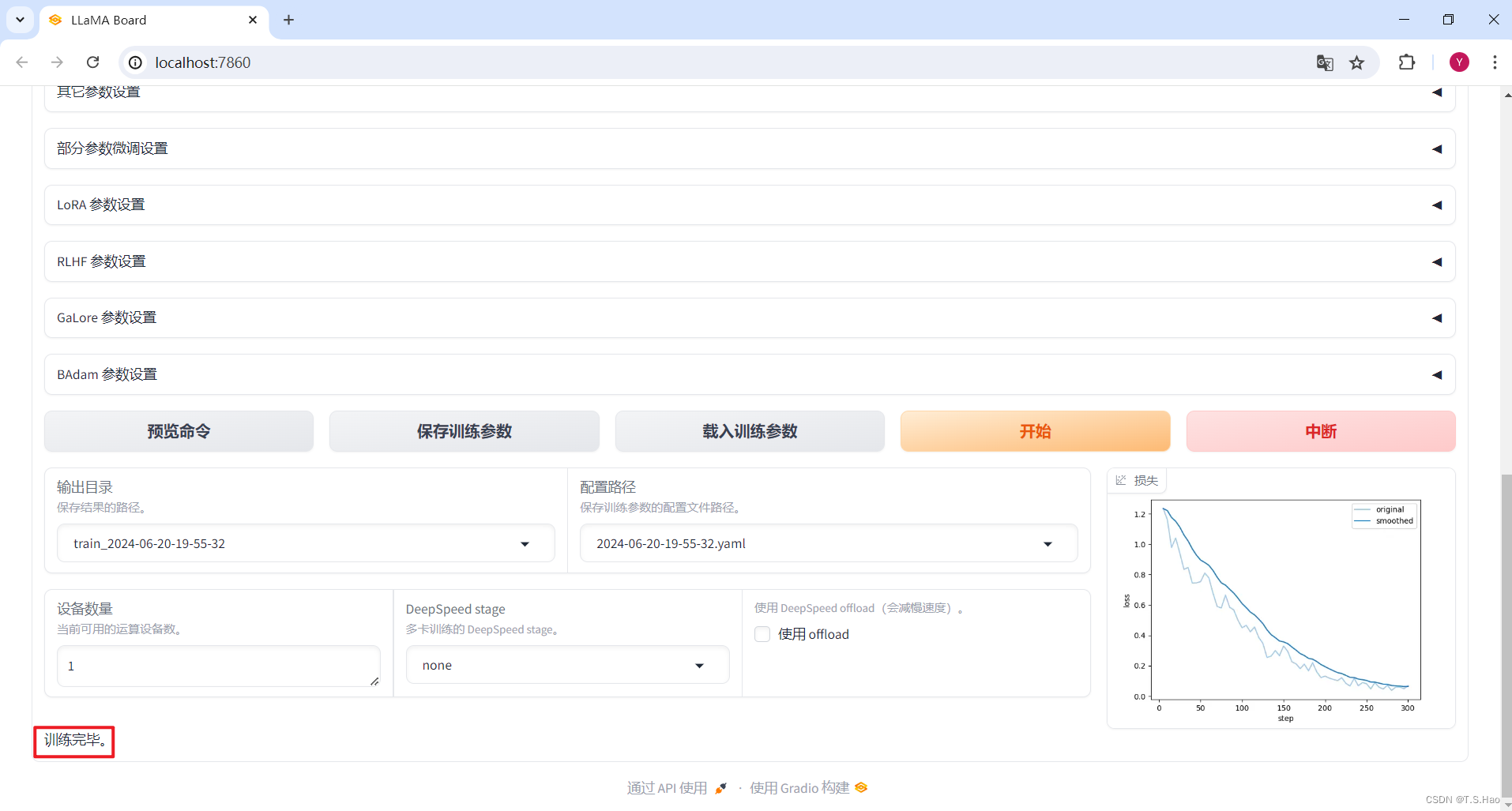
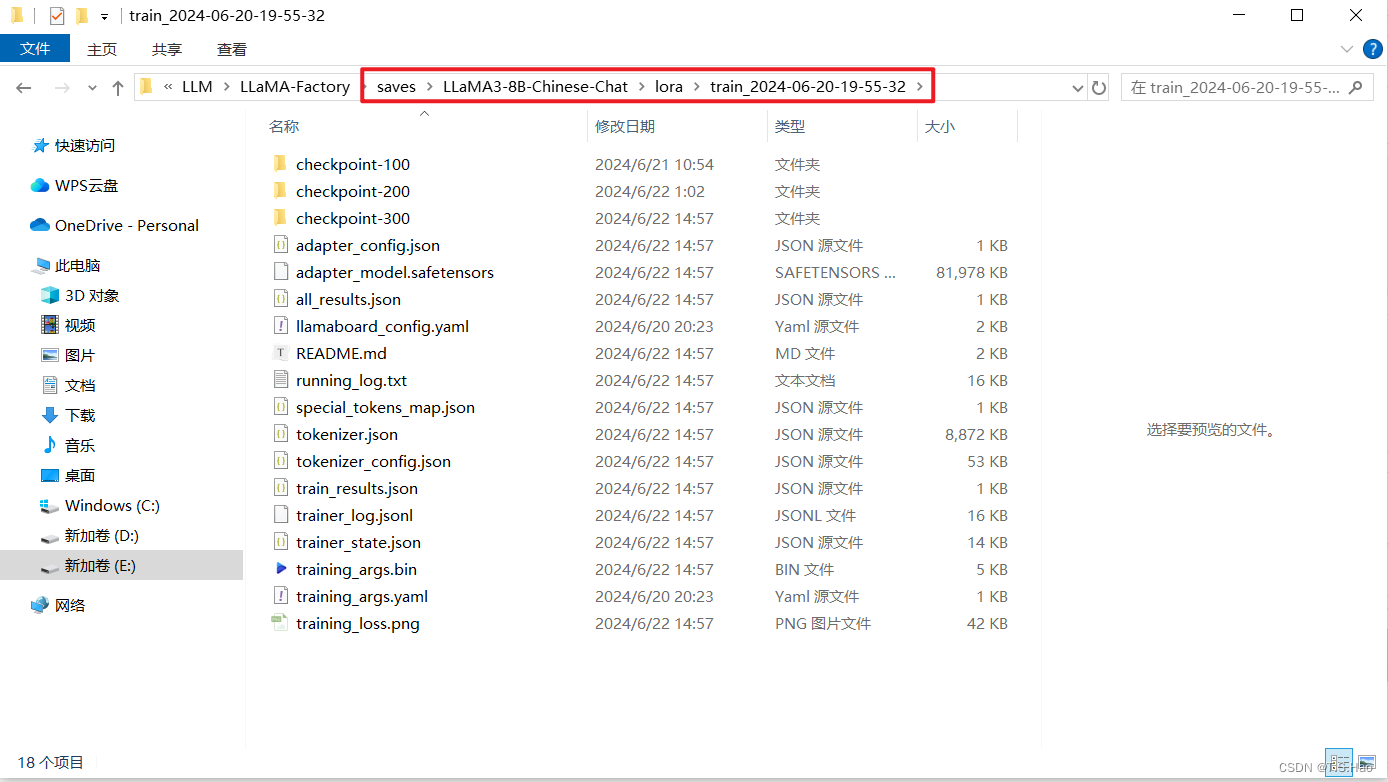
- 微调完成后,在指定的文件夹下可以查看微调对应的模型参数
五、检验微调结果
1、加载验证集进行模型验证
- 在微调成功后,大家需要根据具体业务情况,将准备好的验证数据集加载进来,用于验证模型的微调情况

- 这里在进行验证的过程中,需要用到
jieba、nltk、rouge-chinese这三个NLP常用的工具包,大家如果没有安装,可以在执行验证前进行安装
pip install jieba nltk rouge-chinese
2、加载微调前后的模型进行推理,对比结果
- 这里用到了vllm推理框架,没有安装的同学也需要安装一下
# Linux
pip install vllm
- 加载预训练模型
Llama3-8B-Chinese-Chat
- 加载成功后,就可以进行对话了
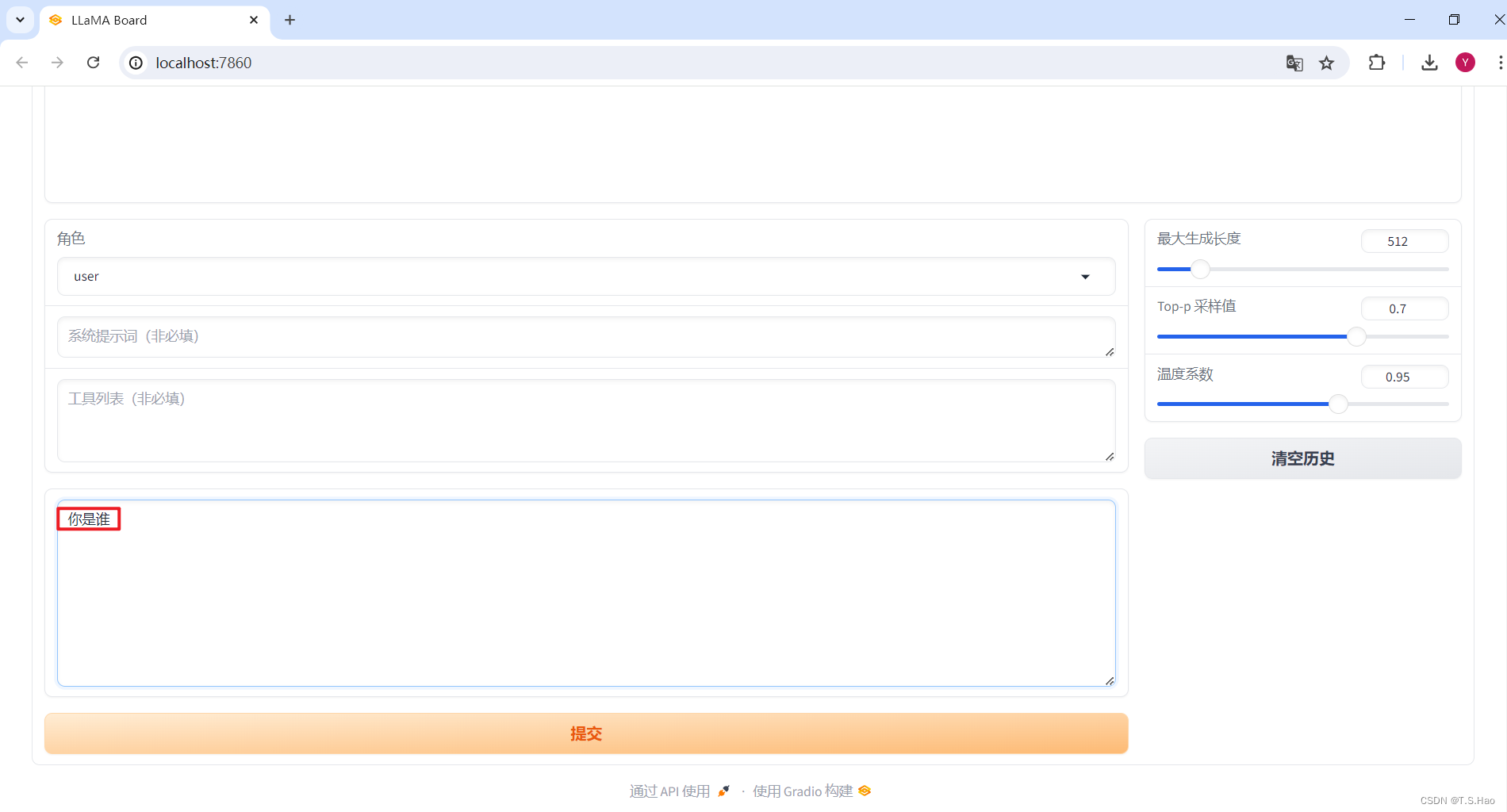
- 这是微调前的模型回答
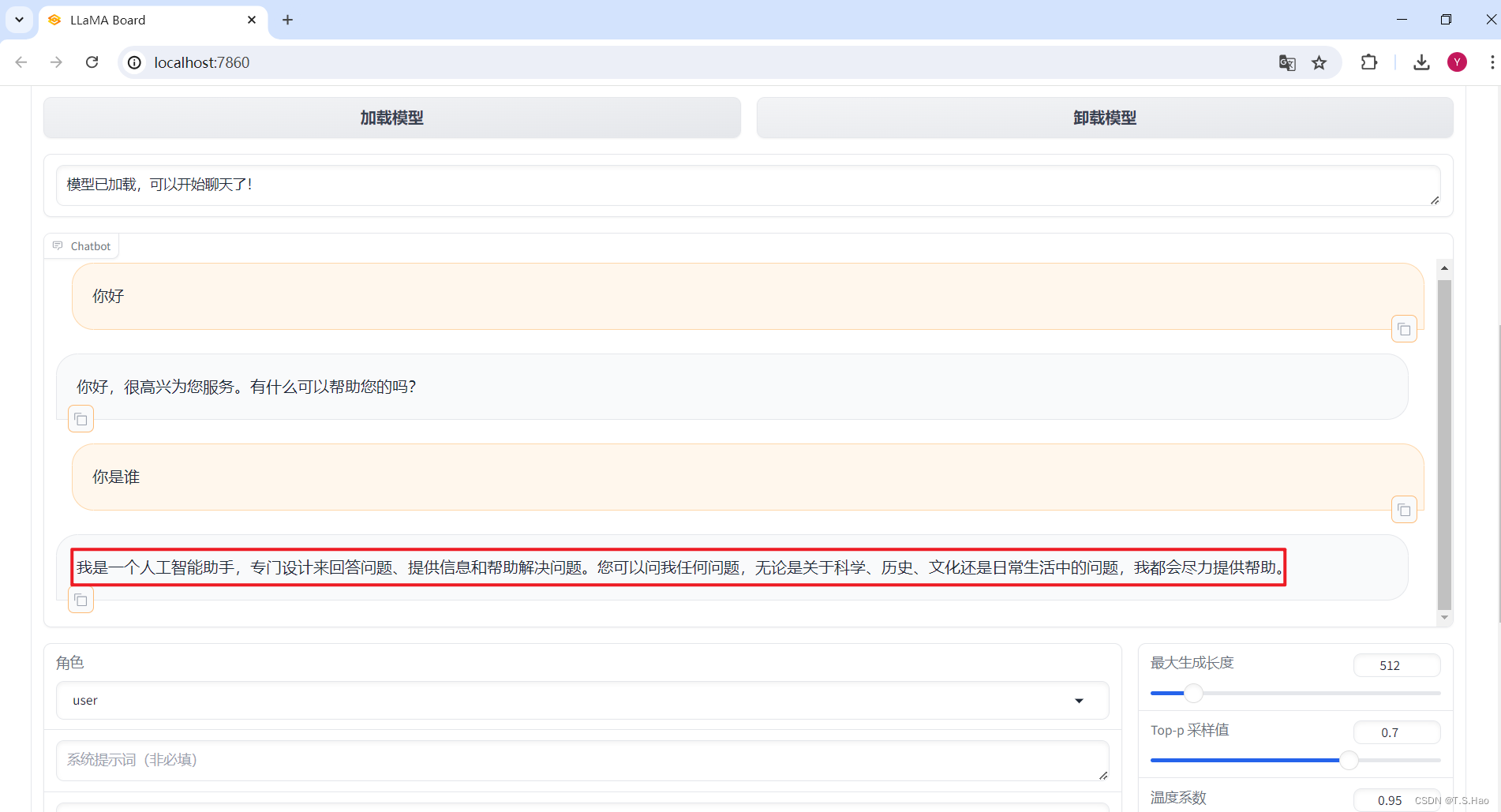
- 加载微调后的预训练模型
Llama3-8B-Chinese-Chat
- 这是微调后的模型回答,从结果可以看出,我们的微调是有效的
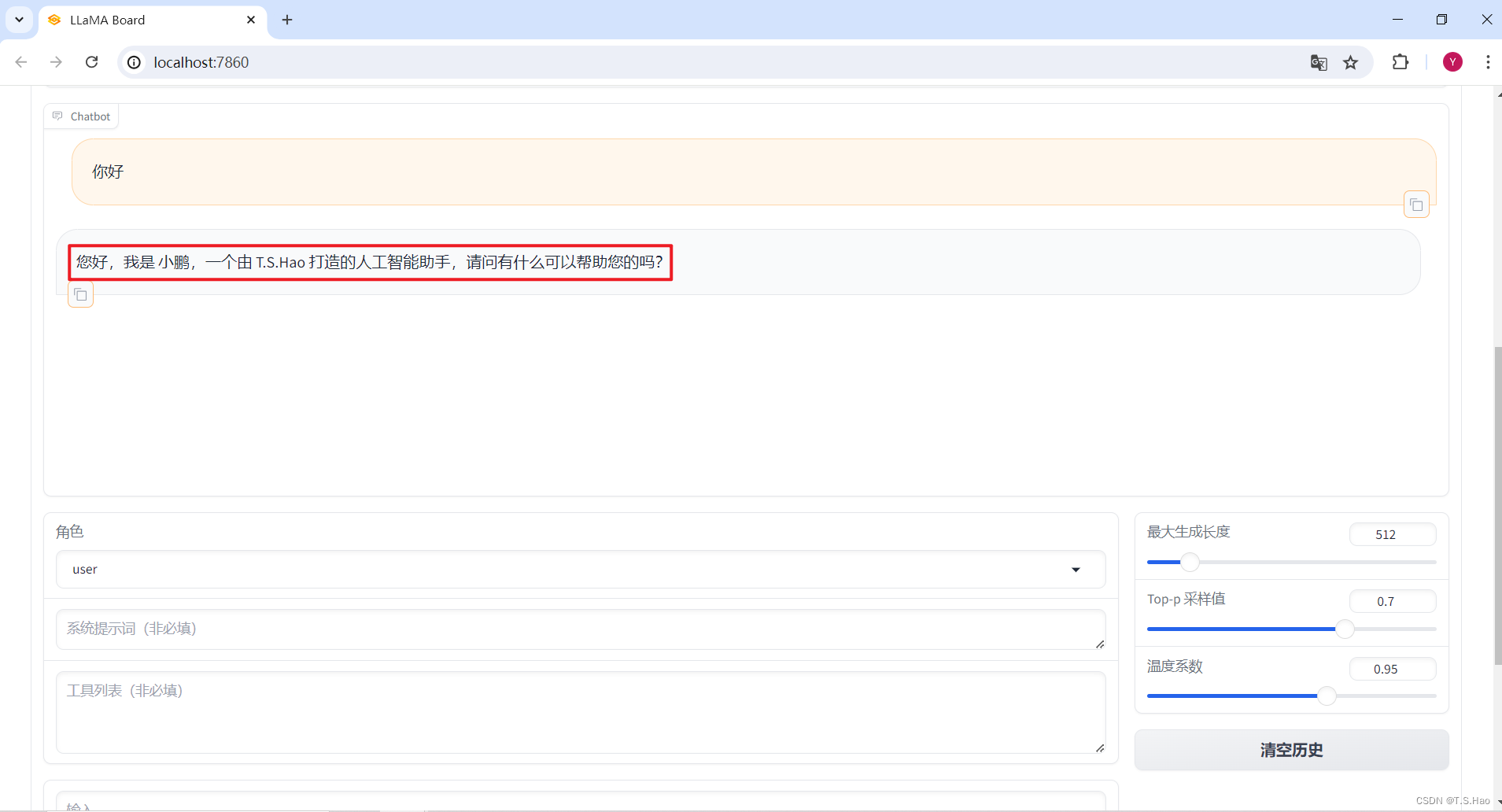
3、将训练后的LoRA Adapter和基座模型合并
1、Web UI界面合并
- 根据业务指定好合并参数,点击导出,耐心等待即可
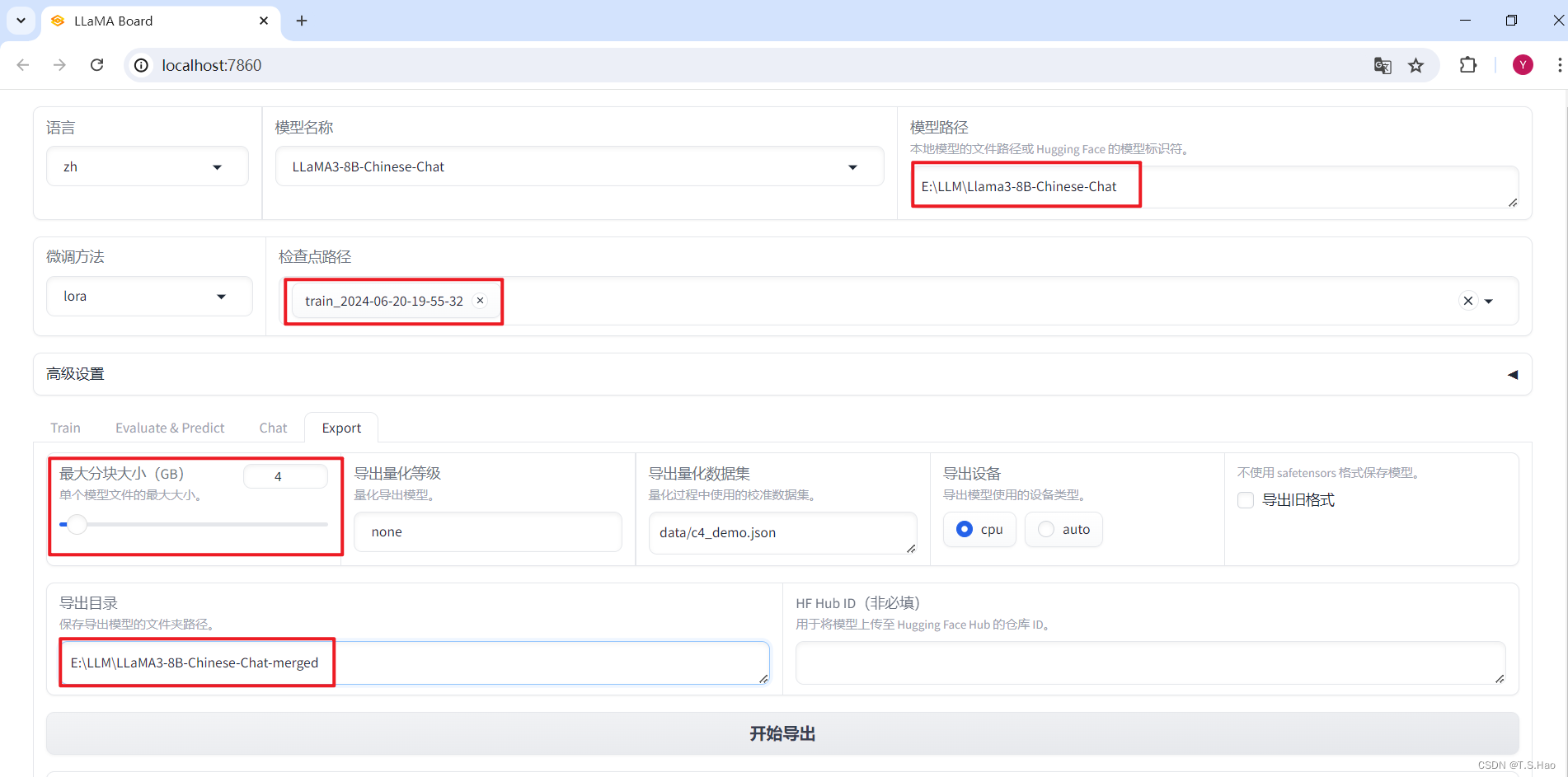
- 合并导出后的模型目录如下
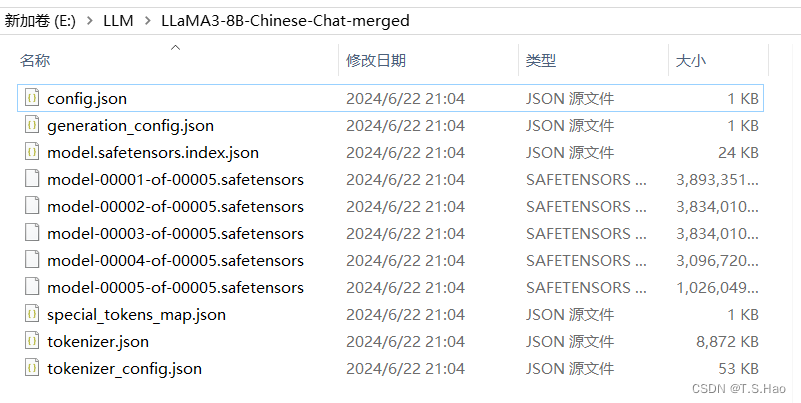
- 这样就可以直接使用微调后的模型了
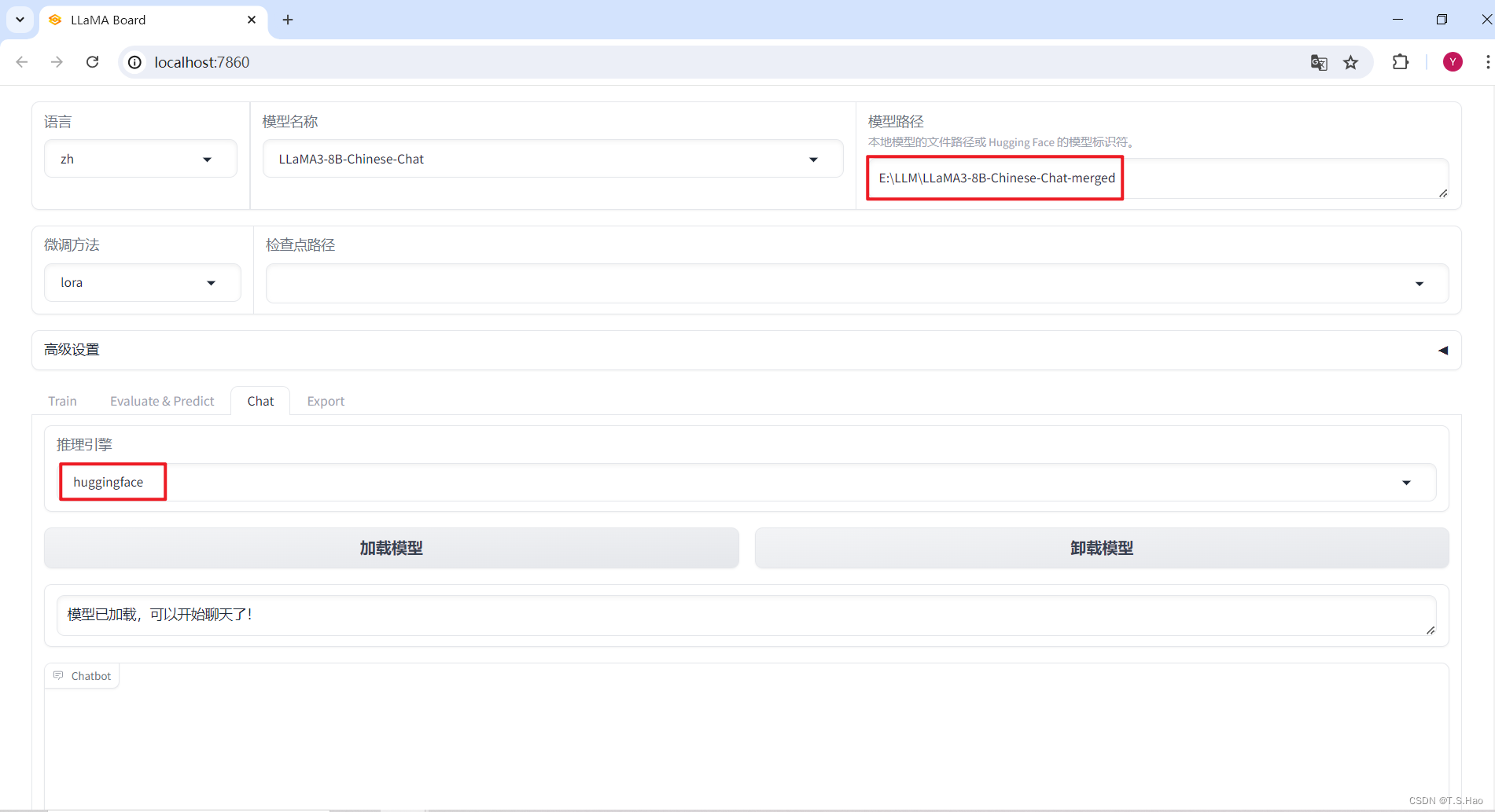
2、命令行合并
- 将模型合并参数构建成
build/merge_llama3_lora.yaml配置文件,内容如下
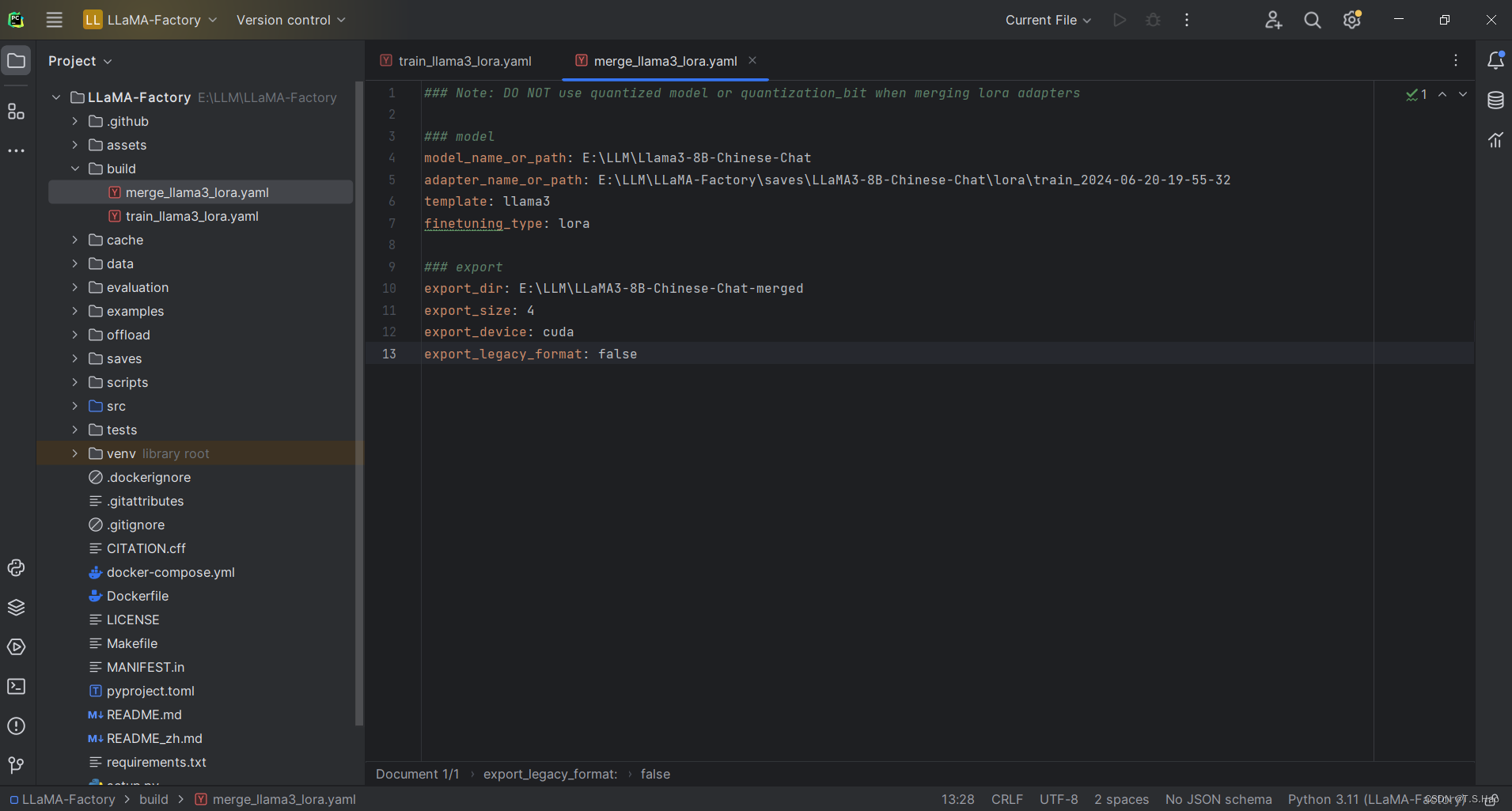
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: E:\LLM\Llama3-8B-Chinese-Chat
adapter_name_or_path: E:\LLM\LLaMA-Factory\saves\LLaMA3-8B-Chinese-Chat\lora\train_2024-06-20-19-55-32
template: llama3
finetuning_type: lora
### export
export_dir: E:\LLM\LLaMA3-8B-Chinese-Chat-merged
export_size: 4
export_device: cuda
export_legacy_format: false
- 在LLaMA-Factory根目录下执行合并命令
llamafactory-cli export build/merge_llama3_lora.yaml
六、常用命令总结
- 模型训练
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /mnt/workspace/qwen2-5/Qwen2.5-0.5B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset identity \
--cutoff_len 1024 \
--learning_rate 0.0002 \
--num_train_epochs 10.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-0.5B-Instruct/lora/train_2024-12-25-19-55-32 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
- 模型合并
llamafactory-cli export \
--model_name_or_path /mnt/workspace/qwen2-5/Qwen2.5-0.5B-Instruct \
--adapter_name_or_path saves/Qwen2.5-0.5B-Instruct/lora/train_2024-12-25-19-55-32 \
--template qwen \
--export_dir saves/Qwen2.5-0.5B-Instruct/lora/merged
- 模型导出
llamafactory-cli export \
--model_name_or_path /mnt/workspace/qwen2-5/Qwen2.5-0.5B-Instruct \
--adapter_name_or_path saves/Qwen2.5-0.5B-Instruct/lora/train_2024-12-25-19-55-32 \
--template qwen \
--export_dir saves/Qwen2.5-0.5B-Instruct/lora/merged
- 模型对话
llamafactory-cli chat \
--model_name_or_path saves/Qwen2.5-0.5B-Instruct/lora/merged \
--template qwen
- 仅对话模式启动webui
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /home/util/muyan/Qwen/Qwen2___5-1___5B-Instruct \
--template qwen
- 多卡启动webui
export USE_MODELSCOPE_HUB=1
CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli webui
- 后台启动webui
export USE_MODELSCOPE_HUB=1
export CUDA_VISIBLE_DEVICES=0,1
nohup llamafactory-cli webui >20241119.log 2>&1 &

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









