






所谓爬虫就是模拟浏览器对于服务器发送请求,通过代码去模拟浏览器来得到想要的结果。
爬虫代码基本实现的步骤是
1.发送请求,对于想要爬的视频网站的URL地址发送请求
2.获取数据,获取服务器返回的一个输出内容,一般长这样,有很多元素组成

3.解析数据,就是提取想要的数据内容,比如上面就是把弹幕的内容单独提取出来,而不要其他的数据。
4.保存数据,把获取下来的数据内容保存到txt文本里。
数据收集
发送请求
先导入一个模块
Import requests这是第三方模块,没下载的需要在终端install requests一下。
确定URL地址,就是你想要爬的视频地址,确定好cid
![]()
然后是headers的请求头,作用就是进行伪装,模拟浏览器发送请求
参数就是在开发者工具里面找到的,一般只要UA就可以了。
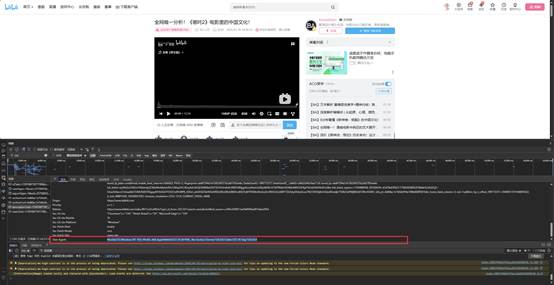
我这里是:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0
里面包含的是浏览器的一个基本信息,比如浏览器发送过来请求的什么版本,系统之类的。类似人类的身份证。
最后通过requests模块里面get请求方法,对于url地址发送请求,并且携带上headers请求头,再用response变量去接收返回数据
这一步的代码就是
import re
import requests
#headers请求头作用把Python代码进行伪装,模拟成浏览器去发送请求
#user-agent浏览器基本身份标识
# 需要先找到 `cid` 才能请求正确的弹幕 API
cid = "25750933691" # 这里的 `123456` 需要替换为真实的 `cid`
# B站弹幕 API
danmu_url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}"
# 正确的请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0",
"Referer": "https://www.bilibili.com/"
}
# 发送请求
response = requests.get(url=danmu_url, headers=headers)
#<Response[200]>response 对象200状态码 表示请求成功
response.encoding=response.apparent_encoding#这里进行转码,不然结果输出会有乱码获取数据
就直接把上面的内容打印出来即可
print(response.text)#可要可不要
解析数据
一般有三种解析方式
- re-正则表达式 对于字符串数据进行提取
- css和xpath主要根据标签属性/节点提取数据
我们上面获取的text文件是HTML的字符串数据,直接用re正则就可以了。
使用re.findall,有两个参数,一个是找什么东西,然后是从哪里去找,
查看弹幕地址

我们发现弹幕数据由两种组成,一个是用户的数据,一个是弹幕内容,我们要的是后者。
所以在re.findall里面我们模糊用户的数据就可以了,也就是泛匹配。
再用一个for循环逐个把弹幕打出来就可以了。
data_list= re.findall('<d p=".*?">(.*?)</d>',response.text)#.*?是通配符,正则表达式元字符可以匹配任意字符(除了换行符\n以外)

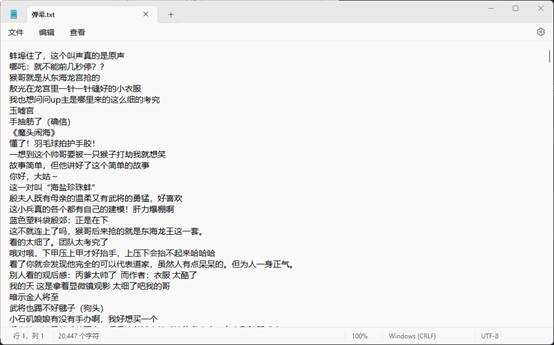
保存数据
写入保存到txt文件下
data_list= re.findall('<d p=".*?">(.*?)</d>',response.text)#.*?是通配符,正则表达式元字符可以匹配任意字符(除了换行符\n以外)
for index in data_list:
# mode 保存方式 encoding 编码
with open('弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(index + '\n')
print(index)
分析数据
获取数据后,就可以进行分析了
首先是准备
import jieba # 结巴分词 pip install jieba
import wordcloud #词云图 pip install wordcloud
import imageio # 读取本地图片修改词云图形pip install imageio读取数据弹幕
f = open('弹幕.txt',encoding='utf-8')
text = f.read()
#print(text)分词,把弹幕分割成词语
text_list=jieba.lcut(text)
print(text_list)
我们做词云图要用到字符串数据,所以我们还要把列表转成字符串,用列表的话数据会报错
text_str = ' '.join(text_list)
词云图配置
wc = wordcloud.WordCloud(
width=500,# 宽度
height=500,#高度
background_color='white',
font_path='msyh.ttc'#字体文件
)#背景颜色
wc.generate(text_str)#传入文字信息
wc.to_file('词云.png')
但是还是有很多无效的词,比如‘吧’ ‘了’之类的
再加入一个stopwords
stopwords={'了','吧'}
修改词云图形
配置
加入png图片进配置文件夹,再加两行代码
img = imageio.imread('红心.png')
mask=img即可

源代码
import re
import requests
#headers请求头作用把Python代码进行伪装,模拟成浏览器去发送请求
#user-agent浏览器基本身份标识
# 需要先找到 `cid` 才能请求正确的弹幕 API
cid = "25750933691" # 这里的 `123456` 需要替换为真实的 `cid`
# B站弹幕 API
danmu_url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}"
# 正确的请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0",
"Referer": "https://www.bilibili.com/"
}
# 发送请求
response = requests.get(url=danmu_url, headers=headers)
#<Response[200]>response 对象200状态码 表示请求成功
response.encoding=response.apparent_encoding#这里进行转码,不然结果输出会有乱码
data_list= re.findall('<d p=".*?">(.*?)</d>',response.text)#.*?是通配符,正则表达式元字符可以匹配任意字符(除了换行符\n以外)
for index in data_list:
# mode 保存方式 encoding 编码
with open('弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(index + '\n')
print(index)
import jieba # 结巴分词 pip install jieba
import wordcloud #词云图 pip install wordcloud
import imageio # 读取本地图片修改词云图形
img = imageio.imread('红心.png')
#1.读取弹幕数据
f = open('弹幕.txt',encoding='utf-8')
text = f.read()
#print(text)
#2,分词,把一句话分割成很多词汇
text_list=jieba.lcut(text)
print(text_list)
#列表转成字符串
text_str = ' ' .join(text_list)
print(text_str)
#3.词云图配置
wc = wordcloud.WordCloud(
width=500,# 宽度
height=500,#高度
stopwords={'了','吧','啊','哈','的','啊啊啊','哈哈哈','哇','都','都是','这','一幕','嗯','你','你是'},
background_color='white',#背景颜色
mask=img,
font_path='msyh.tth'#字体文件
)
wc.generate(text_str)#传入文字信息
wc.to_file('词云.png')

















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









